

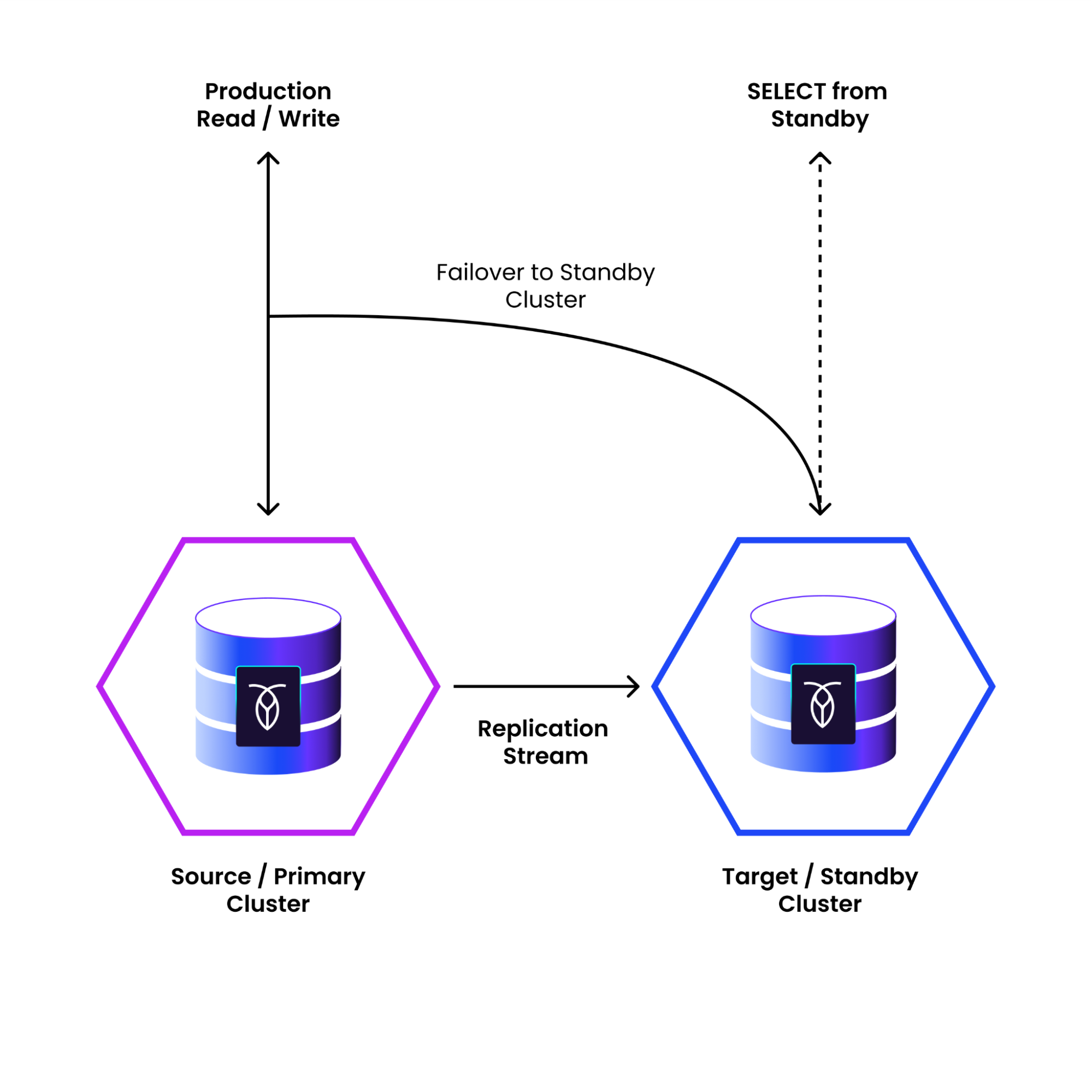
As a leading distributed SQL database, CockroachDB provides a number of capabilities to allow organizations and users to recover from disaster. Physical cluster replication, or PCR for short, is one such feature that enables operators to add "warm standby" clusters to their most critical CockroachDB deployments as an added layer of resilience and disaster preparedness in what is often called an "active-passive" configuration.
In this post we'll talk a little about how we designed PCR to replicate clusters asynchronously and to do so at scale while still providing the same rigorous transactional consistency guarantees that are synonymous with CockroachDB.
Why we built PCR: Improved customer experience
Before we jump into the details of how PCR works though, let's briefly look at why we built it and the feature requirements that guided its specific design.
CockroachDB is already architected from the ground up to natively provide high availability and durability via synchronous Raft replication within a cluster across multiple nodes, which can be placed in non-correlated failure domains such as separate availability zones, separate regions or even across wholly separate cloud providers. This ensures not just that data isn't lost but also that a cluster's availability is not disrupted by hardware failures or routine maintenance events. However, we had two key constraints to tackle, which we’ll describe below.
Customer constraint #1: Two data centers
Some operators have constraints on their deployments which preclude synchronous replication across 3+ non-correlated failure domains: some operators have only two data centers available, while others have traffic that is so sensitive to latency that it just cannot afford the delays imposed by the laws of physics on synchronous replication across regions.1 For these operators, the loss of a single region could mean unavailability of their cluster.
Customer constraint #2: RTO of Backup/Restore too high
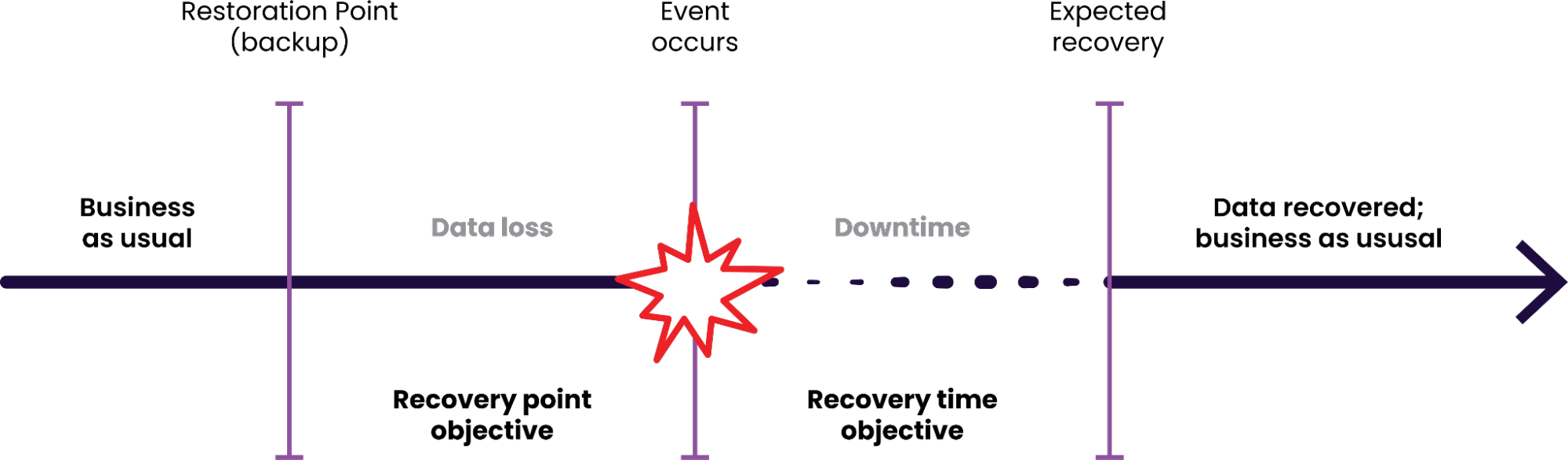
We could have mitigated the risk of the first constraint using our BACKUP and RESTORE functionality. Customers can back up a cluster's data to external storage such as Amazon's S3 (which offers exceptional durability guarantees) so that even if an entire cluster is lost, backed up data can still be recovered and service can be restored.
This recovery process however involves creating a new cluster and restoring the backed up data to it; if that is many terabytes of data this process can take a considerable amount of time, resulting in a higher “recovery time objective” (RTO). For most backup-and-restore based approaches, RTO scales with the data size that needs to be restored, and may not meet application requirements.
Some customers with stringent availability requirements are constrained to operating clusters in a single region or data center. Given the associated increased risk of full-cluster loss events, the time required to create a new cluster and then restore all their data to it fell short of their RTO needs.
Our design goals: Getting to PCR
Thus the primary design goal for PCR is to supply a recovery solution for full-cluster loss events with a much lower RTO than restoring from backups. While we were reaching for new heights in terms of resilience and disaster preparedness, we had to keep in mind the broader perspective of enterprise database needs. So we had to design our final solution to operate at scale, fill the gap of asynchronous replication, and of course, ensure transactional consistency.
Design goal #1: Lower RTO than Backup/Restore
To achieve lower RTO than backup and restore, we would need to move the primary driver of restoring the data to a new cluster out of the recovery phase, essentially "restoring" to a new cluster before disaster strikes rather than after, so it is ready at a moment's notice when needed. Of course just doing this once wouldn't be very useful as data continues to change, so the standby cluster would also need to be kept up to date as new writes are applied to our primary cluster.
Thus we arrived at the rough design of PCR: a system to replicate every write, from an active cluster to a standby cluster, so that the standby can serve as a low-RTO failover.
Design goal #2: Operate at scale
It perhaps goes without saying, but this system needed to operate at scale: CockroachDB is designed to scale horizontally, using hundreds of nodes to process and store far more data than any one node ever could. If we build a system to replicate a cluster, it will need to be able to replicate more data than any one node can replicate.
Design goal #3: Asynchronous replication
Additionally, this replication needed to be asynchronous: as we already mentioned above, CockroachDB already has and relies on the ability to synchronously replicate every write via its existing Raft replication, so the gap PCR needed to fill is where that facility does not apply such as mitigating the risk of region loss for clusters constrained to a single region.
Design goal #4: Transactional consistency
Finally, CockroachDB is built around transactional consistency: there are plenty of different distributed datastores to choose from but many operators choose CockroachDB specifically because of the rigorous transactional consistency we provide, so any system designed to replicate CockroachDB needs to provide the same.
After one recovers from a disaster using PCR, i.e. by failing over to the standby cluster, while the potential for some data loss is inevitable due to not synchronously replicating during every write, the recovered cluster must be transactionally consistent as of some point in time with the source cluster. This means all writes from any committed transaction as of the time of failure must be visible, and no writes from uncommitted transactions should be visible; there should be no transactions for which some writes are visible and some are not.
This last constraint is both one that our users rely on for consistency between their rows -- e.g. if a transaction transferred the balance from one user to another by writing two rows, you should see either both the debit row on one and credit row on the other, or neither row, but never only one of them -- and also a constraint that we rely on internally as well. One "row" stored in a CockroachDB is actually split into multiple keys which can be stored in different column families and in different indexes, and our execution engine relies on all of these entries being consistent with one another, so it is vital that each transaction be replicated completely or not at all.
Thus we arrive at our main design goal -- a system to recover from the loss of a cluster with low RTO, i.e. something that is measured in minutes even for large data sizes -- and our three main design constraints: that does this at scale and asynchronously, while still providing transactional consistency after recovery.
Detailed Design
The basic design of PCR is relatively simple: we create a second "standby" cluster, copy all the rows from the primary/source cluster to it and then every time a row is modified in the primary, we apply that same modification to the standby to keep it up to date.
While that seems simple enough, the tricky part is doing this both at a scale, i.e. concurrently on multiple nodes, while still ensuring we produce a transactionally consistent result.
To see how we do this, let's dig in to how PCR actually works:
The PCR process runs almost entirely on the standby cluster. It starts by connecting to and inspecting the primary cluster to divide it up into a number of roughly equally sized partitions (not to be confused with the concept of partitioned tables) that it can then assign to nodes of the standby cluster; each node will be responsible for ensuring all changes in the partition it is assigned are replicated.
Each standby node then connects to a node in the primary cluster to ask for a feed of every change to every row in its assigned partition. The primary cluster node uses an existing facility of CockroachDB's storage layer to register for a notification any time a row is modified -- this is the same subsystem that powers features like CHANGEFEEDS -- and sends these notifications back to the standby node. It also sends periodic notifications of the "resolved" timestamps up to which all changes in that partition are known to have been emitted.
The standby node buffers and applies every change notification it receives from the primary, and keeps track of the timestamp as of which it knows it has applied all changes, forwarding this information to a central coordinator process. If at any point any of the nodes in either cluster restart or become disconnected, the process can resume from the last recorded timestamp.
This process works well to ensure all changes across many partitions are successfully captured and applied, but has one problem: each partition is independently receiving and applying changes. Above we mentioned the importance of transactional consistency, but our two separate rows that a single transaction modified could be in two different partitions at this point, so there will be a point where we may indeed have applied our debit but not our credit, violating consistency. Of course once the other partition catches up, we will have both rows and once again be consistent -- but then we may have partially applied some newer transaction somewhere else.
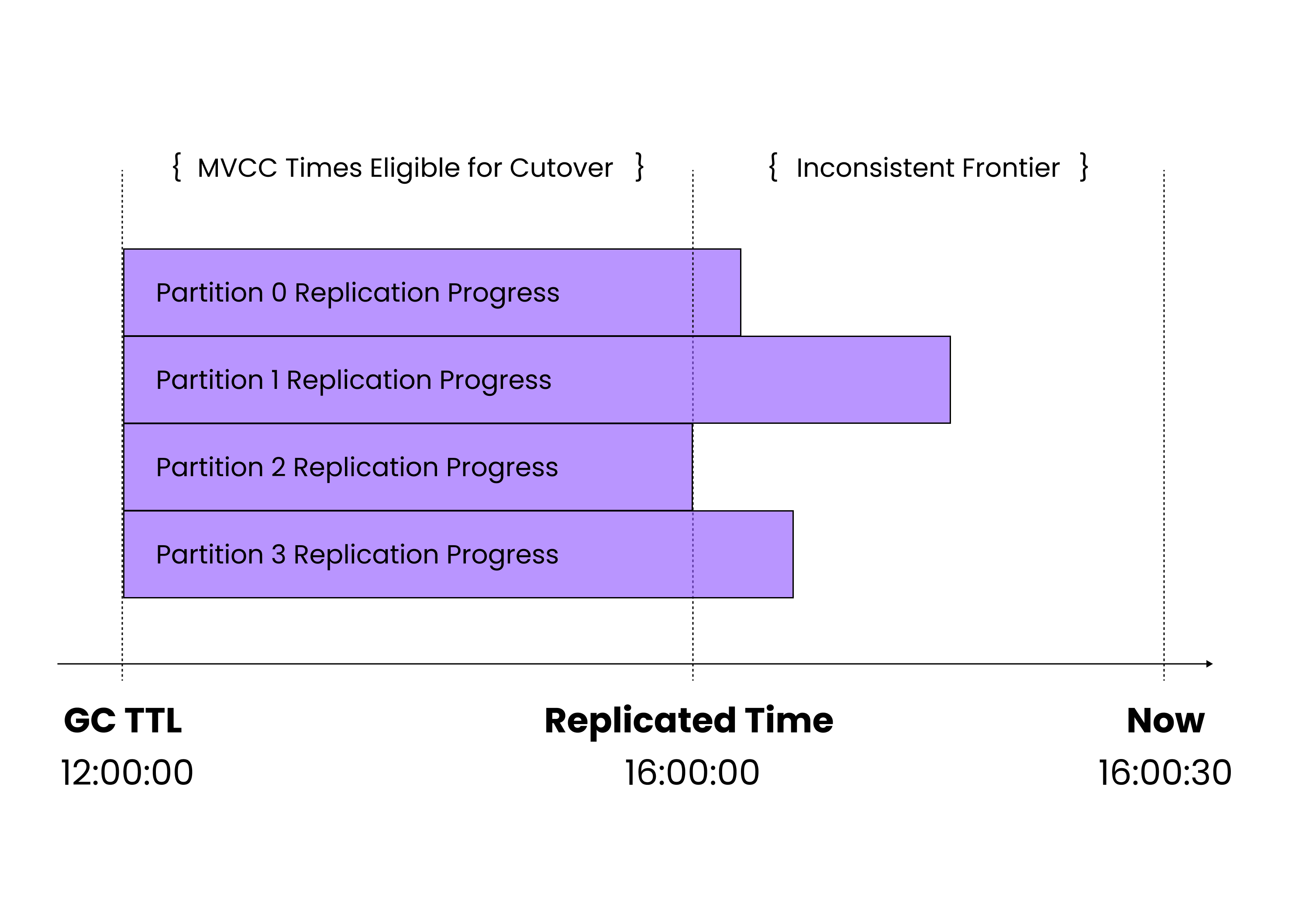
We considered trying to make the application of changes in separate partitions coordinate with each other, to atomically apply writes the writes in all partitions for a given timestamp at once, so once every partition had received and buffered all the changes between time T1 and time T2 -- and maybe some beyond T2-- a coordination mechanism would allow them to all simultaneously and in one transaction flush changes up to T2. But doing this at scale appeared to be a major challenge, particularly as the active cluster is able to process an unbounded number of concurrent non-overlapping transactions, and any given partition might fall behind requiring others to buffer. Instead, we just allow the process of replicating each partition to make progress independently, applying writes as it receives them. Even though this temporarily violates transactional consistency, and the explicit "activation" step we added to the failover process addresses this and ensures that the standby cluster is transactionally consistent during failover.
We already mentioned that the process responsible for applying changes for each partition periodically records the timestamp up to which up to which has applied all row modifications for its partition and that these are forwarded to a central coordinator. By taking the minimum of each of these timestamps across all partitions, that coordinator tracks the timestamp up to which it knows it has fully applied all modifications to the cluster -- along with potentially some but not all newer modifications. The cluster would be perfect transactionally consistent as of the known-fully-applied time (we call this the "replicated" time) if not for these partially applied newer modifications, so to "activate" the standby cluster to a transactionally consistent state, we just need to find and remove any modifications newer than our replicated time.
Enter MVCC
Fortunately here we can utilize the fact that CockroachDB’s underlying storage layer uses Multi-Version Concurrency Control (MVCC) to version every change to every key-value pair it stores, and does so using the timestamp at which each modification was made as the version number: if we can find and remove every KV stored with an MVCC timestamp greater than the timestamp to which we are failing over, we we will effectively "revert" any changes, including these partially applied changes that violate transactional consistency and when complete, can assert that the content of the cluster is exactly the content of primary cluster as of that timestamp, since we know we copied every change up to that time, plus maybe a few more which we then reverted.
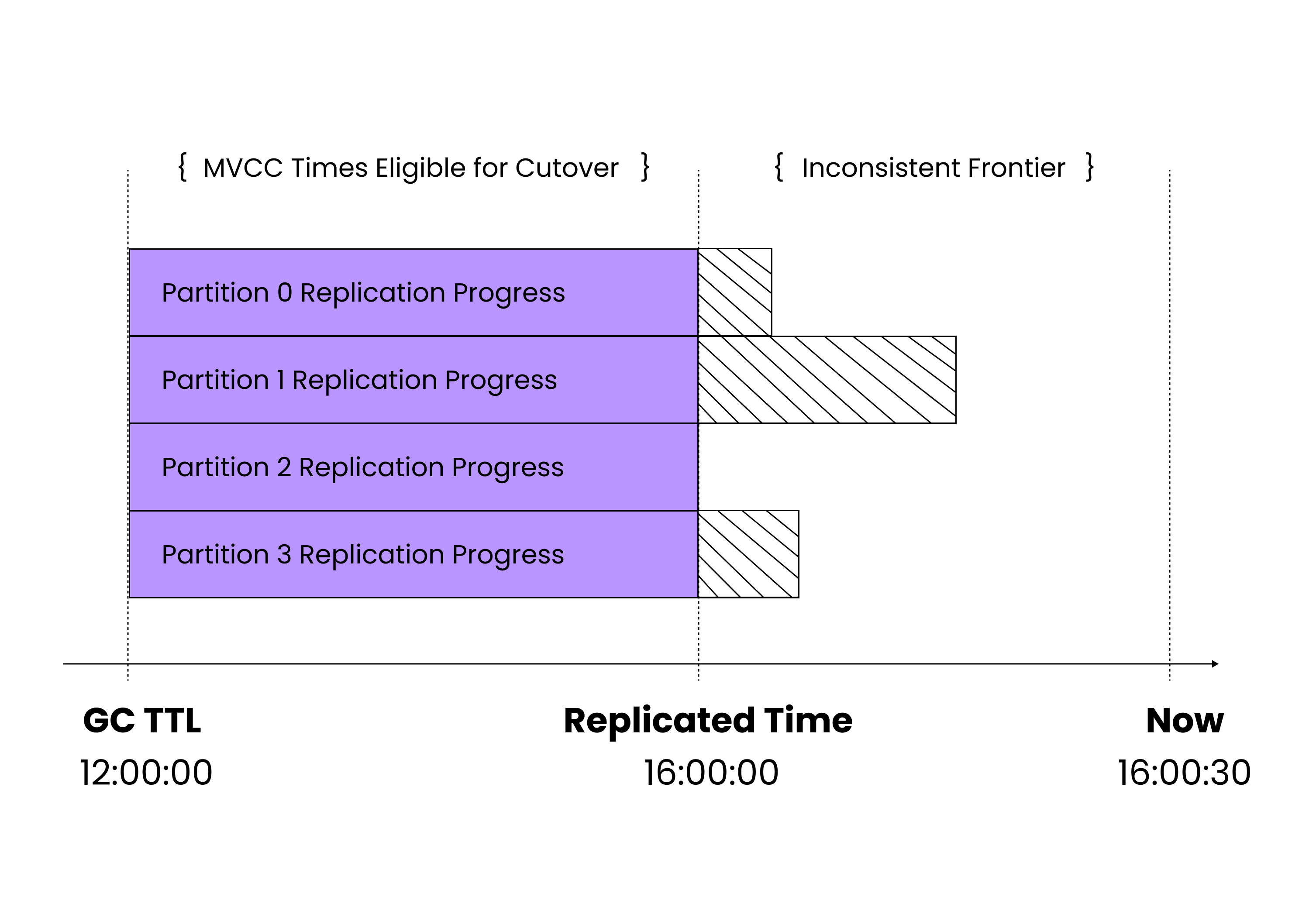
This explicit revert step during activation is what allows PCR to provide the transactional consistency guarantees after failover even though the actual replication process is performed asynchronously and independently without coordination across many nodes.
And as an added bonus, since the MVCC storage layer can be configured to retain revisions for longer periods of time, we can in fact revert to not just the latest known consistent "replicated" time but indeed any timestamp up to that point for which we are still retaining history. While we may have replicated all writes up to 30 seconds ago, if we have retained history going back four hours, then we can revert to 30s ago, to 47 minutes ago or to four hours ago using this same process of finding and rolling back the newer revisions. This means an operator can failover to an older time if it took longer to detect and react to an event (eg. an accidentally run malformed UPDATE) and still be sure that they're failing over to a transactionally consistent timestamp.
PCR Today
Taken together -- a distributed system of independent asynchronous replication processes, a system for tracking replicated timestamps, and a method for failing over to a consistent timestamp -- the components of PCR enable it to asynchronously replicate large clusters and high volumes of transactions efficiently, while still ensuring a correct and transactionally consistent result. PCR has shown that it can keep up with demanding workloads with minimal impact on the active source cluster.
PCR is generally available as of CockroachDB v24.1. To get started head to our docs.
Notes
The major cloud providers typically offer multiple availability zones in most regions, which can provide the ability to deploy 3+ nodes in non-correlated failure domains without incurring cross-region replication latency. However some operators are still required to account for the potential loss of an entire region, and not all regions offer 3+ AZs.




