


This article originally appeared on the personal blog of Kiki Carter. Kiki is Senior Manager, AI & Platform Engineering for Cockroach Labs.
Building agentic applications means you’re deliberately inviting non-determinism into your system. AI agents’ creativity and adaptability is super powerful, but it’s also dangerous if your data layer isn’t rock solid. The more flexible the top of your stack becomes, the stronger the foundation underneath has to be. This principle is what led me to anchor my agentic stack in CockroachDB.
I’ve been working closely with Gen AI for a few years now. If you’ve been following along, you’ll recall I first used Gen AI as a partner in deconstructing data and ideas in my creative process (I wrote more about that here).
When OpenAI introduced the API, I began using ChatGPT programmatically. Then came “Functions/Tools,” which expanded my programmatic use (I talk about that here). Finally, Model Context Protocol arrived, giving LLMs an entirely new level of power. (A bit on my first app re-imagined as agentic here).
As the ecosystem evolved, so did my approach to building applications with LLMs. At first, my projects didn’t need persistence. But soon enough, data became central to my functionality, and that shift changed major elements in my stack.
From zero to 100 on persistence
My first AI app was simple: a report generator that gathered system details, sent them as a formatted prompt, and had the LLM create a detailed report and actionable analysis. That didn’t require much tech: Node/Express, some HTML and CSS, the OpenAI API, and voila! No persistent data, no complex stack.
But that phase didn’t last long.
As my apps grew more complex, data stopped being incidental and became more central to my functionality. Apps weren’t just calling LLM APIs, agents were managing state, working with metadata, and contextual data to make better decisions. I started to think more about how to give my agents more of the right context at the right time.
Eventually retrieval-augmented generation (RAG) entered the picture: I wanted agents to surface relevant context on demand, not just query a database.
And that brought me to the next stage.
Evolving without introducing unnecessary complexity
One of my approaches to RAG leveraged embeddings, which to me meant a vector database. So I reached for Pinecone while still leaning on CockroachDB for relational data. Initially, it looked like success to me! I was so caught up in the novelty of my app’s new superpowers that I lost sight of classic principled architecture.
By using two different data stores, I had revived the notorious dual-write problem. Ugh! One piece of data lived in CockroachDB, its semantic twin lived in Pinecone, and my agents were managing both. Sometimes they succeeded. Sometimes they left things inconsistent, like updating a record in CockroachDB but leaving the embedding stale in Pinecone.
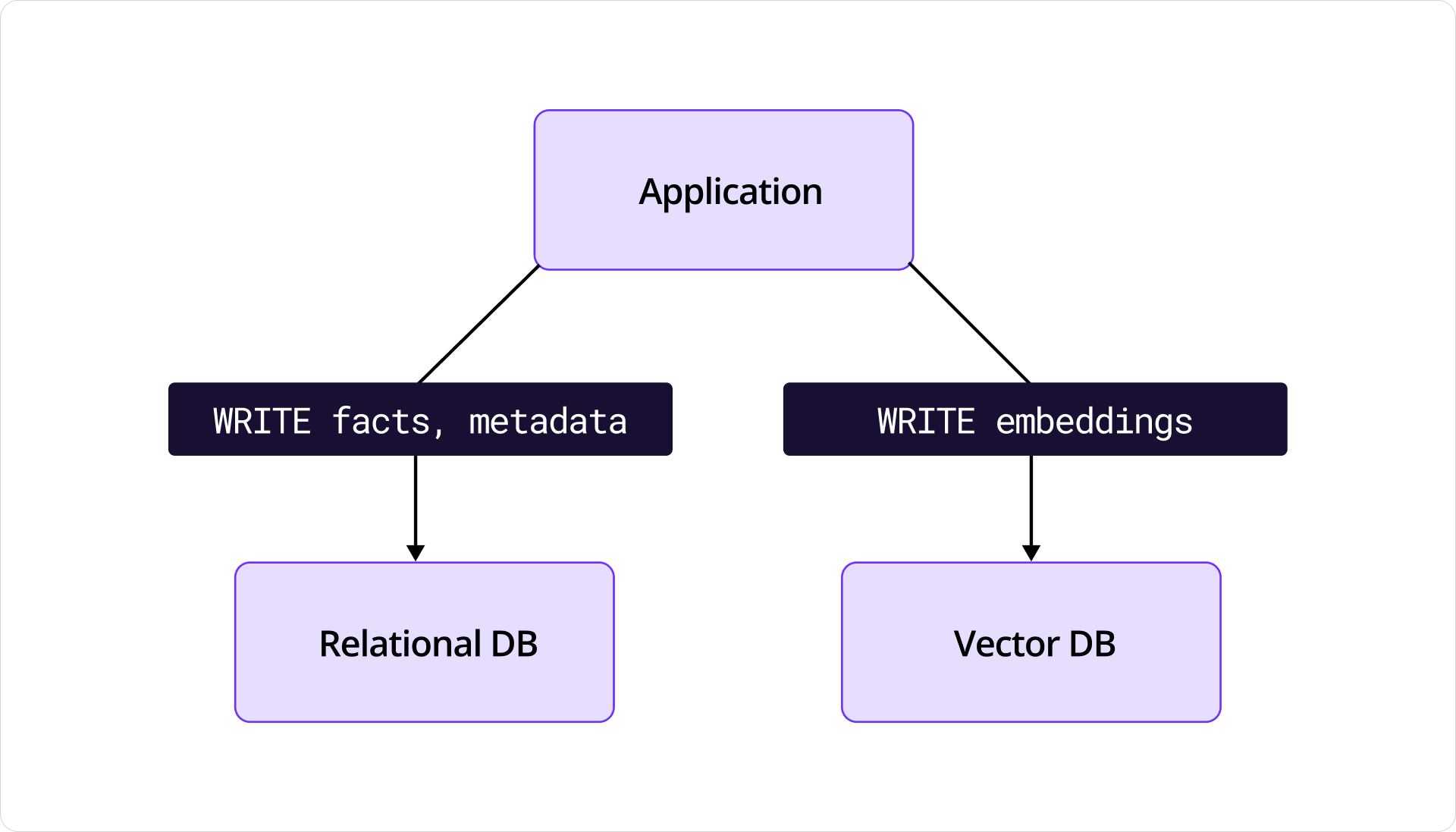
Diagram of an application performing dual-writes to two data stores.
It’s bad enough when you have hard-coded instructions performing dual-writes. But this new age “soft-coded” agent was amplifying risk. How quickly had I gone from a principled architect to a person asking non-deterministic agents to perform a dual-write?!
Thankfully I found myself and refined my approach.
The solution wasn’t to make agents more careful. Agent instructions and guardrails are a valid part of hardening your system. But I had to make a more fundamental change to strengthen the system. I decided to simplify the architecture itself. CockroachDB now supports vector embeddings, which meant I could co-locate both relational metadata and vector data in the same system. Of course, I acknowledge there are other ways to solve for dual-writes! This was the simplest way to completely avoid dual-writing in my solution.
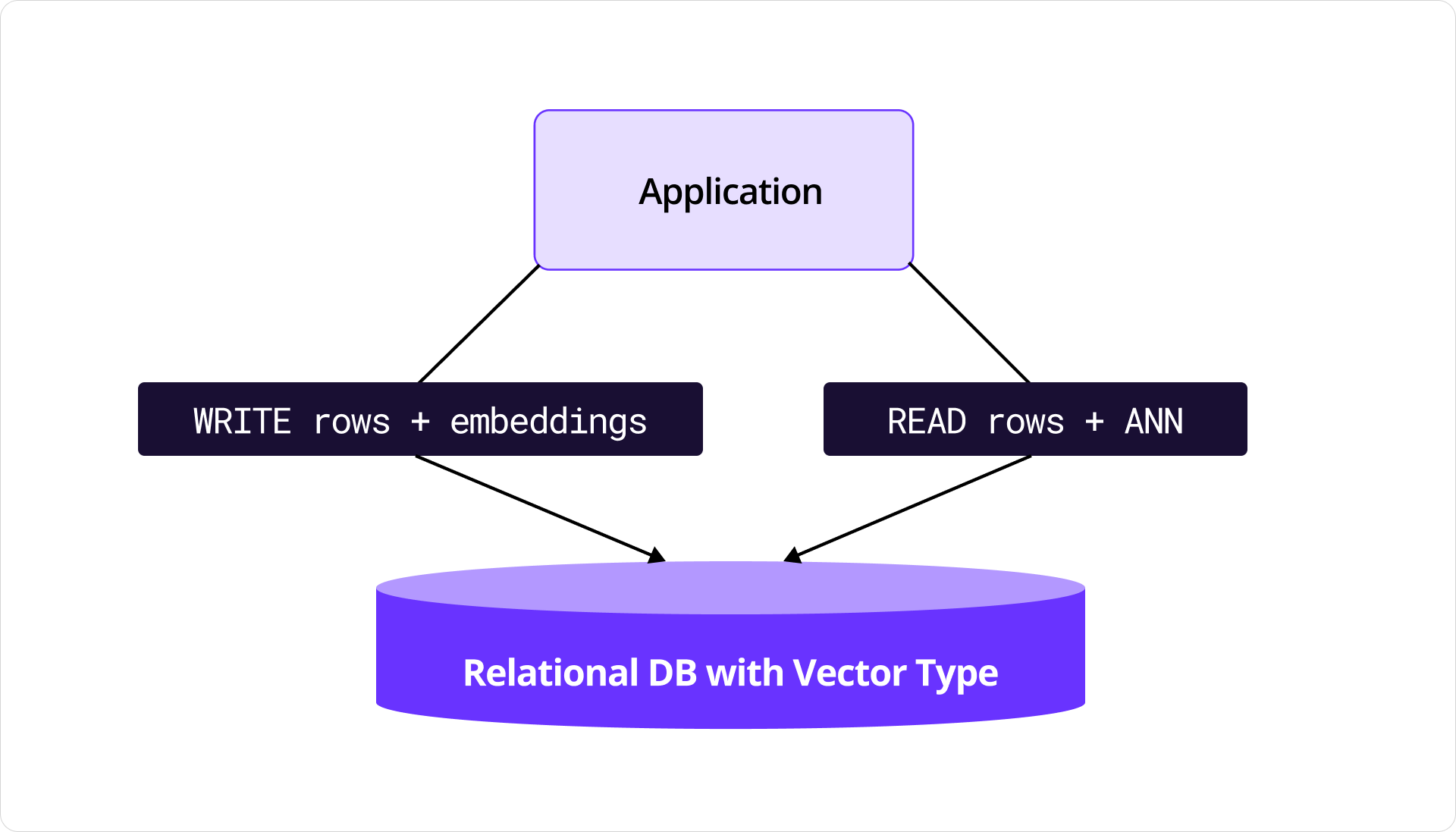
Diagram of an application performing writes and reads from a single source
For example: I could now design a system to store both support ticket metadata (customer, severity, etc) and embeddings of past tickets in CockroachDB. One query could return both related cases and the structured context for escalation. I could do this without dual writes and with other performance benefits, which I’ll dive into a little deeper in different material.
This simplification worked, but there was another foundational reason for using CockroachDB as my app’s DB.
Limiting non-determinism at the foundation
I glossed over this earlier, but the importance of CockroachDB’s consistent data principles can’t be overstated in the context of building agentic apps. Think about how CockroachDB handles concurrency and anomalies: By default, it uses serializable isolation. When you’re already introducing a degree of uncertainty by design in your stack, you can’t afford race conditions or corrupted states in your foundation.
In a weaker isolation model, two agents might interleave updates and leave a nonsense value like truefalse. With CockroachDB, one transaction wins cleanly, keeping the system correct. That stability matters when agents participate in state management. In my opinion it matters when introducing state to any system, but especially one where you have this extra area of non-determinism.
My takeaway
AI applications are new, fun, and powerful. But they also risk your user’s trust by introducing doubt. It doesn’t even have to be AI’s fault that a data anomaly occurred, especially if you’re using a database with lower levels of transaction isolation.
However, the user’s perception is everything and blaming AI for any off experience is just easy default behavior. You want to be able to infuse AI into your solutions without weakening or damaging the trust you’ve built with your customers. And since building agentic applications means embracing some uncertainty at the top of the stack, that only works if you eliminate uncertainty at the bottom.
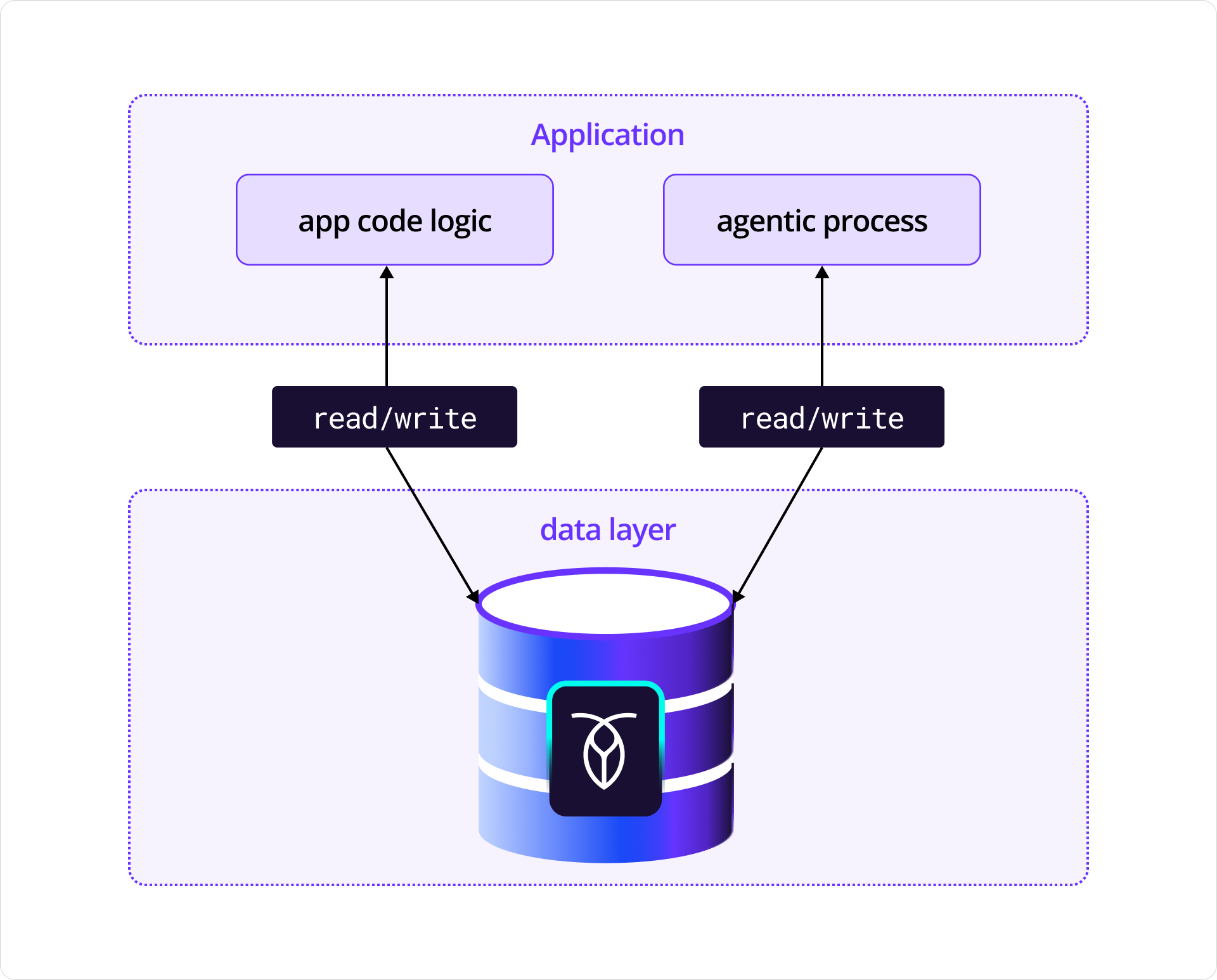
Diagram of application with code logic and agentic process both reading from and writing to CockroachDB.
If consistent data is critical to your application’s core function and you have agents that manage or rely on that data, a rock-solid data layer is just non-negotiable. For me, that’s what CockroachDB provides: strong data consistency, resilience across failures, and a simplified architecture for both relational and vector data.
Try CockroachDB Today
Spin up your first CockroachDB Cloud cluster in minutes. Start with $400 in free credits. Or get a free 30-day trial of CockroachDB Enterprise on self-hosted environments.
Kiki Carter is Senior Manager, AI & Platform Engineering for Cockroach Labs. In her four years at Cockroach Labs, she has developed curriculum, tooling, applications, and agentic workflows to accelerate CockroachDB Education, documentation and training.




