

In the arms race against financial fraud, milliseconds matter.
For any given transaction, fraud detection systems must decide whether or not it’s fraudulent and immediately act accordingly. Failing to definitively address fraud leads to significant losses, harms organizations’ brand image, tarnishes their reputation, and inevitably repels customers.
The incidence of fraud has reached record levels. Estimates for the worldwide cost of fraud — including cybercrime, financial fraud, and related losses — range from $1.2 trillion to over $1.5 trillion annually by the end of 2025.
Meanwhile, fraudsters are evolving fast and moving in tandem with digital banking transformations, devising crafty ways to steal or fake customers’ identities and commit fraud at a high velocity. As a result, traditional rules-based (offline) fraud detection systems are no longer effective, as they rely on static heuristics and batch processing that can't keep pace with adaptive, real-time fraud tactics.
Fraud detection systems must ingest massive volumes of transactional data, evaluate it against dynamic rulesets, and make decisions in real time — all while operating across global infrastructure. Traditional databases often buckle under this pressure and deliver poor fraud prevention performance, due to inefficient data access strategies.
Enter CockroachDB, a distributed SQL database built for scale, resilience, and performance. When it comes to the latest generation of AI-powered fraud detection systems, the heart of CockroachDB’s advantage lies its advanced vector indexing capabilities. In addition to the existing geo-partitioned and inverted indexes, CockroachDB empowers developers to build online fraud detection systems that are both fast and intelligent.
This article explores how these new vector indexing features enable low-latency anomaly detection, real-time alerting, and region-aware decision making — without compromising on correctness or scale.
Fraud Detection Challenges
Fraud detection systems face several challenges that make it difficult to accurately identify fraudulent activities. Some of these challenges are:
Evolving Fraud Techniques: Fraudsters continually adapt and develop new techniques to evade detection. As a result, fraud detection systems must be updated regularly to keep up with evolving schemes.
Data Quality: The accuracy of fraud detection systems depends on their data quality. If the data is incomplete, incorrect, or inconsistent, it can lead to false positives or false negatives, reducing the effectiveness of the system.
Balancing Fraud Detection and User Experience: While fraud detection systems aim to minimize fraud, they must also maintain a good user experience. Overly strict fraud detection rules can result in false positives and increased friction, leading to unhappy customers.
Cost: Implementing and maintaining a fraud detection system can be expensive. The cost includes acquiring and processing large amounts of data, developing and maintaining the algorithms and models, and hiring personnel to manage the system.
Privacy Concerns: Fraud detection systems require access to sensitive customer data, which can raise privacy concerns. Companies must ensure that their fraud detection systems comply with privacy regulations and implement proper security measures to safeguard the data.
Next, we’ll focus on the two main challenges listed above: false positives and latency. Both lead to unhappy customers and substantial losses.
1 - False Positives
What is a false positive? When a legitimate transaction is flagged as fraud, it is known as a “false positive.” This situation is highly frustrating for customers and can prove to be quite costly for enterprises. To address this challenge, a multi-layer approach is required to improve detection and continuously learn from evolving fraud patterns.
The multi-layer approach is a technique used in fraud detection systems to improve the accuracy and effectiveness of fraud detection. It involves using multiple layers of fraud detection methods and techniques to detect fraudulent activity. The multi-layer approach typically includes three layers:
Rule-Based Layer: The first layer is a rule-based system that uses predefined rules to identify potential fraudulent activity. These rules are based on historical fraud data and are designed to detect known fraud patterns. Some examples of these rules:
Blacklisting fraudsters’ IP addresses
Deriving and utilizing the latitude and longitude data from users’ IP addresses
Utilizing the data on browser type and version, as well as operating system, active plugins, timezone, and language
Per-user purchase profile: Has this user purchased in these categories before?
General purchase profiles: Has this type of user purchased in these categories before?
The rules can be implemented so that it can start from a “low cost” to “high cost.” If a user makes a purchase within already-known categories and within min/max transaction amounts, the application can tag the transaction as non-fraudulent and skip further detection steps.
Anomaly Detection Layer: The second layer is an anomaly detection system that identifies unusual activity based on statistical analyses of transactional data. This layer uses machine learning (ML) algorithms such as Random Cut Forest to identify patterns that are not typically seen in legitimate transactions. This layer involves first converting data into a high-dimensional vector space using embedding techniques — here the embeddings represent the different fraud attributes/rules like location, transaction amount, user profile, IP addresses… then training a random forest model on these embeddings to identify anomalies as data points that deviate significantly from the norm.
Predictive Modeling Layer: The third layer is a predictive modeling system that uses advanced machine learning algorithms, such as XGBoost, to predict the likelihood of fraud. This layer uses historical data to train the models and can detect new fraud patterns that are not detected by the previous layers. This layer can also be effectively used to predict anomalies when combined with vector embeddings.
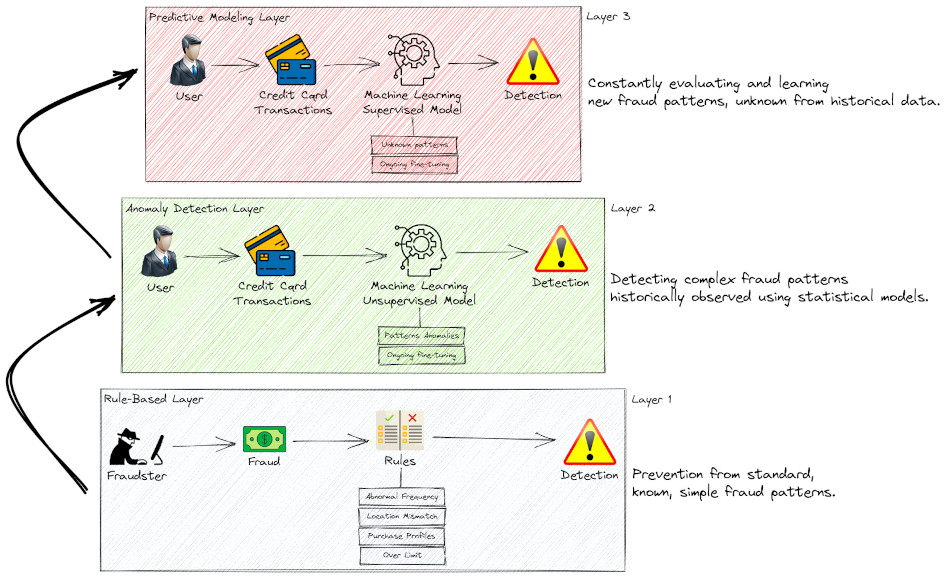
Multi-Layered Fraud Detection
By using a multi-layer approach, fraud detection systems can minimize false positives and false negatives, improving fraud detection accuracy. The multi-layer approach also helps to detect fraud with accuracy, preventing customer dissatisfaction when they are falsely flagged as a fraudster.
2 - Latency
As mentioned earlier, fraudsters are evolving and becoming more complex. Therefore, the detection should not fall behind, and enhanced detection should not increase latency. If companies cannot detect whether the transaction is fraudulent or not within a few milliseconds, by default, it’s considered genuine. This is why latency is a significant challenge in fraud detection.
To address this issue, organizations can leverage vector similarity search to retain and manage the embeddings used by the online (a.k.a., real-time) fraud detection systems.
Embeddings are the attributes used by machine learning models to make predictions or classifications. Examples of the transaction vector can include customer demographics, purchase history, website activity, and product preferences. A vector database stores these vectors in a centralized location and provides them to machine learning models in low latency.
While native vector databases provide efficient similarity search through advanced indexing structures like HNSW or IVF, traditional relational databases with vector support often lack sophisticated vector indexing. These databases typically resort to brute-force searching for vector similarity operations. Therefore, when the number of transactions to be assessed grows to millions or even billions, vector searches become prohibitively slow, and the fraud detection system loses its real-time capability.
CockroachDB addresses this fundamental performance problem with release 25.2, which includes a high-performance indexing support for multi-dimensional vectors. The optimizer incorporates secondary vector indexes into query plans, and the execution engine implements this new type of index. Users are able to write queries that efficiently search across both relational and vector data, even in the same query.
By using CockroachDB as a distributed vector database, fraud detection systems can quickly access and reuse historical data (vectors) for different models without re-engineering or reprocessing them. As new data is collected, the database can update the embeddings used by the machine learning models, resulting in more accurate fraud predictions. This improves efficiency and reduces latency when detecting fraud.
Fraud Detection System with CockroachDB & AWS AI
CockroachDB plays two roles in the fraud detection system:
1) As a global online transaction processing (OLTP) database that stores and indexes the financial transactions.
2) As a vector database operated by the AWS AI services Bedrock and Sagemaker. Both roles are interdependent and can coexist on a single cluster.
As a prerequisite, historical transactions (training data) are given to AWS Sagemaker to train its ML models. Once the transactions are flagged as fraudulent, they are stored in CockroachDB as vector embeddings.
The fraud detection system is booted when an AWS Lambda function consumes the real-time transaction stream from Kinesis, applies the rules, creates the vector embeddings using AWS Bedrock foundational models, and sinks both transactional and vectorial data into CockroachDB.
CockroachDB also loads historical data directly from an S3 bucket using the IMPORT INTO statement. Now data can enter the fraud detection pipeline, using it as input to train and improve the models running on AWS SageMaker.
Remember the two main fraud detection challenges presented above, false positives and latency. CockroachDB can address both from different perspectives:
First, it applies predefined rules to identify potential fraudulent activity (rule-based layer). This ensures consistent accurate blacklisting of the IP addresses by implementing rate limiting and using the geospatial native capabilities, to calculate and assess the user location. Thus, we can avoid any false positives by applying these prefilters on the incoming traffic.
Second, to provide a low-latency fraud detection system, the engine needs to quickly read the last inserted vector in CockroachDB, search among billions of historical vectors labeled as fraudulent, and calculate distance between this new transaction and the fraudulent ones. Then, based on this distance, the ML model will classify the transaction.
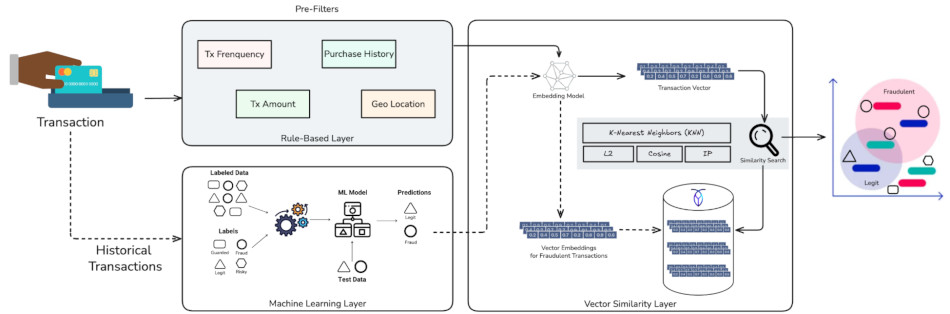
GenAI-based Fraud Detection System
However, even with a good storage backend, plugging the anomaly detection system into a distributed SQL database like CockroachDB isn’t straightforward. To support elastic scalability, fault tolerance, and multi-region availability, CockroachDB designed vector indexing with a novel approach:
First, it should operate without a central coordinator — every node in the cluster must be able to handle reads and writes independently, avoiding bottlenecks or single points of failure.
The index must also avoid relying on large in-memory structures; instead, its state should be stored persistently to accommodate serverless and low-memory environments without long warm-up times.
The index must avoid hot spots by distributing workload evenly across the cluster, even under high-volume inserts or queries.
Lastly, it must support incremental updates — handling inserts and deletes in real time without blocking queries or requiring full rebuilds. These requirements ruled out many conventional indexing strategies, prompting the design of a new approach tailored to CockroachDB’s distributed architecture.
This vector indexing algorithm (called C-SPANN) is designed to organize vectors into partitions based on similarity, with each partition typically containing dozens to hundreds of vectors.
Each of these partitions is represented by a centroid — the average of all vectors within it — serving as a "center of mass" for that group. These centroids are then recursively clustered into higher-level partitions, forming a multi-level tree structure (a hierarchical K-means tree).
This hierarchical organization allows the index to rapidly narrow down the search space by traversing from broad clusters to increasingly specific subsets. The result is significantly improved efficiency and speed of vector lookups.
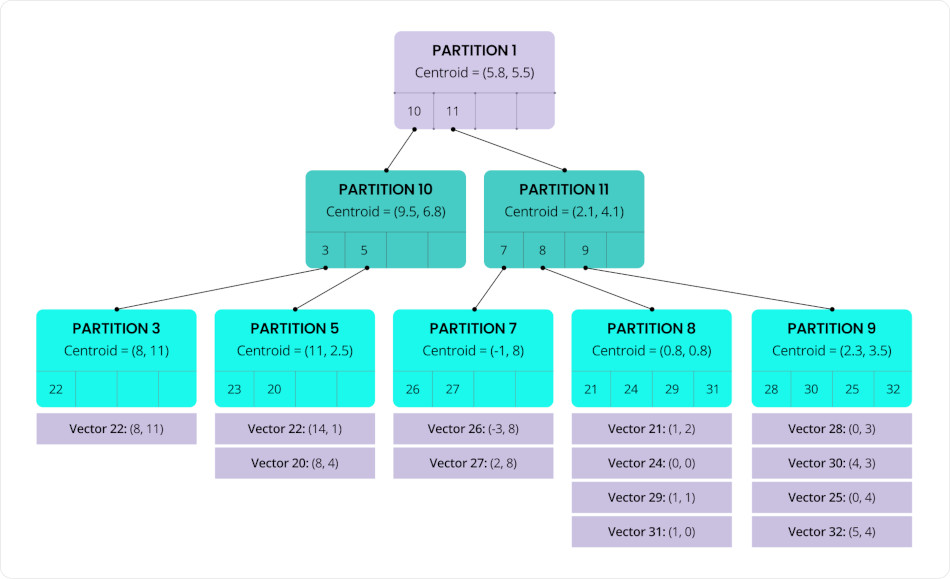
C-SPANN: Hierarchical K-means tree
As new vectors are inserted into the index, they are naturally distributed across multiple partitions, which themselves are spread throughout the cluster. This design ensures that no single node or range becomes a bottleneck, effectively preventing hot spots and enabling the system to scale write throughput.
Splitting a partition improves search efficiency by maintaining tight clustering of vectors. Splitting a range helps balance data storage and access across the cluster. Together, these mechanisms reduce hot spots and help spread both query and insert load more evenly.
When nodes are added to the system, ranges containing index partitions are automatically distributed across the new nodes. This allows the total workload to scale out with the cluster at near-linear rates.
The diagram below illustrates the fraud detection solution architecture implemented with CockroachDB and AWS:
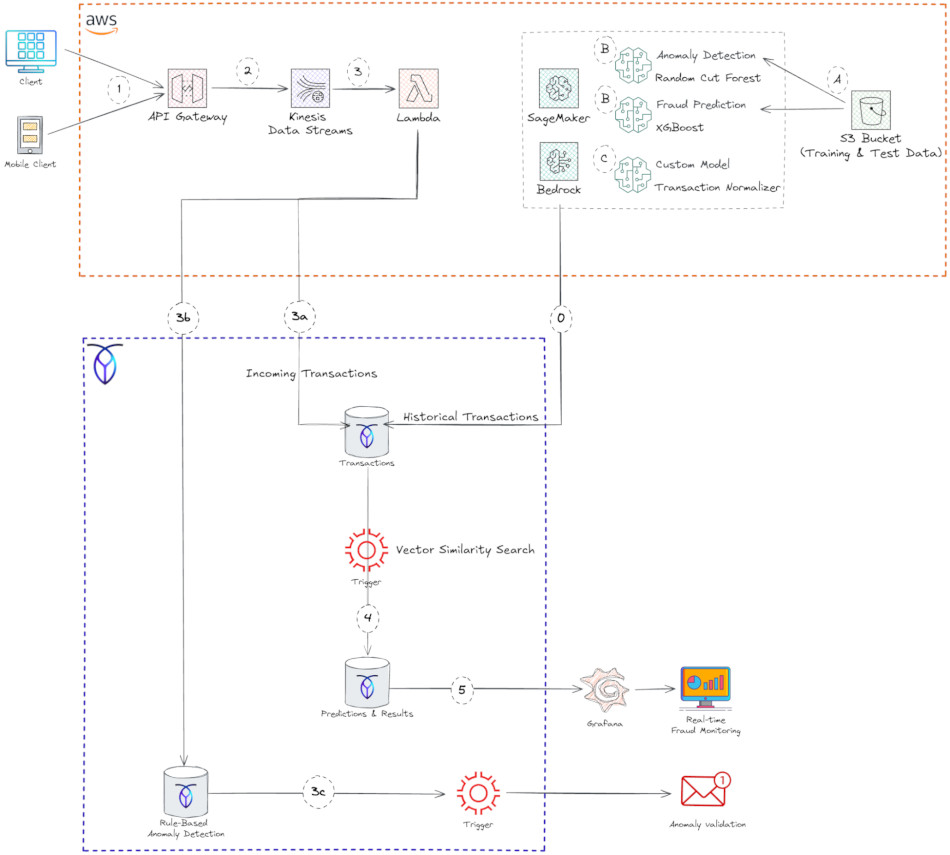
Reference Architecture of Fraud Detection with CockroachDB and AWS
A. As a prerequisite, you need to put historical datasets of credit card transactions into an Amazon S3 bucket. These data serve to train and test the machine learning algorithms that detect fraud and anomalies.
B. Amazon SageMaker is a machine learning (ML) workflow service for developing, training, and deploying models. It comes with many predefined algorithms. You can also create your own algorithms by supplying Docker images, a training image to train your model, and an inference model to deploy to a REST endpoint. In CockroachDB, we have chosen Random Cut Forest algorithm for anomaly detection and XGBoost for Fraud prediction:
Random Cut Forest (RCF) is an unsupervised algorithm that detects anomalous data points in a dataset. Anomalies are data observations that deviate from the expected pattern or structure. They can appear as unexpected spikes in time series data, interruptions in periodicity, or unclassifiable data points. These anomalies are often easily distinguishable from the regular data when viewed in a plot.
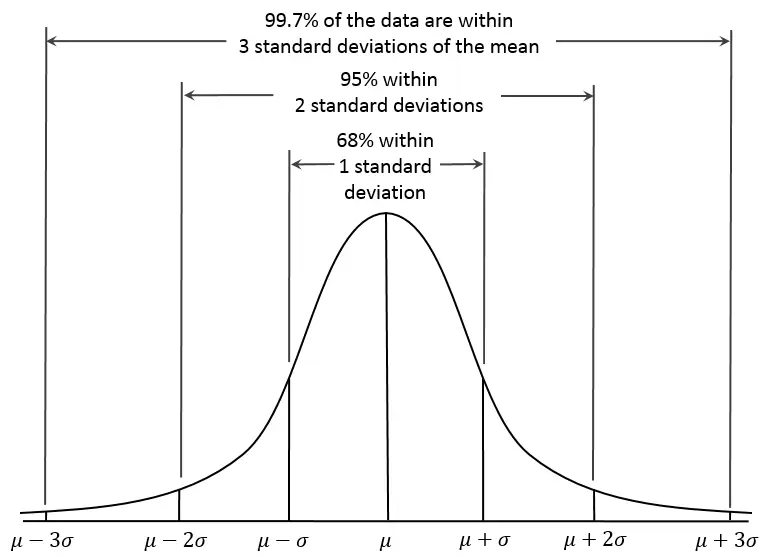
RCF assigns an anomaly score to each data point. Low scores indicate that the data point is normal, while high scores indicate the presence of an anomaly. The threshold for what is considered “low” or “high” depends on the application, but typically scores beyond three standard deviations (3σ) from the mean are considered anomalous.
xGBoost, short for eXtreme Gradient Boosting, is a widely used open-source implementation of the gradient-boosted trees algorithm. Gradient boosting is a supervised learning method that aims to predict a target variable by combining estimates from an ensemble of simpler and weaker models.
The XGBoost algorithm is highly effective in machine learning competitions due to its ability to handle various data types, distributions, and relationships, plus the wide range of hyper-parameters that can be fine-tuned.
The Lambda function calls the AWS SageMaker models endpoints to assign anomaly scores and classification scores to historical transactions.
def makeInferences(data_payload):
print("** makeInferences - START")
output = {}
output["anomaly_detector"] = get_anomaly_prediction(data_payload)
output["fraud_classifier"] = get_fraud_prediction(data_payload)
print("** makeInferences - END")
return output- Anomalies detection:
def get_anomaly_prediction(data):
sagemaker_endpoint_name = 'random-cut-forest-endpoint'
sagemaker_runtime = boto3.client('sagemaker-runtime')
response=sagemaker_runtime.invoke_endpoint(EndpointName=sagemaker_endpoint_name, ContentType='text/csv', Body=data)
print("response from get_anomaly_prediction=")
# Extract anomaly score from the endpoint response
anomaly_score=json.loads(response['Body'].read().decode())["scores"][0]["score"]
print("anomaly score: {}".format(anomaly_score))
return {"score": anomaly_score}- Fraud prediction:
def get_fraud_prediction(data, threshold=0.5):
sagemaker_endpoint_name = 'fraud-detection-endpoint'
sagemaker_runtime = boto3.client('sagemaker-runtime')
response=sagemaker_runtime.invoke_endpoint(EndpointName=sagemaker_endpoint_name, ContentType='text/csv', Body=data)
print("response from get_fraud_prediction=")
pred_proba = json.loads(response['Body'].read().decode())
prediction = 0 if pred_proba < threshold else 1
# Note: XGBoost returns a float as a prediction, a linear learner would require different handling.
print("classification pred_proba: {}, prediction: {}".format(pred_proba, prediction))
return {"pred_proba": pred_proba, "prediction": prediction}
C. A notebook instance calls a custom embedding model from AWS Bedrock to vectorize the historical datasets trained and scored by AWS Sagemaker. Then store the fraudulent transactions as vectors in CockroachDB (Step 0 in the diagram).
1. The data flow starts with end users (mobile and web clients) invoking Amazon API Gateway REST API.
2. What are Amazon Kinesis Data Streams? These are used to capture real-time event data. Amazon Kinesis is a fully managed service for stream data processing at any scale. It provides a serverless platform that easily collects, processes, and analyzes data in real time so you can get timely insights and react quickly to new information. Kinesis can handle any amount of streaming data and process data from hundreds of thousands of sources with low latencies.
3. What is AWS Lambda? This is a serverless, event-driven compute service that lets you run code for virtually any type of application or backend service without provisioning or managing servers. In our solution, the Lambda function is triggered by kinesis to read the stream and perform the following actions:
3a. Persist transactional data into CockroachDB to enable low-latency indexing and querying of transactions. For this the following schema was created in the FRAUD_DB database:
CREATE TABLE FRAUD_DB.transactions (
transaction_id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
account_id UUID NOT NULL,
merchant_id UUID,
transaction_type TEXT NOT NULL CHECK (transaction_type IN ('debit', 'credit', 'refund', 'chargeback')),
amount BIGINT NOT NULL CHECK (amount_cents >= 0),
currency_code CHAR(3) NOT NULL,
status TEXT NOT NULL CHECK (status IN ('pending', 'completed', 'failed', 'reversed')),
transaction_time TIMESTAMPTZ NOT NULL DEFAULT now(),
location_ip INET,
location POINT,
metadata JSONB,
created_at TIMESTAMPTZ DEFAULT now(),
updated_at TIMESTAMPTZ DEFAULT now(),
transaction_vector VECTOR(24)
);
3b. The first layer in the fraud detection approach is a rule-based system that applies predefined rules to identify potential fraudulent activity. The rules can be implemented so that it can start from a “low cost” to “high cost”.
For example, you can implement a rate limiting function in CockroachDB that checks the IP addresses and blacklist any address that connects more than a certain limit. Thus, you can apply preliminary anomaly detection without using ML inference.
3c. When a rule-based anomaly is identified, a CockroachDB trigger notifies the end user and requests validation for the transaction.
4. To avoid false positives and false negatives, another CockroachDB trigger runs a function that calculates distance between the new incoming transaction vectors and the billions of historical fraudulent transactions stored as vectors. The function then saves the search results in CockroachDB.
When we perform a similarity search without a proper vector index, the main challenge is that your DB engine will perform a full scan of all your data and calculate the similarity metrics to find the closest vectors to your query.
To check that, you can use the EXPLAIN statement that returns CockroachDB's query plan. You can use this information to optimize the query, and avoid scanning the entire table, which is the slowest way to access data.
Let's apply this statement to the similarity search query:
EXPLAIN SELECT transaction_id, transaction_vector <-> new_trancation_vector AS l2_distance FROM fraudulent_transactions ORDER BY l2_distance DESC;The output shows the tree structure of the statement plan, in this case a sort, and a scan:
info
-----------------------------------------------------------------------
distribution: full
vectorized: true
• sort
│ estimated row count: 3.000.000
│ order: -l2_distance
│
└── • render
│
└── • scan
estimated row count: 3.000.000 (100% of the table; stats collected 2 minutes ago)
table: fraudulent_transactions@transaction_id
spans: FULL SCAN
Now let’s create a vector index on the transaction vector:
CREATE VECTOR INDEX trx_vector_idx ON transactions (transaction_vector);Once the vector index has been fine-tuned, the next EXPLAIN call demonstrates that the span scope is LIMITED SCAN now. This indicates that the table will be scanned on a subset of the index key ranges.
info
-----------------------------------------------------------------------
distribution: local
vectorized: true
• sort
│ estimated row count: 294.547
│ order: -l2_distance
│
└── • render
│
└── • vector search
table: fraudulent_transactions@trx_vector_idx
target count: 294.547
spans: LIMITED SCAN
As you can observe, the estimated row count is around 10% of the table count. This significantly improves the execution time of vector search, and the overall latency of the fraud detection system.
Note that search accuracy is highly dependent on workload factors such as:
partition size
the number of
VECTORdimensionshow well the embeddings reflect semantic similarity
how vectors are distributed in the dataset.
5. Optionally, the similarity search results, along with transactional details, can also be stored in a time-series database for further data visualizations using the observability platform Grafana.
Below is the Grafana dashboard that shows real-time fraud scores for incoming transactions. On a scale of 0 to 1 and for any given transaction, if the fraud score exceeds 0.8, it is considered fraudulent and shown in red. In addition, other charts are used to visualize fraud activity over time or to compare fraudulent vs. non-fraudulent (bottom side).
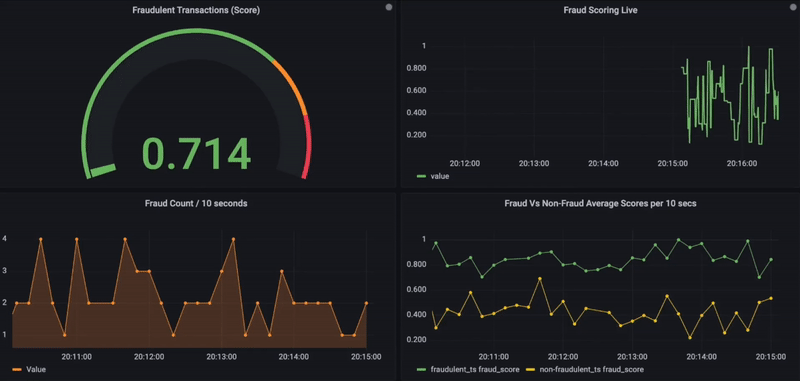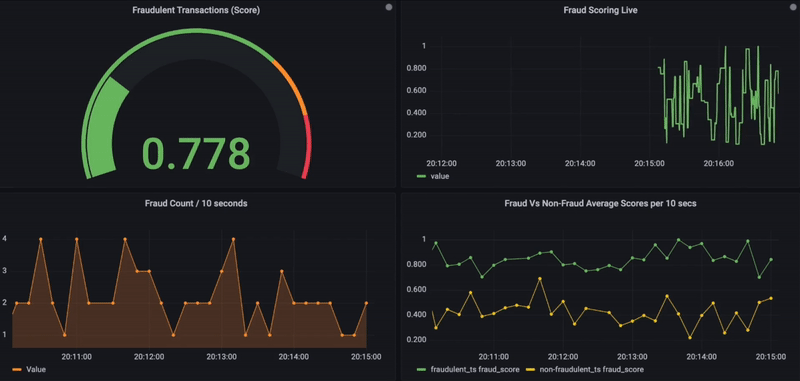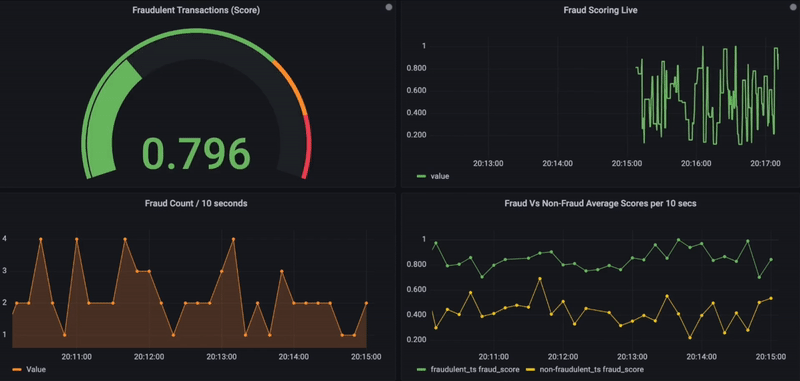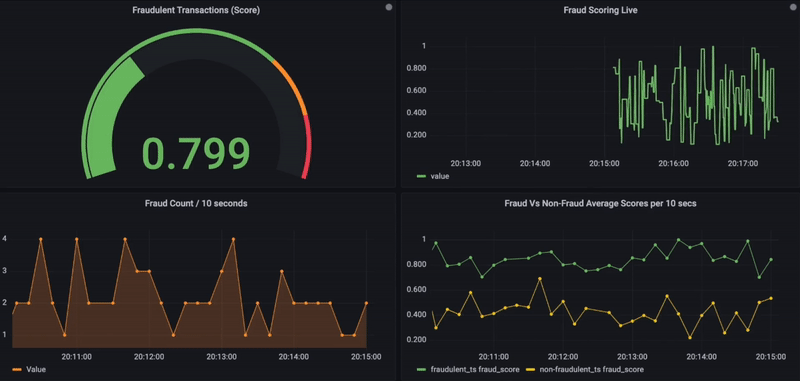
Real-Time Fraud Monitoring using Grafana
How to defeat fraud
CockroachDB’s distributed architecture and vector indexing capabilities unlock something powerful: a new level of speed and intelligence for real-time fraud detection.
When paired with AWS AI services like Bedrock, SageMaker and Lambda, you can build a robust, scalable pipeline that detects anomalies early, classifies them accurately, and responds within seconds. This system not only reduces fraud risk, but also avoids blocking legitimate users — maintaining security and user trust, so enterprises can grow.
Need to be sure your AI applications have the resilience, performance, and simplicity you need to succeed? Get your free guide, “The New Blueprint for AI-Ready Data: Vector Search Meets Distributed SQL”.
Amine El Kouhen, Ph.D., is Sr. Partner Solutions Architect at Cockroach Labs.


