

In discussions of application architecture, the name Kafka comes up quite frequently. But if you haven’t worked with event-driven systems that rely on real-time data before, you might not be familiar with it.
So what exactly is Apache Kafka, and how is it used?
What is Apache Kafka?
Apache Kafka, which is often just called Kafka, is a distributed data store built for ingesting and processing streaming data in real time. Event-driven systems typically generate large amounts of data in real time, and Kafka makes working with this streaming data easier in several ways:
Allowing application services to publish and/or subscribe to data feeds
Storing the data accurately and sequentially (while remaining fault-tolerant and durable)
Processing data streams in real time
Kafka itself is open source and free, but a variety of vendors also offer Kafka-as-a-service products that may make implementation easier on particular clouds, add additional functionality, etc.
At a high level, though, here’s how standard Kafka works:
Data is sent to Kafka from producers (e.g., application services such as databases that are exporting real-time data in changefeeds). This data is stored in a Kafka cluster, where it is filtered into topics (user-configurable category groups that hold data from one or more producer streams in sequential order) and then into smaller subsets called partitions (the units that Kafka replicates and distributes for fault tolerance). Consumers, application services that want to access the data, can then subscribe to specific topics and receive a real-time feed of the relevant data.
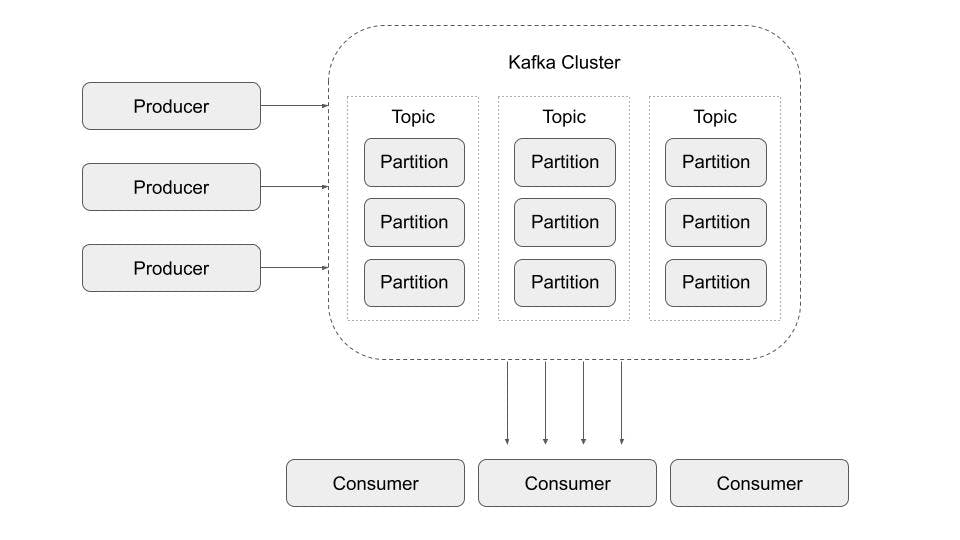
Because partitions are replicated and distributed, Kafka is resilient, scalable, and durable. It is also capable of very high throughput, capable of processing trillions of records per day without significant performance degradation. Because of these advantages, Kafka plays a role in the application architecture of many of the world’s largest companies, including Netflix, NuBank, and many more. In fact, Apache claims that 80% of Fortune 100 companies use Kafka.
What is it used for?
Typically, Kafka is used as part of a streaming data pipeline. While there are many ways it might be used, let’s walk through a hypothetical example that describes several typical use cases.
Imagine we have an online shopping application. One important stream of data for such an application would be customer use data (product pageviews, orders, etc.). This data is typically stored in a system-of-record database such as CockroachDB, which offers ironclad consistency as well as the resilience and scalability that’s needed to support the application’s mission-critical workloads.
This customer data is also important for analytics, and it may be used to inform other application services (e.g., a recommendation engine would need to analyze a customer’s viewing history and previous orders to make effective recommendations). However, having other application services and analysts querying CockroachDB directly isn’t ideal, as (for example) a poorly written analytics query could bog down the database, which would then affect application performance.
This is where Kafka comes in. Instead of querying the database directly, we’ll output a changefeed using CockroachDB’s CDC feature, which generates a real-time data stream of the customer data. Apache Kafka can ingest this stream, maintaining the sequential order that is critical for correctly understanding the transactions, and then serve it to the other services that require it, such as an analytics database and the recommendation engine.
Kafka thus allows all of these services to get access to the data they need in real-time without the application performance risks inherent in having them query the system-of-record CockroachDB database directly.
Example: Kafka in your application architecture
Below, we’ve illustrated the role Kafka plays in this sort of modern, distributed application architecture:
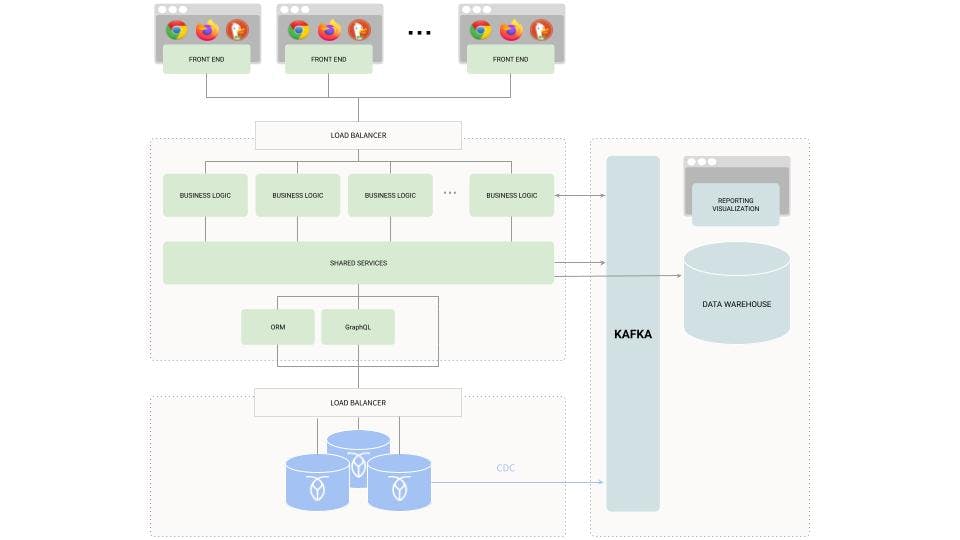
As you can see, Kafka is ingesting data from services and from the system-of-record database (producers), and providing real-time streams to consumers such as the data warehouse and various application services (i.e., the recommendation engine mentioned above).
How does Kafka work?
Kafka operates using a cluster of brokers (servers) with replicas of each partition distributed across the cluster to ensure resilience. Partitions are grouped into topics, and the data in each topic can be retained for a user-configurable period of time (seven days, by default). Data can also be stored in compacted topics, in which case Kafka will always retain the latest value for a specified key (ideal for data streams with keys whose values are updated frequently and for which only the latest value need be retained).
Users then interact with this distributed data storage system via its APIs.
The admin API is used to manage Kafka clusters, brokers, topics, and partitions.
The producer API allows producers to publish data streams to Kafka.
The consumer API allows application services to subscribe to topics (specific data streams).
The streams API allows applications to consume records from one topic, transform them as needed, and broadcast them to another topic.
The connector API allows developers to build reusable producers and consumers to simplify and/or automate adding data sources to Kafka.
Kafka thus allows developers a lot of flexibility to build customized, sophisticated event-streaming pipelines capable of serving whatever their application needs.
Kafka vs. RabbitMQ
Apache Kafka is often compared to popular message-queuing systems such as RabbitMQ, as the two do have similar functionality. A full comparison of all of the various differences is beyond the scope of this article, but one major difference between them is that Kafka uses a “pull” model while RabbitMQ uses a “push” model.
In its pull model, Kafka scores data for a prescribed period of time, and consumers can request (pull) the data from a specific offset (time period) whenever they want. Kafka will not send data until a consumer requests it.
In its push model, RabbitMQ immediately pushes incoming messages to consumers.
Another way to think about this difference is to say that Kafka uses a dumb broker/smart consumer model, in which the system trusts consumers to request the data they need, whereas RabbitMQ employs a smart broker/dumb consumer model that pushes all messages to the relevant consumers immediately.
Both approaches have advantages and disadvantages. One advantage of Kafka’s pull approach is that if a consumer service goes offline temporarily, it won’t miss data — it can simply request the relevant data when it comes back online.
Broadly, the conventional wisdom is that Kafka is the better choice for big data, high-throughput applications, while RabbitMQ is a good choice for systems that require low-latency message delivery. However, readers should carefully consider the specific needs of their application, now and in the future, before choosing the best option for them.
Why is Apache Kafka called Kafka?
At this point, hopefully we’ve covered the basics of what Kafka is and why you might want to use it. But there’s another common question we haven’t answered: why is it called Kafka?
Kafka was first developed at LinkedIn as part of a shift away from the monolithic application design pattern and towards an event-driven microservices architecture. The company realized it needed to realize a number of different data pipelines, so rather than building each individually, it built Kafka as a pub/sub service that could serve those needs, offering simple APIs that all of the new microservices could interact with.
When the company open-sourced the project in 2011, it needed a name, and creator Jay Kreps chose Kafka. When asked about the name on Quora, he wrote:
I thought that since Kafka was a system optimized for writing, using a writer’s name would make sense. I had taken a lot of lit classes in college and liked Franz Kafka. Plus the name sounded cool for an open source project.
So, there you have it. Perhaps it’s fate that the service was named after Kafka — an author whose famous works include a story about a man turning into a cockroach — since Apache Kafka works so well together with CockroachDB.


