

Many databases -- including Amazon Aurora and CockroachDB -- claim to be "global." While there is no official definition of the term "global database", it deserves to be unpacked.
For those who prefer to watch or listen, we explore Aurora's architecture in depth during this webinar: "CockroachDB vs Amazon Aurora: Battle of the Cloud Databases".
## What is a global database?
A global database promises global capabilities. At a bare minimum, it should satisfy these three requirements:
Global availability: Leverages geographic diversity of nodes to keep data available. It should be always on and resilient to facility failures and natural disasters.
Global performance:Supports policies to replicate data close to where it is most often accessed (reads & writes) to achieve optimal global latencies.
Global consistency:Maintains consistency even in a globally dispersed deployment.
CockroachDB is a global database built from the ground up with global availability, global performance, and global consistency in mind, while others - like Amazon Aurora - have tried to shoehorn these similar capabilities into legacy technology. This post will walk you through a review of Amazon Aurora's approach to a global database compared to CockroachDB, with a focus on how they fare across these three requirements. While Aurora may deliver some global-like capabilities, the application of the word “global” is applied too loosely to conform to the definition. Here’s what that means for your deployment.
What is Amazon Aurora?
Amazon Aurora is a cloud-based relational database engine that combines the speed and reliability of high-end commercial databases with the simplicity and cost-effectiveness of open source databases. Amazon Aurora may call itself a "global database" in its marketing materials, but Amazon Aurora is a mostly an option for single region deployments. It's optimized for read-heavy workloads when write scalability can be limited to a single master node in a single region. No matter how it's deployed, it will suffer latency issues with global writes as a write node (single or multi master) is always tied to a single region. Aurora uses the standard MySQL and PostgresSQL execution engines and layers in a distributed storage system that provides them with scale and resilience..
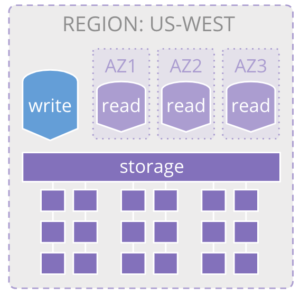
With a standard instance of Aurora you have a single write node that handles all writes into the database. You then deploy a number of read nodes to meet your read throughput requirements across multiple availability zones within the region. Aurora accomplishes this by writing to a custom, distributed storage layer, instead of locally to attached persistent storage. This layer is comprised of SSD storage devices across multiple AZs. It writes 6 copies of your data across, two copies in each of three availability zones. Each transaction is committed when 4 of the 6 replicas have been committed. While Aurora still uses the MySQL or PostgresSQL execution engines, this new approach reduces read latencies and also provides redundancies that make it more resilient than a traditional monolithic architecture with attached storage.
Is Amazon Aurora really a global database?
In 2018, Amazon introduced Aurora Global Database, which takes its original single region architecture and allows you to extend read replicas from a single region to two regions. This allows expanded read coverage with reduced latencies across geographic distance to one additional region. It employs asynchronous replication at the storage layer to keep the two regions in sync.
The primary instance contains the write node, while secondaries are comprised of only read nodes so you only scale reads to a new region. This configuration is constrained to duplicate the entire storage layer to the additional region, and looks like this:
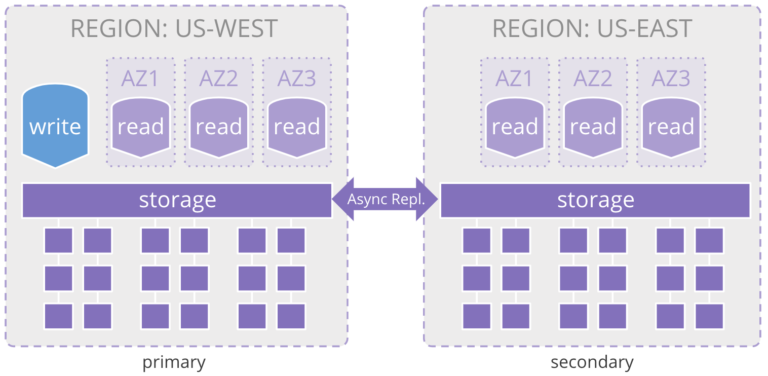
On failure, Aurora Global Database allows one of the read-only database nodes in the secondary region to be promoted to the primary write node, allowing business continuity in the event of a regional outage. However, because the replication between regions is asynchronous, there is the potential for data loss of up to a second (i.e., a non-zero recovery point objective – RPO), and up to a minute to upgrade the read node to primary write node (i.e., 1 minute for the recovery time objective – RTO).
Both of the previous two configurations rely on a single write node for the database. This implies a single point of failure which introduces failover risk and a significant recovery time objective (RTO) in the event of failure. Additionally, this single endpoint has significant write scalability limitations and global applications must endure the network round trip to the region where the write node is located in order to execute an operation. These geographic latencies imply a significant performance impact on users outside the region where the write node resides.This is a huge issue for global performance.
What is Amazon Aurora Multi-Master?
Amazon Aurora Multi-Master's offering allows for a second write node, but disallows read replicas. It is available in eight regions. It’s only available for MySQL, and in its current incarnation, can only be deployed in a single region (an issue for global availability and performance). Multi-master doubles the maximum write throughput at the expense of significantly decreased maximum read throughput. In fact, reads can only be completed through these two nodes and it requires you to think through which endpoint you want to query within your application. This also means, there is no option to scale reads to an additional region. The diagram shows the max deployment for the current release.
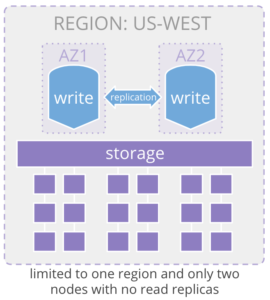
The AWS documentation points out additional limitations of their multi-master product, as well as use cases that this version of Aurora is good for. Aurora multi-master does not allow for SERIALIZABLE isolation.
While Aurora continues to improve, its architecture is decades old and was not designed to support scalable inter-regional operation. Aurora’s architecture will likely limit multi-master to be single region forever, as it requires communicating with all write nodes during every read to avoid staleness. The cost of providing consistency increases with the addition of each additional write node. Adding support for additional regions to the multi-master architecture would increase complexity and the introduction of geographic latencies would significantly impact performance.
Does Amazon Aurora provide global availability?
"Global Availability" requires that the database leverage geographic diversity of nodes to keep data available. It means more than just two regions around the planet. Let's evaluate the set of Aurora product offerings in light of our three requirements for global operation defined above.
First and foremost, Aurora is hardly “global” as it (currently) only allows you to extend the secondary read replicas into only one additional region, however they intend to open this to additional regions. Also note that when you spin up the second region, you incur charges for replicating data to this new region. So, with Aurora you have to carefully select which regions you deploy in to ensure coverage with reasonable latencies and watch your costs.
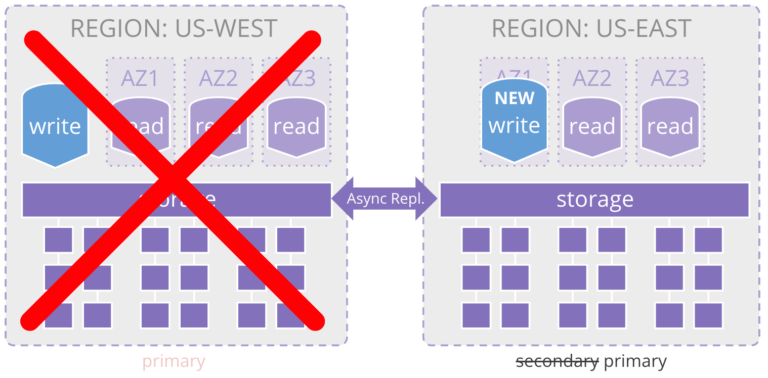
This architecture also leaves room for extended RPO/RTO. When a write node fails, Aurora will promote a read node to be a write node and this takes about a few minutes to happen. Non-zero RPO means data loss. If that’s not acceptable for your workload, Aurora isn’t acceptable for your workload.
Also, an RPO measured in minutes is acceptable for some workloads but not all. However, when a region fails, there is additional time added to the RPO clock. If an entire region fails (a rare occurrence, but possible), Aurora is smart enough to make sure a new write node is spun up in the secondary region and promote it to primary. This process takes minutes and during this time you have an unknown state of your data. For the time you're offline, you lose data. Once you're back online with the primary, you'll need to sync data and clear issues.
Does Amazon Aurora provide global performance?
Two issues plague Aurora when it comes to providing global performance. First, as noted above, they depend on a single write node for all global writes and second, they can only extend read replicas to one other region. (Multi-master is not acceptable to consider as it is only two endpoints and single region) This architecture stresses performance when it comes to physical latencies.
Amazon Aurora performs well in a single region and is durable to survive failures of an availability zone. However, there can be latency issues with writes because of the dependence on a single write instance. The distance between the client and the write node will define the write latency as all writes are performed by this node. Let’s consider a deployment where you have an instance of Aurora running in Richmond. For users on the east coast they will experience low latency read/writes however across the country in LA, we can expect at a minimum up to a 70ms latency.

With Aurora, we could extend it to another region so that we have better read performance across the two regions, however, writes will still be single threaded and incur the same performance expectations. It might be good enough, but what happens once you go global? If we locate the write instance in Richmond, can we cover users in Sydney with acceptable write latencies?
Finally, in order to truly provide global performance, you will ultimately need your data to live closer to where it is needed. Even with a truly distributed database, this is incredibly important as you try to attain millisecond read AND write latencies. And having some mechanism in the database to anchor data to a particular location becomes important for complex regulatory and varied compliance requirements that are present in a global implementations. Aurora does not provide this capability.
Does Amazon Aurora provide global consistency?
Global consistency requires that the database maintain consistency even in a globally dispersed deployment. Aurora drives consistency of data through their storage layer which ensures quorum by writing 4 of 6 replicas to disk. They also rely on isolation levels that can be set in the write node as part of standard MySQL and PostgresSQL execution layers they have commandeered. By default, they provide READ COMMITTED (PostgresSQL) or REPEATABLE READ (MySQL) isolation which could present issues with write skews and dirty reads. Further, replication to a secondary node is “typical latency of under a second”, so there is always risk of a dirty read regardless of the platform, even with serializable isolation on.
As noted above, AWS has added a multi-master capability but if you choose that type of deployment, you lose all the other benefits of Aurora. Further, they do not offer serializable isolation within this deployment type and again, it will incur performance hurdles.
What is the cost and performance of Amazon Aurora vs CockroachDB?
Beyond scale, performance and consistency, it is also important to consider the cost of a global database. In order to get cost numbers, we have executed some benchmarks against various instance types of Aurora. Benchmarking is a tricky topic but one that we at Cockroach Labs take seriously. We go to great lengths to make sure that what we measure is reasonable and aligned with some public facing standard. Internally, we rely on a few benchmarks and the TPC-C benchmark is one of them.
And while no benchmark is perfect, we hope this is at least directionally correct. We are always open to comment on these and highly suggest you benchmark these solutions for yourselves.
There’s a low ceiling on what Amazon Aurora can handle for OLTP workloads. We ran a TPC-C like workload on the smallest machines that could achieve 85% of the maximum TPC-C throughput, with these results:.
TPC-C 1k Results
TL;DR Not only does CockroachDB offer the lowest price for OLTP workloads, it does so while offering the highest level of consistency. To get a better understanding of the numbers, check out this blog post about the price of running OLTP workloads in CockroachDB and Aurora. In short, the CockroachDB cost includes 3 machines, as well as a DBA's salary to monitor and maintain the cluster.
For this comparison, we began by simply adapting our TPC-C suite to leverage both Postgres and MySQL compatible APIs, without modifying their isolation levels (REPEATABLE READ for MySQL; READ COMMITTED for Postgres).
Interestingly, Aurora's PostgreSQL compatible databases were able to run on the smallest machines, which lead us to assume they'd be the most cost efficient; however, when we observed that the Aurora billing was largely dominated by I/O costs. We believe the implementation of the Aurora Postgres interface doesn't seem to have received the same kind of optimizations that Aurora MySQL implementation has. In fact, 90% of the cost of running TPC-C on Aurora PostgreSQL was I/O related.
So, despite Aurora MySQL requiring larger machines, at the default isolation level, the cost was much lower than PostgreSQL (although still much higher than CockroachDB).
The previous examples relaxed isolation levels within Aurora. So, we ran our test suite against Aurora MySQL to complete TPC-C 1k at SERIALIZABLE isolation as this is the default level of isolation within CockroachDB. Some feel higher isolation levels will unequivocally destroy your performance. However, with Aurora, throwing more processors at the problem solves it. The downside to this, though, is that it dramatically increases the amount of I/O required. It seems the culprit is the Aurora MySQL deadlock mechanism which continually causes transactions to have to restart, which results in a substantial increase in activity going back to disk (i.e. consuming I/O).
Ultimately, we are not Aurora experts, so the above should be consumed with caution, however, it does outline some of the key issues and we wanted to provide a tangible and reasonably pragmatic comparison of not only the architecture but also the costs of Aurora.
Two Essential Constraints for a Global Database
A true global database--that is, one that’s globally available, performant, and consistent--shouldn’t have to fight against 6-way replication. It should offer serializable isolation, low latency, and non-zero RTO. A true global database doesn’t battle against the constraints of its architecture. It battles against two facts of life:
Everything will fail, and you need to prepare for that
The speed of light is constrained.
If you’re shopping for a ‘global’ database that’s sacrificing performance, availability, or consistency for anything but these two bullet points, you need to re-evaluate whether it’s really as ‘global’ as it claims to be.
CockroachDB was conceived of as a global database from the very beginning and we have a very deliberate and sharp focus on these two challenges. Every node is a consistent gateway to the entire database and provides both read/write access while guaranteeing reliable performance and serializable isolation at any scale.


