

“Performance under Adversity” pressure testing proves most resilient database
For decades, database benchmarking has been stuck in the past. Industry-standard benchmarks like TPC-C – first approved 33 years ago, in 1992 – were designed to measure peak performance in pristine lab environments, isolated from the chaos of the real world. For example, they assume single datacenter deployments, ignoring the complexity of global applications and the global distribution of data. While they might include durability tests, they often do not explicitly measure performance during failures or maintenance, nor do they measure recovery time after failures. What they do show you is how a database behaves when nothing goes wrong. For example, once the steady-state run is disrupted (for example by a power pull) the test is considered over.
But nothing has ever stayed perfect in production.
Why we must re-evaluate database performance now
Modern applications are globally distributed, always-on, and increasingly complex. There are real world operations such as rolling upgrades, schema changes, and backups. There might be inconsistent storage access or complex network issues. While in the cloud, something fails all the time. Downtime, planned or unplanned, is no longer just a nuisance — it’s a multi-million dollar problem. Just ask CrowdStrike, FAA, Lloyds Banking Group, and the PlayStation Network, all of whom have suffered recent, very public outages.
In 2011, McKinsey predicted the era of big data, and since then we’ve seen an explosive growth in the amount of data we generate and how quickly that data is shared between both users and machines. The increasing use of AI and applications such as virtual agents, coupled with the increased complexity of interconnected systems only drives this growth higher. As a result, organizations are more vulnerable to disruptions such as cyberattacks, natural disasters, and outages from equipment failures.
Our “State of Resilience 2025” Report surveyed 1,000 senior technology leaders, and found that on average, organizations experience 86 outages each year, putting revenue and brand reputation at risk regularly. Even more telling: 79% of companies admit they aren’t ready to comply with emerging regulations surrounding operational resilience, like DORA and NIS2. Of the 95% of executives who acknowledged their operational vulnerability, almost half have yet to take action.
Today, organizations often rely on chaos engineering tools such as Chaos Monkey and Chaos Mesh to ensure applications are resilient in the face of changing, real-world conditions. However, most chaos engineering tools only target a single instance and do not simulate more complex failures such as loss of an entire availability zone (AZ) or region. They also only focus on a single point of failure and do not include impact to database performance. Knowing how to coordinate the use of these tools on a given infrastructure is critical to assess the impact of resilience on sustained performance.
So what if there was a database benchmark that could measure these resilience factors along with its impact to sustained performance?
Measuring what matters: Resilience, recovery, and sustained "Performance under Adversity"
For the last 10 years we have built CockroachDB with the core belief that performance isn’t about speed – it’s about survival. In fact, we believe resilience is the new performance metric.
That’s why we’ve released a novel methodology for benchmarking modern databases that tests the impact of real-world conditions faced by application and infrastructure teams every day. The shift from measuring peak performance allows us to measure how infrastructure performs under pressure.
Then, we show how CockroachDB responds to these conditions, preventing downtime, delivering business value and fast, consistent performance, and allowing teams to meet their overall TCO goals.
The metrics behind real-world testing
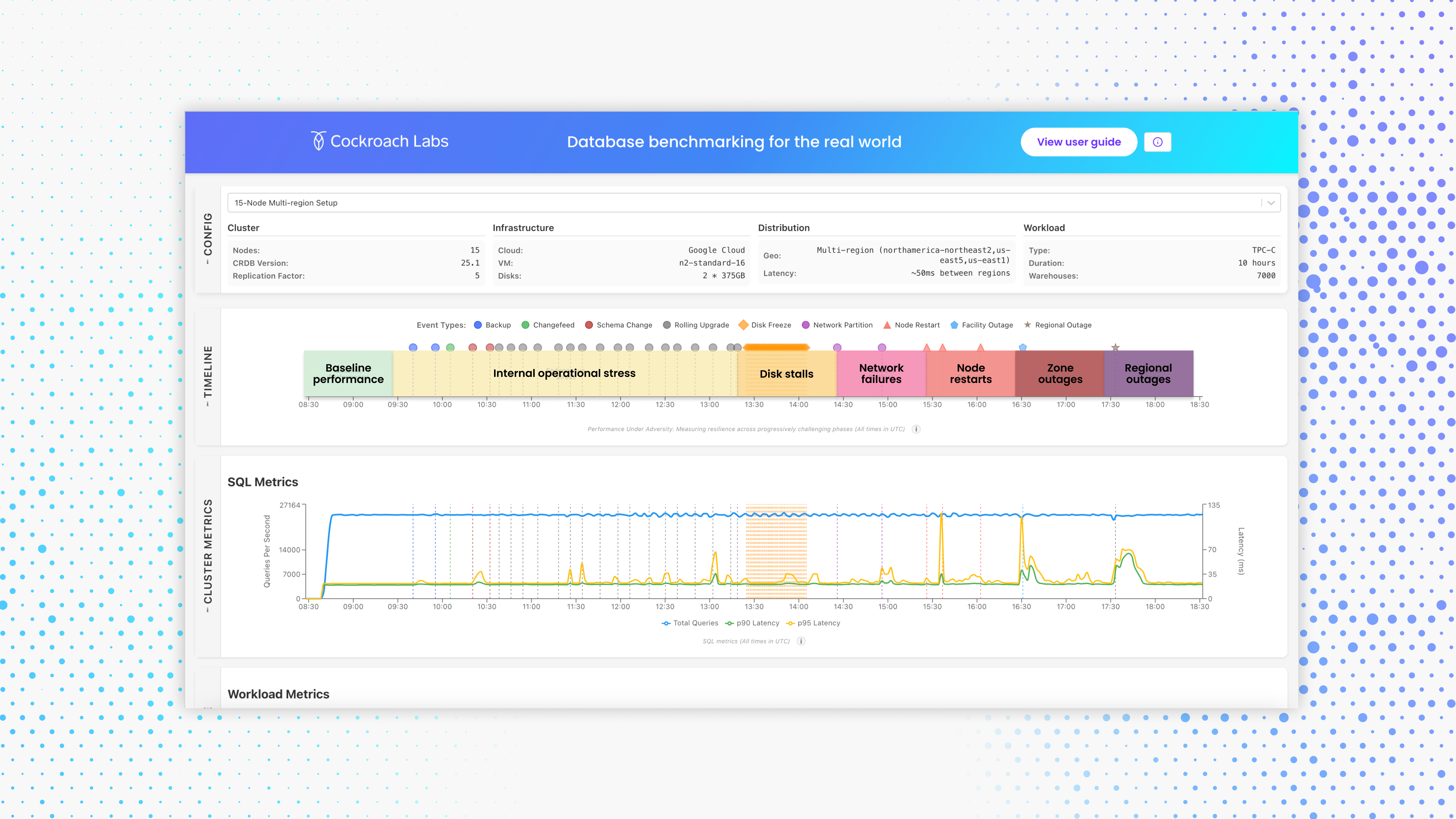
Database benchmarking for the real world interactive dashboard
Our new benchmarking methodology goes far beyond traditional metrics. It’s designed to answer the hard questions, like how your system behaves during rolling upgrades, node failures, or full data center outages.
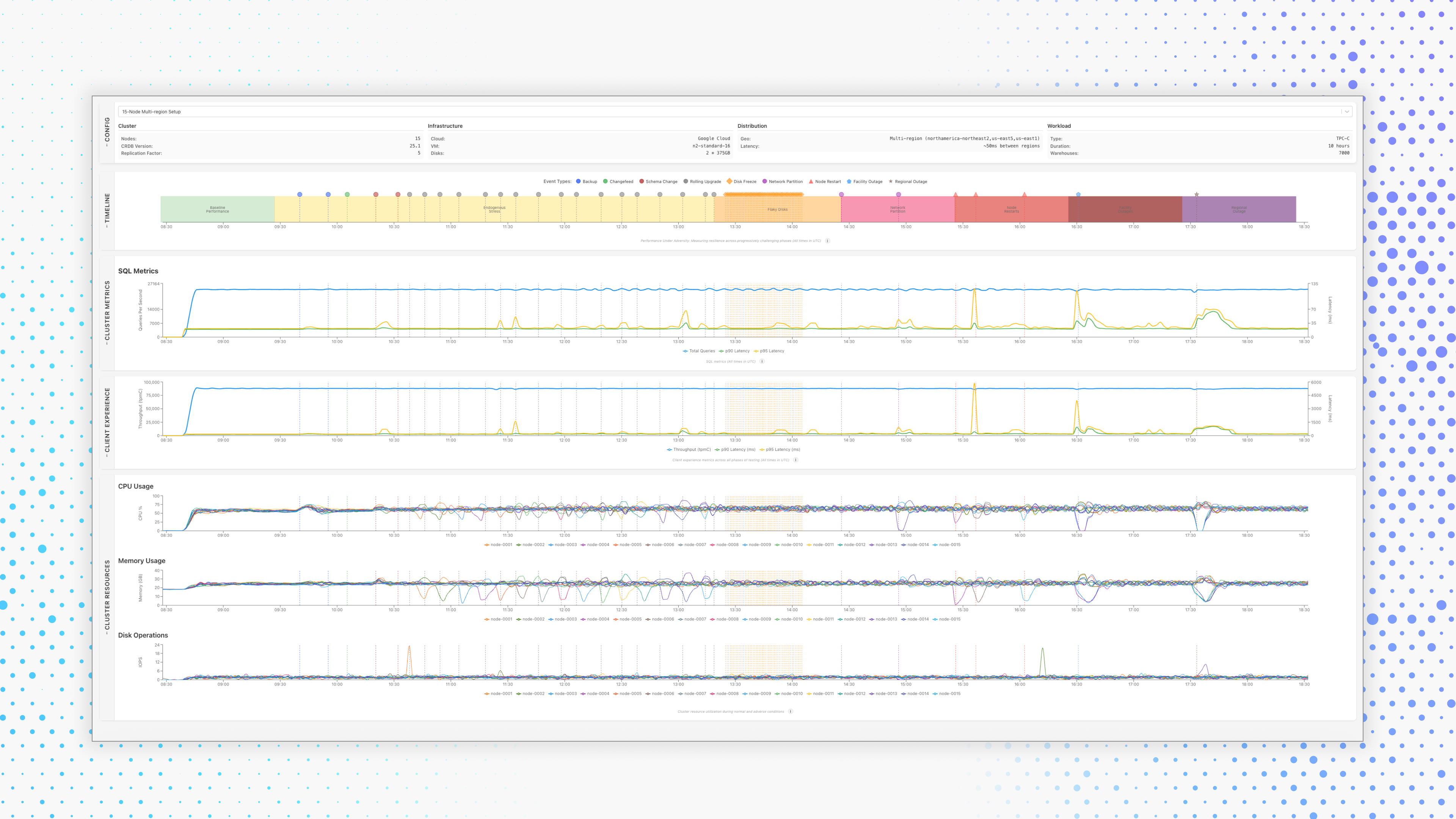
The benchmark includes seven escalating phases of adversity in a single continuous run, each one introducing progressively harsher failure conditions and operational stress. The metrics provide insight on impact to resilience and sustained performance.
Baseline Performance: Measure steady-state throughput under normal conditions.
Internal Operational Stress: Simulate resource-intensive operations such as change data capture, full backups, schema changes, and rolling upgrades.
Disk Stalls: Randomly inject I/O freezes to evaluate storage resilience.
Network Failures: Simulate partial and full network failures preventing one partition from communicating with nodes in another partition.
Node Restarts: Unpredictably reboot database nodes (1 at a time) to test recovery time and impact to performance.
Zone Outages: Take down an entire Availability Zone.
Regional Outages: Take down an entire Region.
Through all these phases, we measure throughput in transactions per minute (tpmC), latency (90th and 95 percentile), and recovery time to baseline.
The benchmarking dashboard: See resilience in action
These results aren’t just published. We’ve built a live, interactive dashboard that lets you:
Explore performance trends: View graphs of throughput and latency over time.
Replay failure scenarios: Dive into node restarts, flaky storage, and regional outages.
See resilience in action: Track CockroachDB’s self-healing in real time.
Now you can see how CockroachDB actually performs under the conditions your team cares about most.
Future-proof at scale and with lower TCO
By combining resilience and performance into a single database benchmark and testing methodology, organizations can future-proof their database infrastructure at scale and without risking their operational data. Using CockroachDB, teams can deploy applications with confidence, because we are sharing the receipts that enable us to deliver consistent performance and state-of-the-art resilience. In turn this means lower TCO for organizations because any downtime negatively affects performance, time to market, and cost. That doesn’t include the broader impacts of loss in customer trust and satisfaction, and damage to brand and reputation.
Reproducing the benchmark on CockroachDB
Like any robust benchmark, reproducibility is critical. We’ve made it easy to run the tests yourself. Our benchmarking methodology is fully documented and open. For our testing, we used version 25.1 of CockroachDB, distributed across three geographically separate regions, and ran automated tests to simulate failures like network partitions, disk stalls, and node restarts.
For architects, operators, and data leaders, this changes the game. You’re no longer left guessing how your database will behave during chaos. With “Performance under Adversity,” you get proof.
Proof that your apps will stay online. Proof that you can scale without sharding. Proof that you can survive and thrive under pressure.
Join us in setting a new standard for database performance.
Disclaimer: Results are from specific test setups. Try the dashboard yourself to see how it fits your needs.



