So you were worried about a failure, and it happened. Despite all of the planning, something went wrong, and now the goal is to minimize the impact of that failure. As part of our blog series, “Surviving Failures with CockroachDB,” this blog will cover what your options are when things inevitably fail. When the built-in high-availability options aren’t enough, use our disaster recovery tools to minimize your RPO and RTO, and ensure that your customers are back online as soon as possible.
If you’d like to learn more about how CockroachDB handles common application and database failures, or system-wide failures, check out the two prior posts in this series.
Disaster recovery with CockroachDB
But what happens when even these built-in failovers aren't enough? What if your entire cluster is lost due to a catastrophic disaster?
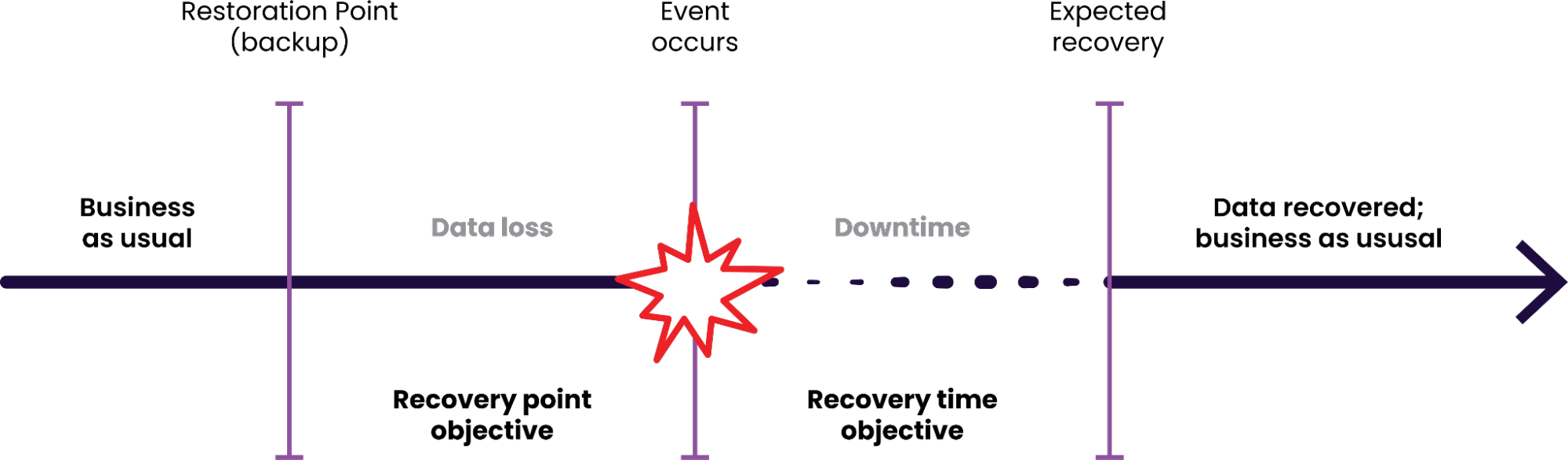
This is where CockroachDB’s disaster recovery (DR) tools come into play. Even in the face of complete cluster failure, CockroachDB provides mechanisms to help you recover data quickly, minimizing Recovery Point Objective (RPO) and Recovery Time Objective (RTO).
Let’s dive into what could bring down an entire CockroachDB cluster and how you can recover when HA alone isn’t enough.
What if a whole CockroachDB cluster goes down?
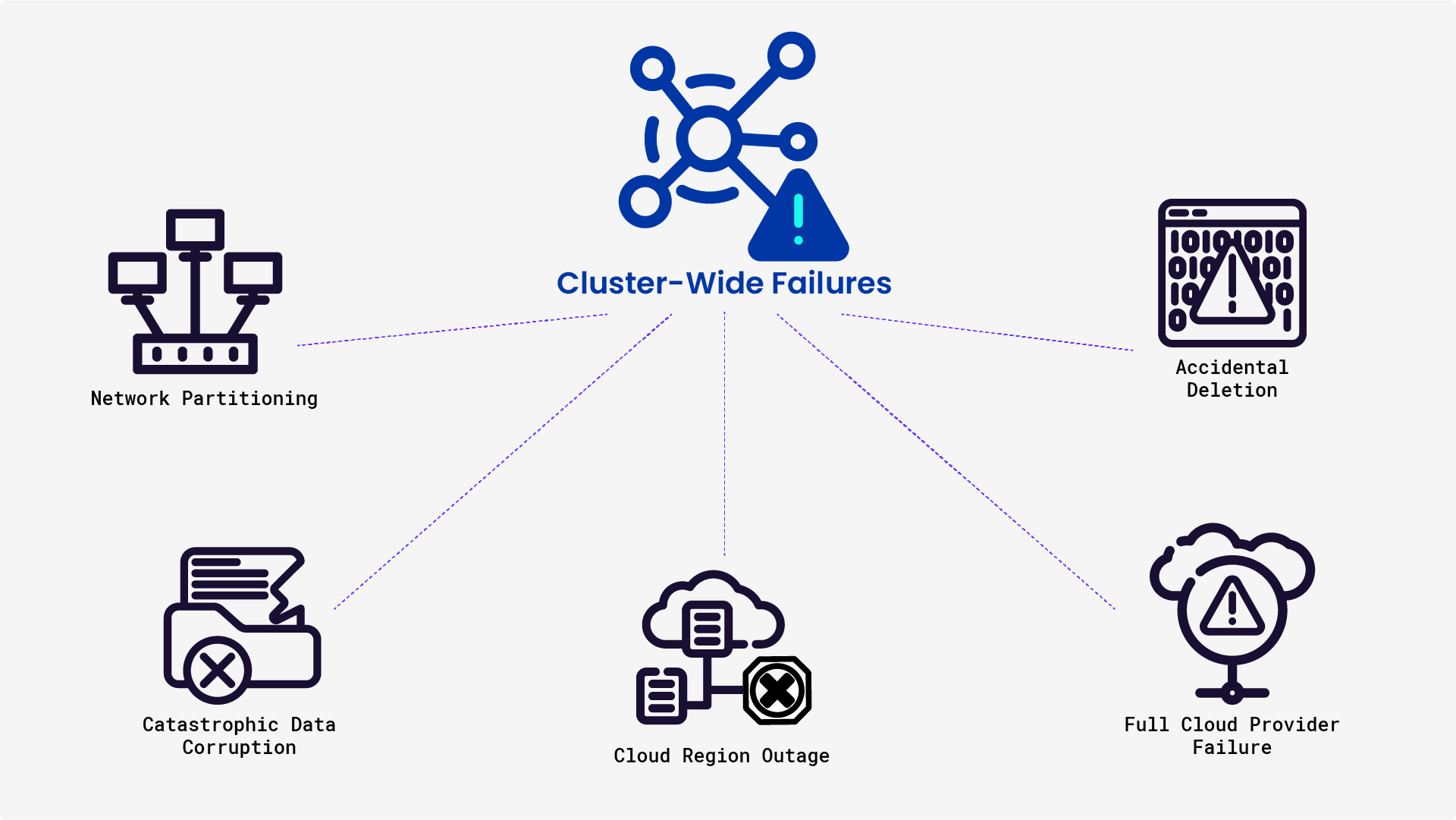
While CockroachDB’s distributed architecture is designed to survive most failures, there are extreme cases where an entire cluster could go down:
Cloud Region Outage – If your cluster is deployed in a single cloud region and that region experiences a total failure, your entire database could become unavailable.
Network Partitioning – If an extended network outage isolates nodes from each other for too long, it could lead to a loss of quorum and unavailability.
Catastrophic Data Corruption – If an operational error or malware corrupts data across the entire cluster, HA won’t help—it just replicates bad data.
Accidental Deletion – If someone mistakenly deletes a cluster or table (e.g., cloud infrastructure misconfiguration), HA won’t save you.
Full Cloud Provider Failure – If your database is entirely dependent on a single cloud provider, a failure at the provider level could mean total loss of access.
To recover from extreme failures, CockroachDB provides three key disaster recovery capabilities: backups, physical cluster replication, and logical data replication.
Backups: The Ultimate Safety Net
What it does:
Enables point-in-time recovery (PITR) by continuously backing up changes.
Allows restoration of data even if the original cluster is lost.
How it helps:
If an entire cluster is deleted or corrupted, you can restore a new cluster from a recent backup.
CockroachDB supports both full and incremental backups. Full backups are periodic snapshots of the entire database while incremental backups only capture changes since the last backup, reducing RPO.
Revision history backups allow you to roll back specific tables or the entire database to a point before corruption or accidental deletion.
Locality-aware backups ensure that backups are stored near where the data is used, reducing recovery time and egress costs.
Locality-restricted backups enable compliance with data sovereignty regulations, ensuring backups remain in specified regions (e.g., GDPR-compliant backups in the EU).
Cloud storage integration (AWS S3, GCS, Azure Blob) ensures backups are off-site and safe from failures affecting the primary cluster.
RPO & RTO Impact:
RPO: As low as the backup frequency (e.g., minutes with PITR).
RTO: The time required to provision a new cluster and restore from backup.
Check out the docs for more information on backup and restore.
RELATED
Watch this webinar with Cockroach Labs’ co-founder and CTO, Peter Mattis, in conversation with technical evangelist, Rob Reid, on “The Always-On Dilemma: Disaster Recovery vs. Inherent Resilience.” Learn how and why and how CockroachDB is moving beyond disaster recovery to disaster prevention and inherent resilience.
Physical Cluster Replication: Hot Standby for Instant Recovery
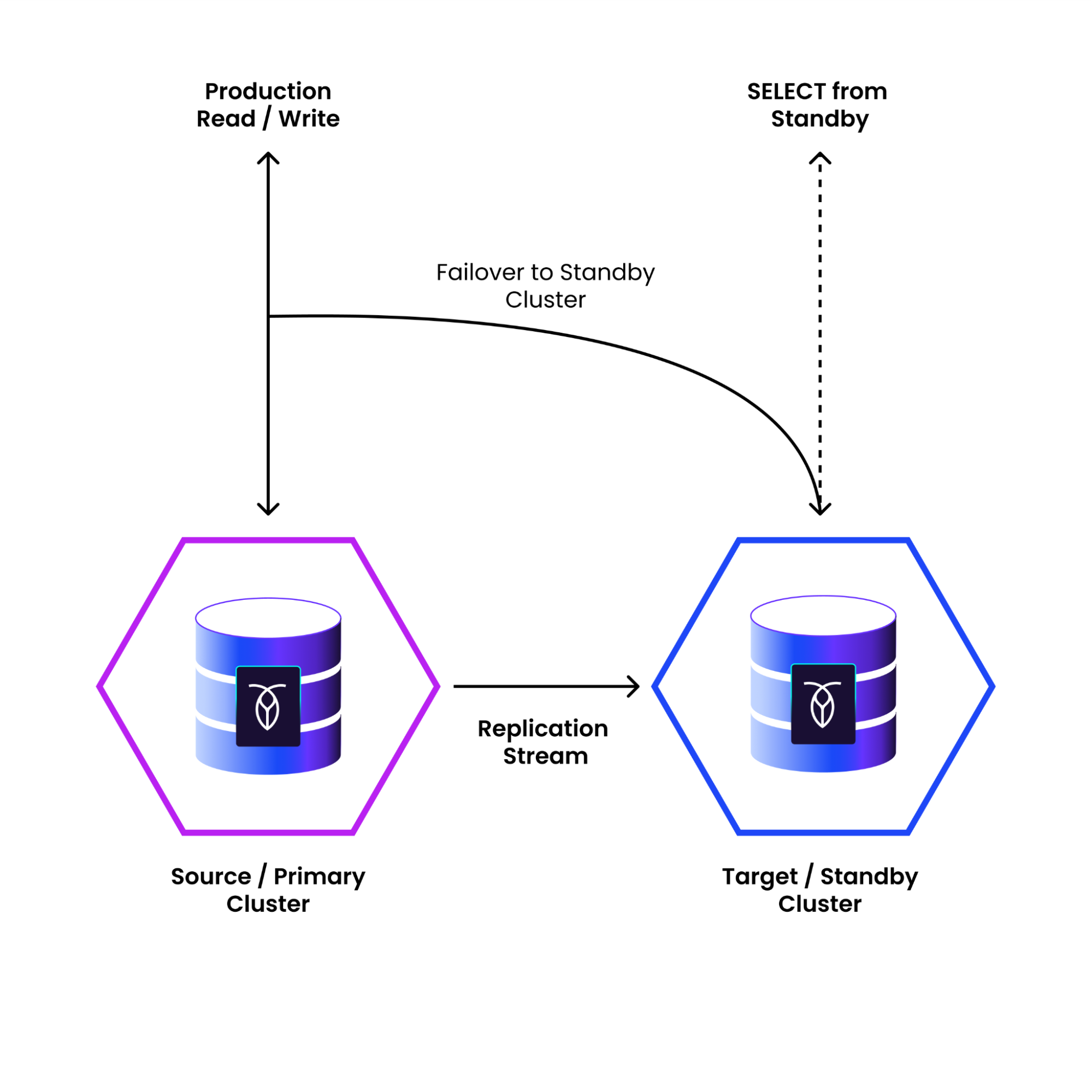
What it does:
Replicates entire clusters across geographic locations at the disk level.
Allows fast failover to a standby cluster in case of disaster.
How it helps:
Allows for region resiliency with a two data-center deployment.
If an entire cluster is lost, the standby cluster can be promoted with minimal data loss.
Unlike backups, which require restoration, physical cluster replication (PCR) allows near-instant failover, significantly reducing RTO.
If a data corruption event happens (e.g., an application bug overwrites data incorrectly), you can failover to an earlier point in time, before the corruption occurred.
RPO & RTO Impact:
RPO: ~30 seconds of replication lag.
RTO: Minutes to bring the standby cluster online.
Read our docs for more information on physical cluster replication (PCR).
Logical Data Replication: Sync Clusters using Bidirectional Replication
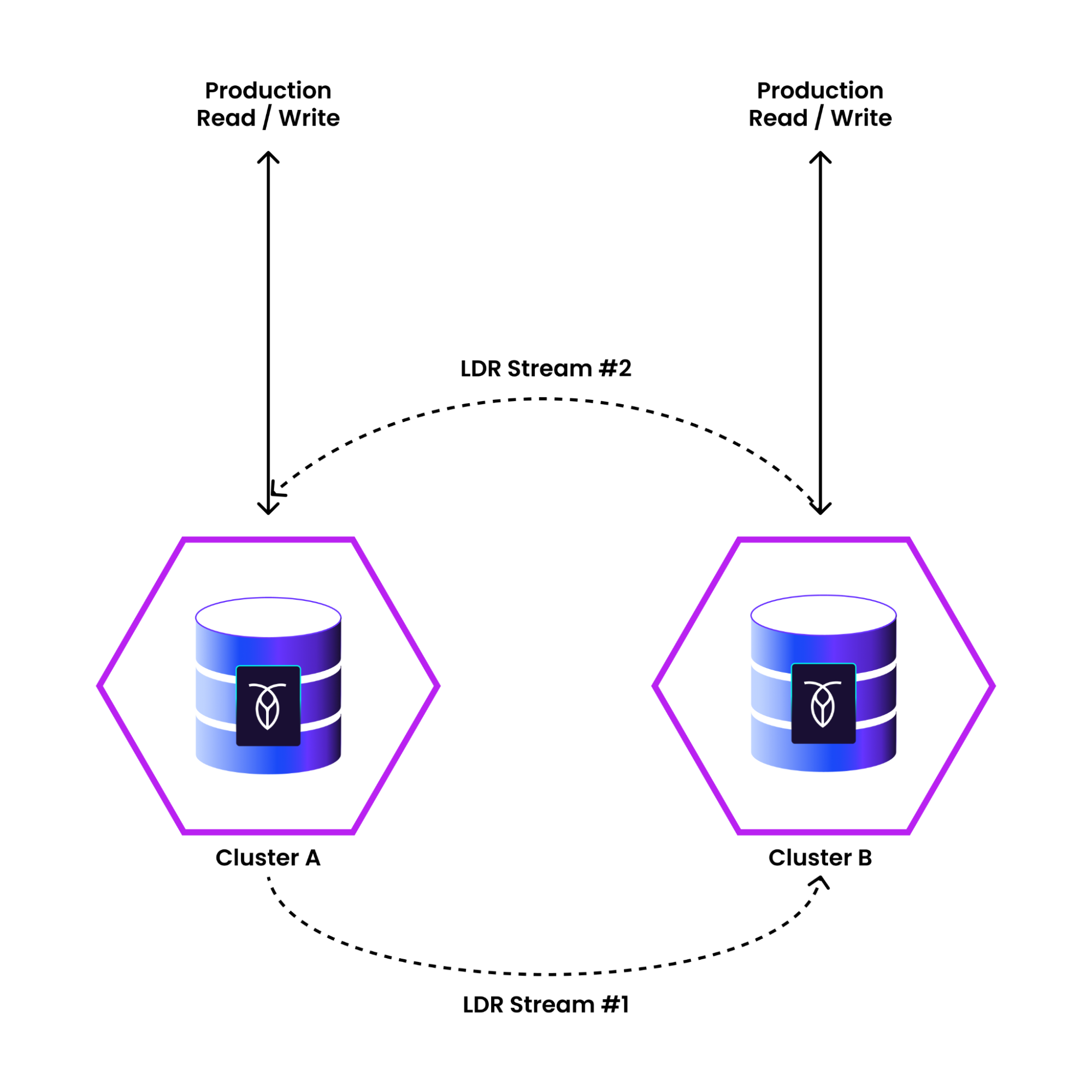
What it does:
Allows replication of tables to another CockroachDB cluster.
Can replicate to different cloud providers or hybrid environments.
How it helps:
Allows for region resiliency with a two data-center deployment.
If the primary cluster is lost, a secondary cluster can take over.
Ideal for multi-cloud or hybrid setups where full physical replication isn’t feasible.
Useful for migrating workloads or running analytics on a secondary cluster without impacting production.
RPO & RTO Impact:
RPO: Depending on replication lag (typically seconds to minutes).
RTO: Time for application load balancers to point to the surviving cluster.
Get the full details on logical data replication (LDR) in our docs or check out this blog called “2DC Support with Cross-Cluster Replication” to learn more about how PCR and LDR support CockroachDB customers every day.
Watch this talk from RoachFest 2024 to learn more about how PCR and LDR support two data-center (2DC) deployments:
Failure-Proofing Your Enterprise with CockroachDB
By understanding these common failure scenarios and leveraging the advanced features of CockroachDB, organizations can build applications and databases that are not only high performing but also resilient in the face of real-world challenges. Cockroach Labs’ focus on distributed design, automatic recovery, and continuous security helps ensure that both application and database layers can handle failures gracefully, keeping your systems reliable and available. And when catastrophic failures occur, Cockroach Labs provides enterprise-grade disaster recovery tooling to ensure resilience to even the most challenging failure scenarios.
Get started with CockroachDB Cloud today. We’re offering $400 of free credits to help kickstart your CockroachDB journey, or get in touch today to learn more.