


Agents get better when they learn from interactions over time. But in production, “learning” can’t be a best-effort feature that lives inside a prompt window; it has to be durable, governed, and available even when real systems fail.
Our earlier post on resilient GenAI and agentic apps with intelligent memory made that case in principle.
This follow-up is about a concrete way to do that in production: Memori Labs as the memory layer, backed by CockroachDB as the durable system of record. Memori supports CockroachDB as a Postgres-compatible backend (and ships an example to try it).
And there’s one specific benefit worth calling out because it’s where a lot of teams feel pain first: this integration helps keep context alive without constantly re-sending it in the prompt, which can make answers faster and reduce token waste (and therefore cost) over time.
Why “memory” becomes a production problem fast
A surprising number of GenAI projects don’t stall because the model isn’t smart enough—they stall because the surrounding architecture can’t reliably provide the right context, consistently, at scale.
Studies on AI integration found that 70% of organizations operate on legacy systems, and 50% of AI initiatives fail due to integration issues with outdated architecture. It also notes 78% of firms are unprepared for RAG/agentic AI deployment due to poor data readiness, and 87% of enterprises have GenAI in pilot or early stages.
Those aren’t abstract stats; they show up as very real engineering issues:
Conversations and workflows get long
Tool outputs can be huge
Teams store more and more history into the prompt
Summaries become summaries of summaries
Guardrails pile up to compensate for messy state
Result: Latency climbs, token usage climbs, and reliability gets worse because the “state” only exists inside a prompt window.
This is why the core loop for scalable GenAI systems has three parts: Access Knowledge, Take Action, and Learn Over Time — with “learn over time” explicitly tied to durable, governed storage.
Where Memori fits: Turning interactions into usable memory
Memori’s goal is to make “memory” a first-class layer rather than an afterthought. In practice, that means capturing interactions and turning them into memory that’s useful for future steps:
Structured: facts and events you can query, govern, and audit
Semantic: embeddings that let you recall relevant context by meaning
From Memori’s own materials, the project emphasizes a SQL-native approach, vectorized memories, and a datastore-agnostic adapter model. (GitHub)
The key point isn’t “yet another framework.” It’s this: your agent shouldn’t have to re-derive everything from a raw transcript every time. It should be able to retrieve the small set of relevant facts and experiences that actually matter for the next decision.
Where CockroachDB fits: Durable, global storage for memory (and app state)
Once you decide memory matters, you run into a second reality: memory data grows quickly, and it needs to be reliable.
The technical blog on CSPANN, CockroachDB’s distributed vector index highlights one of the most overlooked scaling issues: embeddings can balloon storage. Embeddings can be a few kilobytes each (e.g., 1536 for OpenAI embeddings, 768 for Sentence-BERT), so at millions of vectors the index grows quickly—and the bigger cost is often the CPU and memory needed to scan those full vectors during search. CockroachDB’s C-SPANN reduces this overhead by storing a highly compressed form of vectors in the index (often shrinking index size by ~94%, e.g., from ~3 KB to ~200 bytes) and then using the original vectors only to refine the final results.
So memory is not just a “chat log.” It’s a mix of:
OLTP-shaped data (events, preferences, decisions, tool calls)
semi-structured data (often JSON)
vector data (embeddings for semantic recall)
CockroachDB is built for operational reliability when your app is global. CockroachDB is a single logical database that’s distributed and can be scaled across the globe supporting location-based data pinning, which matters when memory includes user-specific information subject to residency or regulatory constraints. It also eliminates the need to add another database solution to your stack since it delivers vector store capabilities, so you can consolidate your operational and AI data.
And importantly for Memori: CockroachDB supports the PostgreSQL wire protocol, which makes it practical to plug into Postgres-oriented tooling and drivers.
CockroachDB is agent-ready: The Managed MCP Server
Durable memory is one piece of the puzzle. However, agents are increasingly interacting with databases directly by exploring schemas, diagnosing slow queries, and reasoning about data. That means the database itself needs to be designed for agent-driven workflows, not just human ones.
This is why CockroachDB Cloud now includes a fully managed MCP (Model Context Protocol) server: a secure, hosted endpoint that lets AI tools like Claude Code, Cursor, GitHub Copilot, and others interact directly with your CockroachDB clusters. There's no infrastructure to deploy or maintain; a configuration snippet from the Cloud Console connects your agent in minutes. The server exposes tools for listing databases and tables, describing schemas, running read-only SQL, and inspecting query plans via EXPLAIN, all through the Model Context Protocol standard. Read-only mode is on by default, with write access gated behind explicit consent, so agents can explore freely without the risk of unintended modifications.
Security is layered: the managed MCP server supports OAuth 2.1 for interactive developer workflows (with read/write consent scoping and Cloud RBAC) and service account API keys for fully autonomous agent pipelines. Every request is authenticated, authorized, and traceable, so the same governance guarantees that make CockroachDB the right choice for durable agent memory also apply to the agent interaction surface itself.
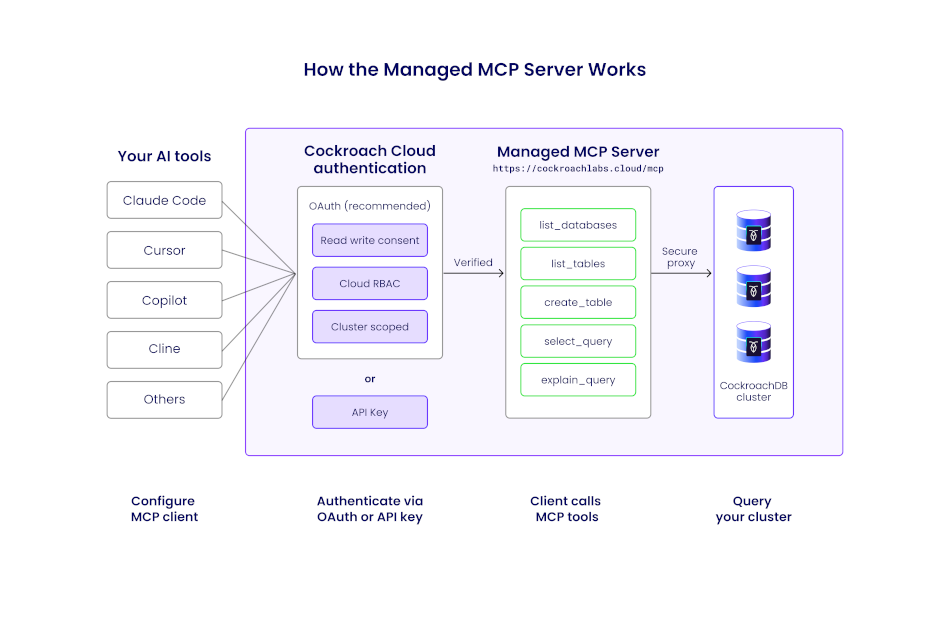
Managed MCP request flow illustrates how an AI agent interacts with CockroachDB Cloud through the managed MCP endpoint, without introducing a new data-plane access path.
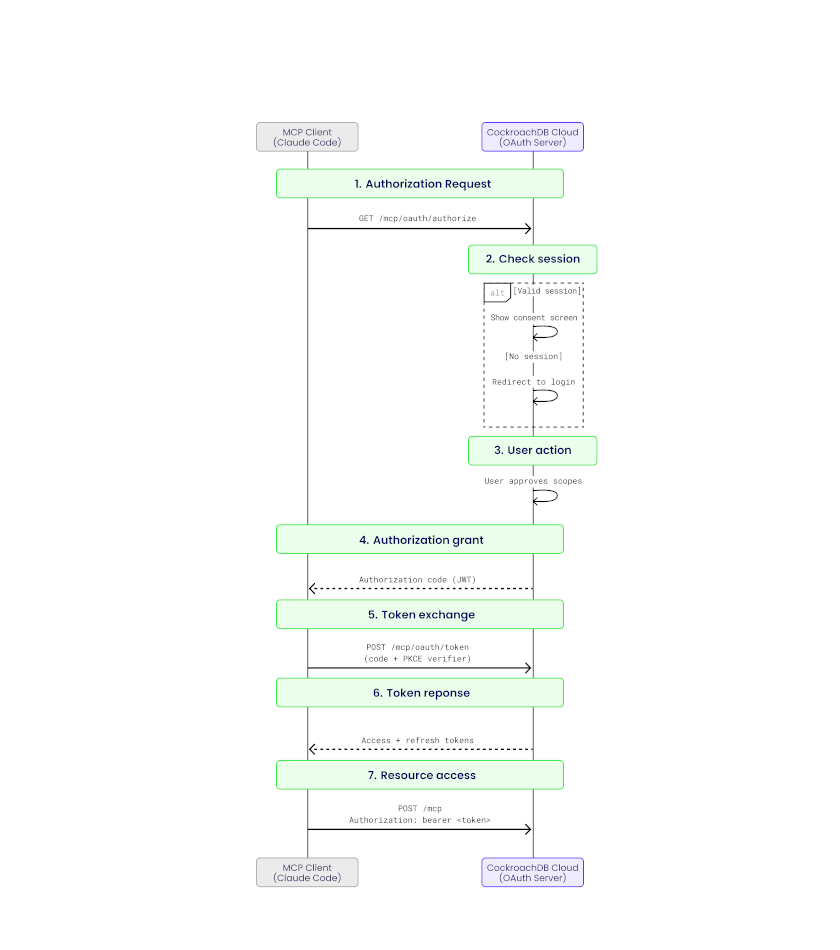
Authentication and authorization layering shows how multiple security controls compose to protect clusters from unintended access.
The takeaway: CockroachDB isn't just a backend for storing what agents learn, it's becoming a database that agents can operate directly, safely, and at scale. Whether your agents are persisting memory with Memori Labs or querying schemas during a coding session, CockroachDB is built for both sides of the AI-agent equation.
Why CockroachDB and Memori Labs: keep context alive without bloating prompts
Memori decides what to remember and how to recall it; CockroachDB makes that memory durable, queryable, and available wherever your application runs.
But the most “felt” benefit for teams building agentic apps is this:
You stop paying to re-send your own history
A lot of early agent implementations quietly turn into prompt-packing machines:
append conversation history
append tool outputs
append summaries of summaries
append more guardrails to compensate for the mess
That approach works… until it doesn’t. It increases latency, makes outputs less predictable, and burn
With Memori + CockroachDB, you can treat context differently:
Persist context as memory (structured + semantic) instead of carrying it forward in the prompt forever. (GitHub)
Retrieve only what’s relevant for the current question or step, and inject a compact set of memories into the prompt.
Keep the prompt lean, and let the database do what it’s good at: storing, indexing, and retrieving.
This is the practical meaning of “keep context alive.” The context survives across sessions and failures because it’s stored durably (“learn over time” using durable, governed storage). And because you’re retrieving targeted memory rather than re-sending everything, you reduce token waste—often translating into lower ongoing cost and faster responses (especially as conversations and workflows get longer).
A useful mental model:
Prompts are for immediate reasoning.
Memory is for durable knowledge.
“Smarter” and “faster” comes from better retrieval, not bigger prompts
When memory is queryable, your application can do more than "remember the last 20 messages”. It can recall:
the user’s stable preferences
prior decisions and approvals
key events that happened weeks ago
summaries of tool outputs without pasting the full output again
semantically similar past situations (“this looks like that incident from last month”)
This is where vector search matters. CockroachDB supports in-database vector search patterns like L2 distance and cosine similarity.
As vector data grows, indexing becomes the difference between “neat demo” and “production feature.” One approach described for scaling vector retrieval is a distributed index based on a hierarchical K-means partitioning tree (C-SPANN), which narrows the search space by clustering vectors into partitions with centroids.
In plain terms: as your memory dataset grows, you need retrieval that keeps working—without heroic tuning or fragile pipelines.
Durable memory also improves governance and auditability
Agent systems don’t just “answer questions.” They take action. That means you often need:
decision logs (“why did the agent do that”)
replayable workflows
access controls and tenant isolation
data locality controls
The goal is to build systems that are scalable and resilient for real-world usage.
In practice, using a durable SQL store for memory makes it easier to apply the same governance patterns you already use for application data—schema, access controls, retention policies, and auditing—rather than bolting governance onto a separate memory silo.
How to try out CockroachDB + Memori Labs
Memori has documentation for PostgreSQL-compatible backends including CockroachDB, and it notes that these backends use psycopg and support Memori features like augmentation, and vector search.
There’s also a CockroachDB example in the Memori repo you can use as a starting point.
So rather than repeating the technical steps here, the intent of this post is to help you choose the architecture: store durable memory in CockroachDB, and use Memori Labs to turn that data into the right context at the right time.
When CockroachDB + Memori Labs is especially useful
Memori + CockroachDB is particularly compelling when you’re building:
Long-lived assistants where “forgetting” context breaks the product (support, sales, onboarding copilots)
Multi-agent workflows where multiple agents need shared state and consistent memory
Global apps where users expect consistent experiences across regions (and you can’t afford memory tied to a single failure domain)
Cost-sensitive systems where token usage creeps up as soon as you ship and users create real history
If your agent’s “memory” lives only inside prompts, it’s not really memory—it’s expensive context juggling.
Memori Labs + CockroachDB gives you a path to make memory durable and useful: Memori structures and retrieves it; CockroachDB keeps it resilient, consistent, and scalable as it grows.
Try CockroachDB Today
Spin up your first CockroachDB Cloud cluster in minutes. Start with $400 in free credits. Or get a free 30-day trial of CockroachDB Enterprise on self-hosted environments.
Harsh Shah is Senior Staff Solutions Engineer on the Partner Engineering team at Cockroach Labs, where he helps partners design and deploy CockroachDB at scale. His career in distributed systems spans from distributed file systems at Cloudera and Hortonworks to distributed SQL databases at Cockroach Labs, giving him a deep appreciation for the infrastructure decisions that make or break production workloads.


