

This article is the latest in “Mainframe to Distributed SQL”, an original series from Cockroach Labs exploring the fundamentals of mainframes and the evolution of today’s distributed database architecture. Please visit here for the other installments:
Mainframe systems have long been the backbone of enterprise computing, known for their reliability, scalability, and unmatched processing power. As businesses strive to modernize their IT infrastructures, understanding the fundamentals of mainframe database architecture becomes crucial.
In the prior article in this series, we highlighted the enduring legacy of mainframe systems and their pivotal role in enterprise computing. We explained how mainframes had lasted so long, and why it’s essential to modernize them towards a distributed and cloud-native alternative.
This article delves into the intricate world of mainframe data storage, exploring the architectural components of traditional mainframe databases. We will examine their strengths and limitations, while evaluating performance, scalability, and operational challenges. Additionally, we will illustrate these concepts with real-world examples, highlighting the diverse use cases and industries that rely on mainframe databases.
Storage: different levels of abstraction
“Storage” means different things to different users. When we talk about storage, some people think about how data is stored physically; some focus on the raw material that holds the storage systems, while others think about the relevant storage system or technology for their use case. All these levels are important attributes of storage, but they focus on different abstraction levels.

Mainframe Storage Abstractions
Storage is ubiquitous, which makes it easy to overlook its significance. For example, many software and data engineers use storage daily, yet may lack knowledge of how it operates and the tradeoffs involved with different storage media.
For instance, mainframe systems support many different devices for data storage. Disks or tape are most frequently used for long-term data storage. What is a hard disk drive? A disk drive comprises a stack of circular disks coated with magnetic material for data storage. Each disk has a central hole for mounting on a spindle, allowing it to spin rapidly. The surface of each disk is divided into tracks, and each track is further divided into cylinders. A disk drive uses an actuator to move a read/write head to a specific sector to access data. This process is guided by the memory address of each sector, ensuring precise data retrieval.
In the mainframe universe, disk drives are called Direct Access Storage Devices (DASD), pronounced "Dazz-Dee." For instance, when you work on a typical PC system, the finest granular unit in the drive disk is called a “File.” The file represents a long string of bytes, often delimited to indicate the beginning and end of certain types of data to the OS.
But a mainframe has a different approach. The mainframe OS manages data using datasets. What are datasets? The term dataset refers to a file that contains one or more records. A record is the basic unit of information used by a program running on mainframes.
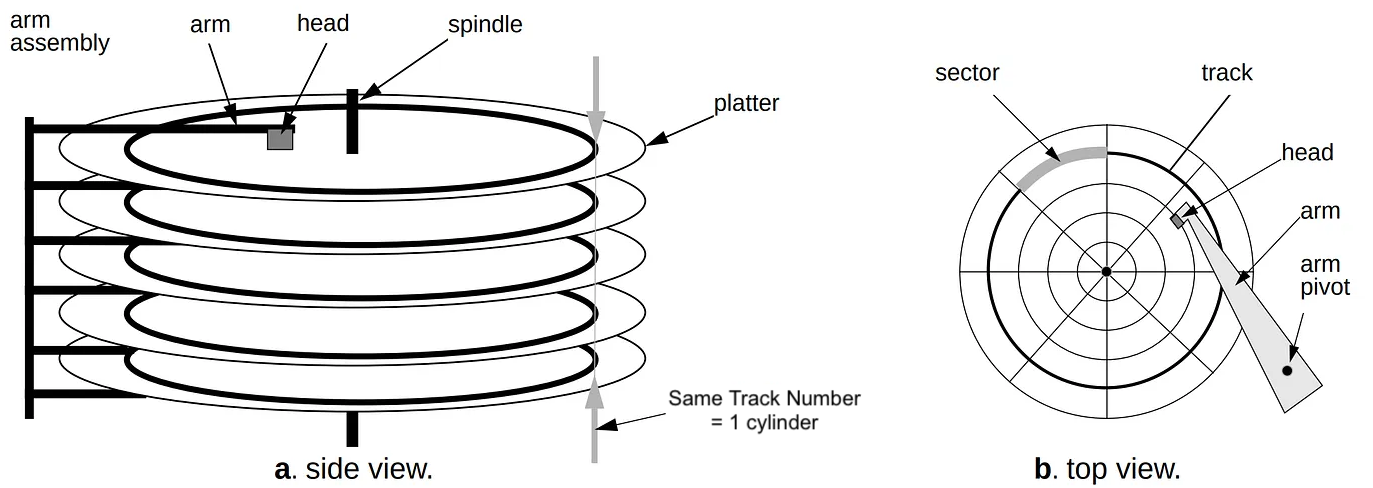
A record is a fixed number of bytes containing data. Often, a record collects related information treated as a unit, such as one item in a database or personnel data. The term field refers to a specific portion of a record used for a particular data category, such as an employee's name or department.
The records in a dataset can be organized in various ways, depending on how we plan to access the information. For example, If you write an application program that processes personnel data, your program can define a record format for the personnel data.
A dataset can be organized in the mainframe in many different ways. Among the most commonly used types are:
Sequential Data Sets (SDS) consist of records stored consecutively. For example, the system must pass the preceding nine items to retrieve the tenth item in the dataset. Data items that must all be used in sequence, like the alphabetical list of names in a classroom roster, are best stored in a sequential dataset.
Partitioned Data Sets (PDS) consist of a directory and members. The directory holds the address of each member and thus makes it possible for programs or the operating system to access each member directly. Each member, however, consists of sequentially stored records. Partitioned datasets are often called libraries. Programs are stored as members of partitioned datasets. Generally, the operating system loads the members of a PDS into storage sequentially, but it can access members directly when selecting a program for execution.

In IBM z/OS®, you can manage successive updates of related data through generation data groups (GDGs). Each dataset in a GDG is a generation dataset (GDS), and these sets are organized chronologically. GDGs can consist of datasets with similar or different data center bridging, attributes, and organizations. If identical, they can be retrieved together. GDGs offer advantages such as:
a common reference name
automatic chronological ordering
automatic deletion of obsolete generations
GDG datasets have absolute and relative names indicating their age, with base entries allocated in a catalog for the organization.
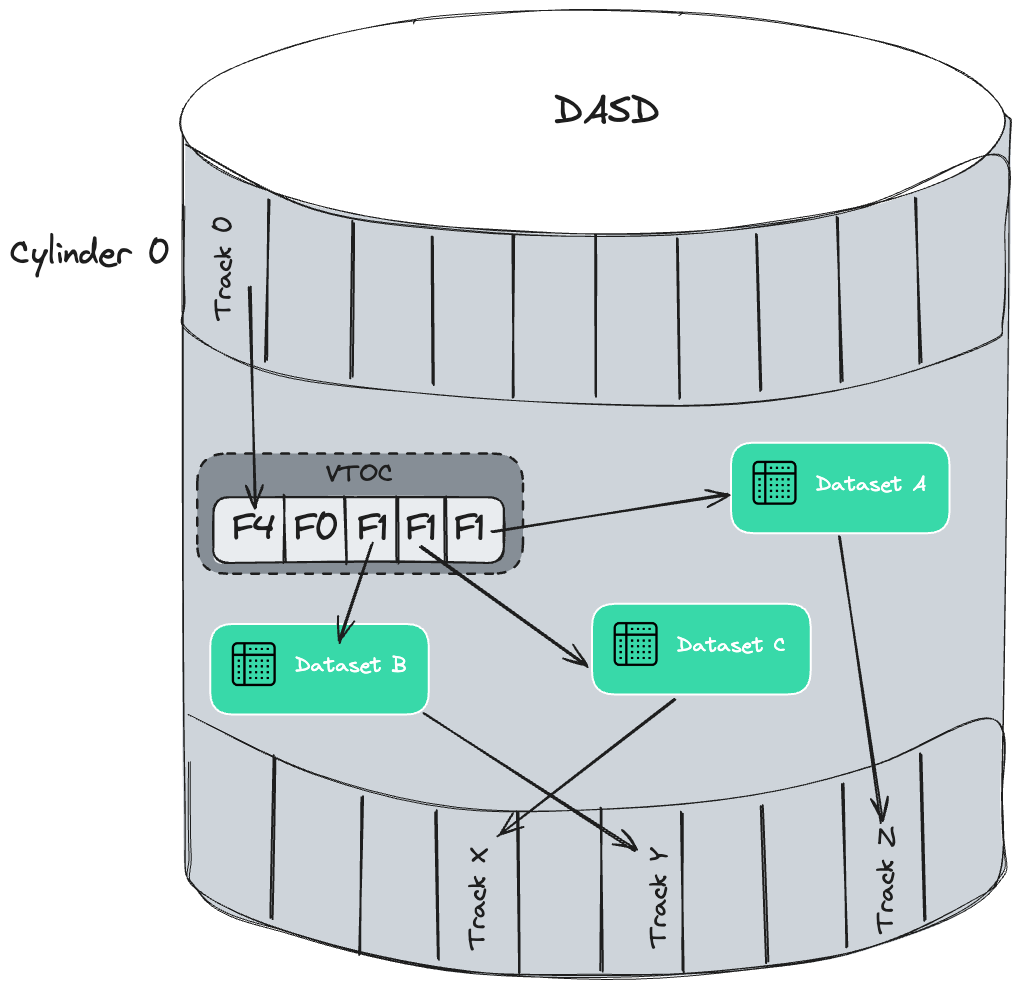
Although some datasets might be stored sequentially, DASDs can handle direct access. A DASD connects to the mainframe via arrays, employing caching to enhance speed and controllers to manage processing and system sharing.
To locate a specific dataset quickly, the mainframe uses a catalog system and VTOC (volume table of contents) that tracks its locations. In practice, almost all disk datasets are cataloged. One side effect is that all (cataloged) datasets must have unique names.
An access method defines the technique used to store and retrieve data. Access methods have their own dataset structures to organize data, system-provided programs (or macros) to describe datasets, and utility programs to process datasets.
Commonly used access methods include the following:
QSAM (Queued Sequential Access Method) is a heavily used access method. QSAM arranges records sequentially in the order that they are entered to form sequential datasets, and anticipates the need for records based on their order. The system organizes records with other records. To improve performance, QSAM reads these records into storage before they are requested, a technique known as “queued access”.
BSAM (Basic Sequential Access Method) is used for exceptional cases. BSAM arranges records sequentially in the order in which they are entered.
BDAM What is BDAM? (Basic Direct Access Method) arranges records in any sequence your program indicates and retrieves records by actual or relative address. If you do not know the exact location of a record, you can specify a point in the dataset where a search for the record is to begin. Datasets organized this way are called “direct datasets”.
BPAM (Basic Partitioned Access Method) arranges records as members of a Partitioned Data Set (PDS) or a Partitioned Data Set Extended (PDSE) on DASD. You can use BPAM to view a UNIX directory and its files similarly to a PDS. (You can view each PDS, PDSE, or UNIX member sequentially with BSAM or QSAM.)
VSAM (Virtual Sequential Access Method) combines a dataset and an access method. It arranges records by an index key, relative record number, or relative byte addressing. VSAM is used for direct or sequential DASD processing of fixed-length and variable-length records. Data organized by VSAM is cataloged for easy retrieval.
Access methods are identified primarily by the dataset organization. For instance, Sequential Data Sets (SDS) are accessed using BSAM or QSAM with sequential datasets.
However, an access method identified with one dataset structure can be used to process another dataset structured differently. For example, a sequential dataset created using BSAM can be processed using BDAM and vice versa. Another example is UNIX files, which you can process using BSAM, QSAM, BPAM, or VSAM.
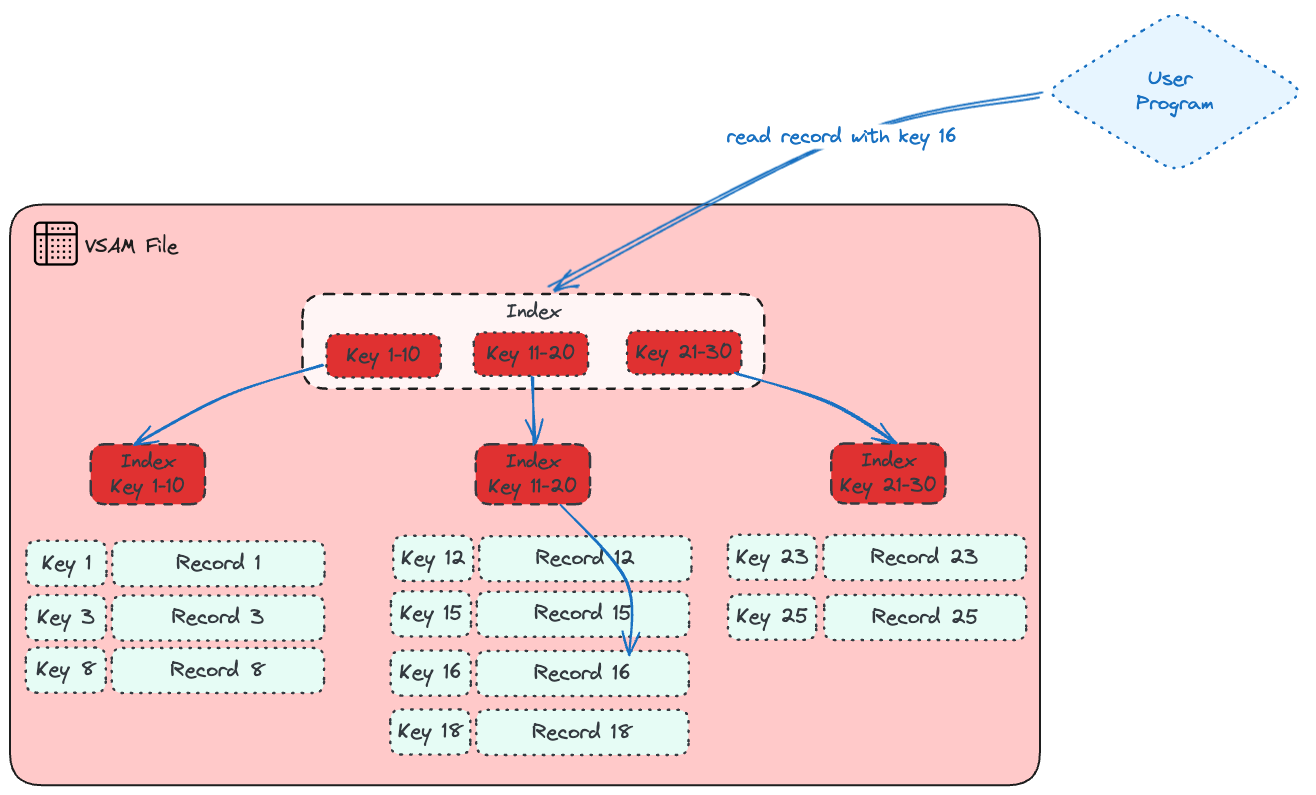
You can use VSAM to organize records into four types of datasets: key-sequenced, entry-sequenced, linear, or relative record. The primary difference among these dataset types is how their records are stored and accessed. VSAM datasets are briefly described as follows:
1—Key Sequence Data Set (KSDS): This type is the most common use for VSAM. Each record has one or more key fields, and a record can be retrieved (or inserted) by key value. You can access records randomly and use variable-length records. KSDS is sorted by a key field, which makes processing more efficient. This is why hierarchical databases like IMS use KSDSs.
2—Entry Sequence Data Set (ESDS): This form of VSAM keeps records in sequential order. Records are identified by a physical address, and storage is based on the order in which they are inserted into the dataset. However, deletion is not allowed, and since there is no index, duplicate records can exist. ESDS is common in IMS, DB2, and z/OS UNIX.
3—Relative Record Data Set (RRDS): This VSAM format allows retrieval of records by number. It shares many of the functions of ESDS. However, a significant difference is that records are accessed using the Relative Record Number (RRN), which is based on the location of the first record. It provides random access and assumes the application program can derive the desired record numbers. Note that the records are of fixed length, and deletion is allowed.
4—Linear Data Set (LDS): This type is, in effect, a byte-stream dataset. IBM Db2 and several mainframe system functions use this format heavily, but application programs rarely use it.
Several additional methods of accessing data in VSAM are not listed here. Most applications use VSAM for keyed data.
Yet there are some drawbacks to VSAM. They include:
You can only use VSAM on a DASD drive, not tape drives. But then again, tape drives are not used much anymore.
Another limitation is that a VSAM can have higher levels of storage requirements. This is because of the need for more overhead for its functions.
Finally, the VSAM dataset is proprietary, which means it is not readable by other access methods. For instance, you cannot view it using Interactive System Productivity Facility (ISPF) unless you use special software.
Batch vs. Online Transaction Processing
What is batch processing? Batch processing on a mainframe computer involves processing large amounts of data in groups – a.k.a. batches -- without requiring user interaction. This method is frequently used for performing repetitive tasks like backups, filtering, and sorting, more efficiently than if they were run on individual transactions.
In the early days of mainframes, batch processing emerged as the predominant data processing approach. For instance, one common practice involved accumulating data over a specific timeframe, such as business hours, and processing it during off-peak hours, typically at night when activity was minimal. Another typical scenario was payroll processing, where data would be gathered for weeks and processed at the period's end.
Batch processing, renowned for its cost-effectiveness in managing large data volumes, remains a prevalent practice in mainframe environments. However, certain activities like credit card payments or retail stock management must be processed in real time. This kind of processing gave birth to what we know as online transaction processing (OLTP).
Transaction characteristics
What is OLTP? This is a class of software applications which are capable of supporting transaction-oriented programs. OLTP is used by organizations that require efficient means to store and manage vast amounts of data in near real-time, while also supporting many concurrent users and transaction types.
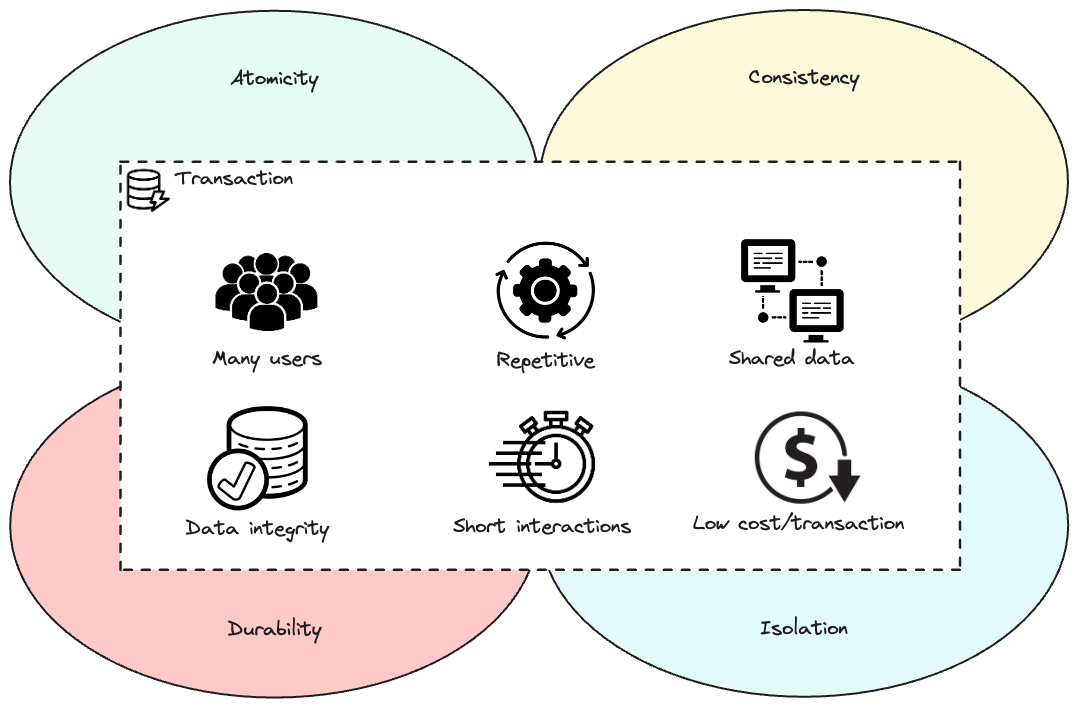
In an OLTP system, the user will perform a complete business transaction through short interactions, with immediate response time required for each interaction (sub-milliseconds in some cases). These are mission-critical applications; therefore, continuous availability, high performance, data protection and integrity are prerequisites.
In a transaction system, transactions must comply with four primary requirements known jointly by the mnemonic A-C-I-D or ACID. CockroachDB, for example, is an ACID-compliant database. ACID in database stands for:
Atomicity. The processes performed by the transaction are done as a whole or not at all.
Consistency. The transaction must work only with consistent information.
Isolation. The processes coming from two or more transactions must be isolated from one another.
Durability. The changes made by the transaction must be permanent.
OLTP systems have been instrumental in driving economic growth by reducing reliance on paper-based files. In the following sections, we’ll present a few transaction processing facilities, including batch and online systems, that were used and are still used in thousands of top companies worldwide.
Customer Information Control System (CICS)
In the early days, CICS, sometimes pronounced as "KICKS", was bundled with IBM hardware, leading to the first example of open-source software. CICS stands for "Customer Information Control System." It is a general-purpose transaction processing subsystem for the z/OS operating system. CICS provides services for running an application online by request, as do many other users who submit requests to run the same applications using the same files and programs.
CICS applications are traditionally run by submitting a transaction request. Execution of the transaction consists of running one or more application programs that implement the required function. In CICS documentation, you may find CICS application programs sometimes simply called "programs," and sometimes the term "transaction" is used to imply the processing done by the application programs.
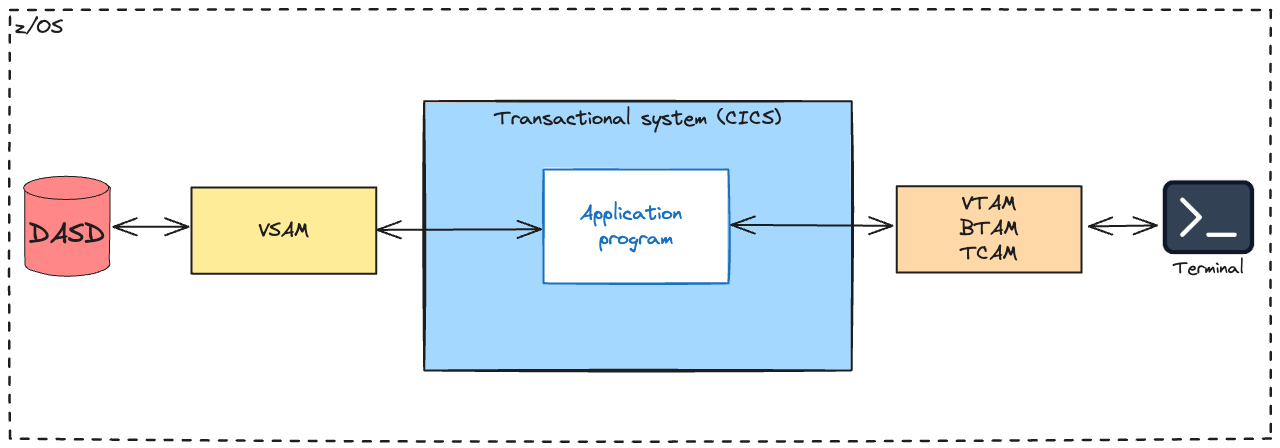
In the z/OS environment, a CICS mainframe installation comprises one or more "regions" spread across one or more z/OS system images. Although it processes interactive transactions, each CICS region is usually started as a batch job. Each CICS region comprises one major task on which every transaction runs, although certain services, such as access to IBM Db2 data, use other tasks.
Within a region, transactions are cooperatively multitasked – they are expected to be well-behaved and yield the CPU rather than wait. CICS services handle this automatically. CICS easily supports thousands of transactions per second (TPS) on IBM Z servers, making it a mainstay of enterprise computing.
Each unique CICS "Task" or transaction is allocated its own dynamic memory at start-up. Subsequent requests for additional memory are handled by a call to the "Storage Control program" (part of the CICS nucleus), which is analogous to a traditional OS: It manages the sharing of resources, the integrity of data, and prioritization of execution, with fast response. CICS authorizes users, allocates resources (storage and cycles), and passes forward database requests by the application to the appropriate database manager (such as DB2).
Originally, CICS was used to process input from terminals. However, the technology has evolved to integrate devices and interfaces. For example, CICS works seamlessly with smartphones, web services, etc. The platform is unique in the technology world in terms of its scale, speed, and capabilities.
The prime users of CICS are Fortune 500 companies that rely on rapid online transaction processing as a mission-critical core of their business. CICS users involve insurance companies, telecommunications companies, governments, airlines, the hospitality industry, banks, stock brokerage houses, and credit card processing companies.
This benchmark evaluates back-end processing for a retail application scenario involving shopping from an online catalog. During a sales promotion, the retailer must be able to handle a very high volume of requests simultaneously throughout the day. The retail catalog is held in a recoverable CICS-maintained shared data table, backed by a Virtual Storage Access Method (VSAM) key-sequenced dataset (KSDS) file.
The benchmark conclusion explains that CICS can execute up to 227,000 CICS TPS with 26 CPUs (LPAR in z13). It demonstrates how the CICS Transaction Server can scale to handle workloads with notably high transaction rates, while retaining the reliability and efficiency demanded by enterprise businesses.
Information Management System (IMS)
IBM's Information Management System (IMS) was developed in the mid-1960s to meet the Apollo space program's need for efficient accounting management of space module construction, which involved over two million parts. The system was marketed with the slogan "The world depends on it," a statement that proved true beyond typical tech marketing. IMS quickly became a corporate standard and remains extensively used by Fortune 500 companies today, handling over 50 billion transactions daily1.
The IMS database management system (DBMS) introduced the idea that application code should be separate from the data. Before IMS, a mainframe application would meld the coding and data into one. But this proved to be unwieldy, such as with duplicate data and the need for reusability. A key innovation for IMS was to separate both of these parts. IMS controls the access and recovery of the data. Application programs can still access and navigate the data using the DL/I standard callable interface.

The main components of IMS
This separation established a new paradigm for application programming. The application code could now focus on manipulating data without the complications and overhead associated with accessing and recovering it. This paradigm virtually eliminated the need for redundant copies of the data. Multiple applications could access and update a single data instance, thus providing current data for each application. Online access to data also became more straightforward because the application code was separated from data control.
The IMS Database Manager handles the core database functions, such as storing and retrieving the information. The IMS Transaction Manager is an online system that processes large amounts of transactional data from terminals and devices. This is handled by using a system based on queues.
The IMS Database Manager is a hierarchical database system that organizes data into various levels, from general to specific. It manages essential database operations such as the storage and retrieval of information.
For instance, the structure would look like the figure below if you want to design a hierarchical database for a company's departments:
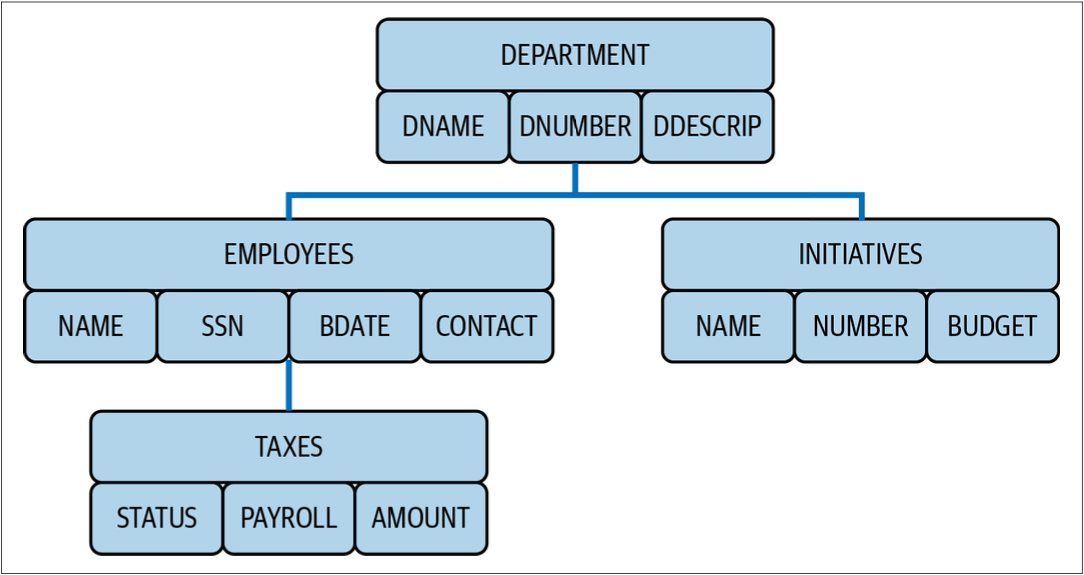
An IMS model
You may be wondering why you should use a hierarchical database. IMS is one of the rare databases capable of running over 117,000 database update transactions per second1. This exceptional speed is mainly due to the inherent nature of hierarchical databases, where relationships are predefined within the hierarchy, eliminating the need for extra processing to establish these connections.
IMS also comes with some built-in mainframe benefits, such as a long history of reliability, security, scalability, and less disk space and CPU power usage. IMS has a relatively low cost-per-transaction.
On the other side, the first obvious drawback of IMS is that hierarchical databases can be complicated to set up, especially for data schemas involving multiple levels of depth. Another area for improvement is that it is difficult to make changes after the initial structure is created. This is because remapping the relationships is required, which can be time-consuming.
Integrated Database Management System (IDMS)
IDMS, or Integrated Database Management System, is a DBMS for mainframes developed by Cullinet, which was later acquired by Computer Associates (known as CA Technologies). IDMS is primarily used to manage large-scale, high-performance applications requiring robust data handling and processing capabilities.
One of the advanced features of IDMS was its built-in Integrated Data Dictionary (IDD). The IDD was primarily designed to maintain database definitions and was itself an IDMS database. Database administrators (DBAs) and other users interacted with the IDD using Data Dictionary Definition Language (DDDL). Additionally, the IDD was used to store definitions and code for other products in the IDMS family, such as ADS/Online and IDMS-DC. The extensibility of the IDD was one of its most powerful aspects, allowing users to create definitions for virtually anything. Some companies even utilized it to develop in-house documentation.
Unlike relational databases that use tables, IDMS uses the CODASYL network model structure. The main structuring concepts in this model are records and sets. Records essentially follow the COBOL pattern, consisting of fields of different types, which allows complex internal structures such as repeating items and repeating groups.

An IDMS model
The most distinctive structuring concept in the Codasyl model is the set. Sets represent the one-to-many relationships between records: one owner and many members. This allows complex data relationships to be efficiently managed through sets and record types, providing fast data retrieval and update capabilities.
IDMS is designed for high transaction processing performance, making it suitable for mission-critical applications in banking, insurance, and government industries. This processing performance is due to how data is stored in IDMS. IDMS organizes databases into a series of files mapped and pre-formatted into designated areas. These areas are further divided into pages corresponding to physical blocks on the disk, where the database records are stored.
The database administrator (DBA) allocates a fixed number of pages within a file for each area and defines which records will be stored in each area, including how they will be stored. IDMS includes particular space allocation pages throughout the database to track available free space on each page. To minimize I/O requirements, the free space is monitored for all pages only when the free space for the entire area drops below 30%.
On the other hand, the network model of IDMS can be more complex to design and manage than relational databases, requiring specialized knowledge and skills. Learning and mastering IDMS can be challenging, particularly for new users who are more familiar with an RDBMS – RDBMS stands for relational database management systems.
What is RDBMS? This is a type of database management system that stores data in a structured format, using rows and tables, making it possible to identify and access data in relation to other pieces of data in the database. CockroachDB is an example of RDBMS (although as a distributed SQL database it is more than that, since it combines the benefits of traditional RDBMSs with the scalability of NoSQL databases.)
Adaptable Database System (ADABAS)
ADABAS (Adaptable Database System) is a high-performance, high-availability database management system (DBMS) developed by Software AG. It is designed to handle large volumes of transactions and is commonly used in mainframe environments for mission-critical applications.
ADABAS differs from relational databases in many aspects. For example, ADABAS stores many data relationships physically, reducing CPU resource demands compared to relational databases that establish all relationships logically at runtime.
ADABAS uses an inverted list architecture rather than a traditional relational database model. This structure allows for efficient data storage and retrieval, particularly in applications with complex queries and large datasets. ADABAS is thus optimized for fast data retrieval and high transaction throughput, making it suitable for applications that require quick response times and can handle millions of transactions per second. It can manage large databases with extensive data volumes and support many concurrent users, making it scalable for enterprise-level applications.
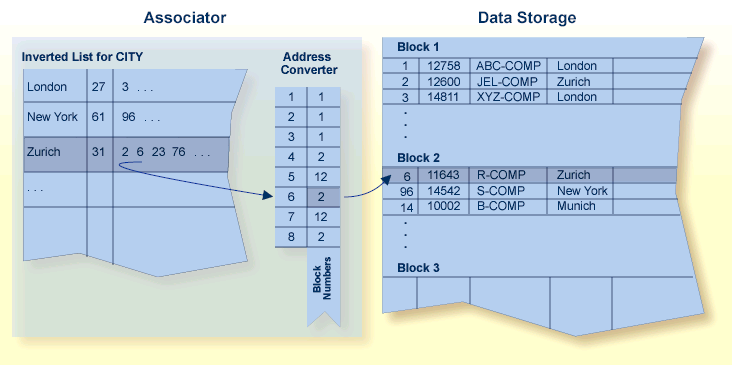
ADABAS’s observed high performance is due to its underlying storage architecture. In ADABAS, data is divided into blocks, each identified by a 3- or 4-byte relative ADABAS block number or RABN, that identifies the block's physical location relative to the beginning of the component. Data Storage blocks contain one or more physical records and a padding area to absorb the expansion of records in the block.
A logical identifier stored in the first four bytes of each physical record is the only control information stored in the data block. This internal sequence number, or ISN, uniquely identifies each record and never changes. When a record is added, it is assigned an ISN equal to the highest existing ISN plus one. When a record is deleted, its ISN is reused only if you instruct ADABAS to do so. Reusing ISNs reduces system overhead during some searches and is recommended for files with frequently added and deleted records.
For each file, between 1-90 percent (default 10%) of each block can be allocated as padding based on the amount and type of updating expected. This reserved space permits records to expand without migrating to another block and thus helps to minimize system overhead.
ADABAS separates data relationships, management, and retrieval from the actual physical data, storing the physical data independently. This system offers flexible access techniques, enabling simple and complex searches to be performed quickly and efficiently. The independence of data from the program minimizes the need for reprogramming when the database structure changes.
ADABAS offers features such as data replication, backup and recovery, and failover mechanisms to ensure high availability and data integrity, even during hardware or software failures. It includes advanced indexing, data compression, and dynamic buffer management to enhance performance and efficiency.
While traditionally used on mainframes, ADABAS supports multiple platforms, including Linux, UNIX, and Windows, providing flexibility in deployment. Many organizations continue to use ADABAS because of its reliability and performance in legacy systems. It has a strong presence in finance, government, and healthcare industries, where robust data management is crucial.
Datacom/DB
Datacom DB is a high-performance, enterprise-level database management system (DBMS) developed in the early 1970s by Computer Information Management Company. Datacom was acquired by CA Technologies (formerly Computer Associates), which renamed it to CA Datacom/DB.
Datacom was initially designed to retrieve data quickly from massive files using inverted lists. While this approach was highly effective for rapid data retrieval, it could have been more efficient for handling extensive data maintenance. To address this issue, Datacom/DB transitioned to relational technology, incorporating unique index-driven capabilities that significantly improved maintenance without sacrificing retrieval speed. This relational version of Datacom became the foundation for ongoing industry-leading enhancements, maintaining its status as a cost-effective and high-performing DBMS for IBM mainframes.
Datacom DB is optimized for fast data retrieval and high transaction throughput, ensuring efficient handling of large-scale data processing. It can scale to support extensive databases and a large number of concurrent users, making it suitable for enterprise-level applications. The system supports both relational and non-relational data structures, offering data storage and access flexibility.
Datacom DB provides robust data integrity, backup, and recovery features, ensuring that data remains consistent and available even during system failures. It offers strong security features to protect data from unauthorized access and ensure compliance with regulatory requirements.
Datacom DB integrates well with various programming languages and platforms, providing a seamless application development and data management environment.
Db2
In 1983, IBM introduced Db2 for the MVS (Multiple Virtual Storage) mainframe platform, a significant advancement in the database market. Over the years, it has evolved to support various platforms, including Linux, UNIX, Windows, z/OS (mainframe), and iSeries (formerly AS/400).
Before this, databases primarily consisted of flat files or used models like hierarchical relationships, which were often difficult to modify.
Db2 stores data in various tables that are linked to form relationships. Each table is two-dimensional, consisting of columns and rows. The intersection of a column and a row is referred to as a “value” or “field”, which can be alphanumeric, numeric, or null.

Each row has a unique identifier, the primary key, which facilitates searching, updating, and deleting information. The primary key is automatically indexed in a relational database, but additional indexes can be created on other columns to enhance operation speed.
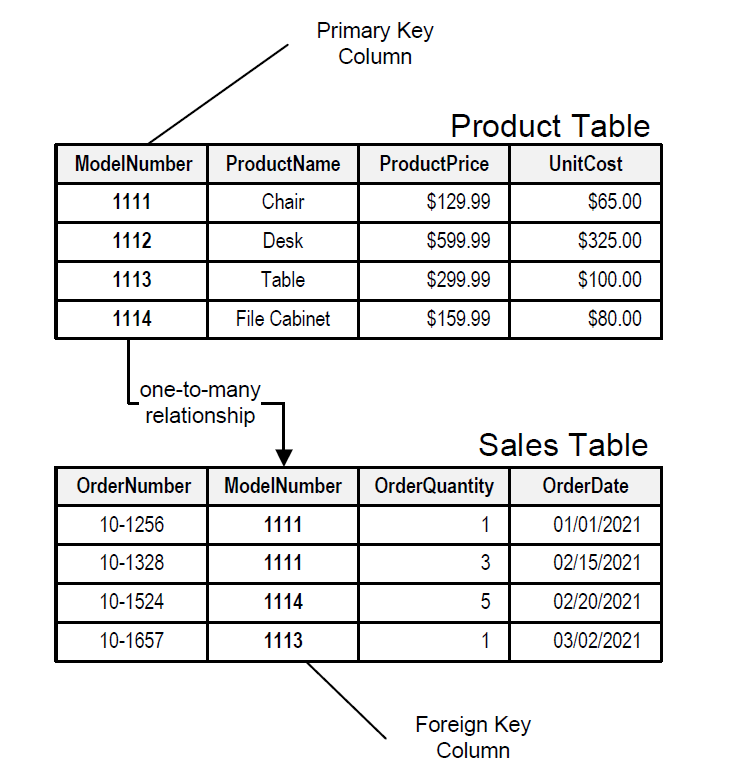
Primary keys enable the creation of relationships with other tables. A connection between tables is established using a value called the foreign key. This connection occurs when a column (the foreign key) in one table points to the primary key in another table.
One of the major advantages of Db2 is its versatility. This database supports multiple platforms and data models, making it adaptable to various business needs. It works well with other IBM products and third-party tools, enhancing its functionality and ease of use.
Db2 is optimized for high performance and can handle large-scale databases with complex queries and high transaction volumes. The platform is well-known for its robustness and reliability, essential for mission-critical applications. It is designed to scale efficiently across multiple platforms. It also offers advanced analytics capabilities, including support for in-database analytics and AI for enhanced analytical insights.
As per this benchmark study, Db2 (starting v11) provides many opportunities for reduced CPU use in simple online transaction workloads and more complex real-time analytics queries. Major bottlenecks were addressed to improve the scalability of applications concurrently inserting records into Db2 tables. To address the demand for high-volume ingestions, IBM introduced a new insert algorithm for tablespaces that do not require clustering. The new insert algorithm and another scalability improvement in log writes made it possible during an IBM-internal benchmark to reach 11.7 million inserts per second.
Db2 provides robust security features, including encryption, access control, and auditing, ensuring data protection and regulatory compliance. It includes features such as data replication, clustering, and failover to ensure high availability and quick recovery in case of system failures.
While IBM's Db2 is a robust and versatile database management system, it does have some drawbacks. The major one is its high licensing cost: Db2 can be expensive to license, especially for large enterprises with extensive usage. The cost can be a barrier for small to mid-sized businesses. Moreover, the need for skilled DBAs and the potential requirement for IBM support contracts can burden the overall cost of ownership.
While Db2 supports a wide range of platforms, integrating it with non-IBM systems and software can sometimes present challenges, requiring additional middleware or custom solutions. Db2 is tightly integrated with other IBM products, leading to vendor lock-in and making it difficult to switch to alternative solutions without significant effort and cost.
Db2 is widely used in various industries, including finance, healthcare, government, and retail, for enterprise resource planning (ERP), customer relationship management (CRM), and supply chain management (SCM) applications. Financial institutions use Db2 to handle large volumes of transactions and ensure data integrity and performance in critical applications like online banking and stock trading.
Db2 is also a data warehousing solution that provides efficient storage, fast query processing, and advanced analytical capabilities.
Real-world examples illustrating the diverse use cases and industries reliant on mainframe databases
Mainframe databases are critical in various industries, providing robust, high-performance data management solutions for complex, large-scale applications. Here are some real-world examples illustrating the diverse use cases and industries reliant on mainframe databases:
1. Banking and Financial Services
Transaction Processing: Large banks such as BNP Paribas, JP Morgan, or State Bank of India use mainframe databases like IBM's Db2 or Datacom DB to manage vast amounts of transactions efficiently. These large banks use the transactional systems presented earlier to process millions of daily ATM transactions, credit card payments, and online banking activities.
Customer Information Management: Financial institutions rely on mainframe databases like IMS or IDMS to store and retrieve customer data, ensuring quick access to account information, transaction history, and loan processing.
2. Insurance
Policy Management: Insurance companies use mainframe databases to handle policy details, claims processing, and underwriting. For instance, insurance providers such as AXA or Allianz use IMS or IDMS to manage millions of policyholder records and claims.
Risk Analysis and Actuarial Calculations: Mainframe databases support complex calculations and data analysis required for risk assessment and premium determination. Online risk data is hosted in VSAM files, and users usually access these applications through terminals via CICS command-level transactions. Background CICS transactions are also used for batch processing, risk analysis, and risk scores within the CICS environment.
3. Retail
Inventory Management: Large retailers like Walmart and Target use CICS applications to manage inventory across thousands of stores. These systems track real-time stock levels, sales data, and supply chain logistics.
Customer Loyalty Programs: French retailers like Auchan or Carrefour use mainframe databases, especially IBM’s Db2, to store and analyze customer purchase history, enabling personalized marketing and loyalty rewards programs.
4. Government
Social Security Administration (SSA): The French SSA (AMELI) relies on mainframe databases like IMS and ADABAS to manage records for millions of beneficiaries, including payments, eligibility, and personal information.
Tax Processing: Agencies like the IRS use CICS applications and Db2 to process tax returns, handle audits, and maintain extensive records securely and efficiently.
Other verticals use mainframe databases to manage and store critical business data. For example, hospitals and care providers use mainframe databases to process electronic health records (EHRs), ensuring secure and quick access to patient information. These systems are also used in medical research to handle large datasets for clinical trials, genetic research, and epidemiological studies, supporting data-intensive research activities.
These transactional systems are still used in air transportation to manage flight schedules, bookings, and passenger information. For example, American Airlines' SABRE system relies on a set of mainframe databases.
Moreover, manufacturing companies use mainframe OLTP systems to process end-to-end production data. This includes handling large volumes of data from production lines to monitor quality and identify defects in real-time, as well as production schedules, inventory levels, and supply chain logistics.
These are just a few examples highlighting mainframe databases' versatility and critical importance across various sectors. Their ability to handle large volumes of transactions, ensure data integrity, and provide high availability makes them indispensable in supporting the core operations of many industries.
The next step: modernizing to cloud-native
Mainframe databases continue to play a pivotal role in enterprise computing, offering unparalleled performance, reliability, and scalability for mission-critical applications across various industries. This article has explored the fundamental aspects of mainframe data storage, detailing the architectural components of traditional mainframe databases such as IBM's Db2, IMS, and VSAM, as well as systems like ADABAS, IDMS, and Datacom/DB. Each database system brings unique strengths and challenges, from the performance of the hierarchical IMS to the relational flexibility of Db2.
Key points that we discussed here include:
the different levels of storage abstraction
various dataset organizations
the specific access methods that optimize data retrieval and management on mainframes
We’ve also highlighted the transition from batch processing to online transaction processing (OLTP), emphasizing the need for real-time data handling in today’s fast-paced business environments.
Real-world examples demonstrate the critical role of mainframe databases in the banking, insurance, retail, government, and healthcare sectors. These industries rely on mainframes to handle large volumes of transactions, ensure data integrity, and provide high availability, making them indispensable to modern enterprise operations.
As organizations evolve, the modernization of mainframe systems towards cloud-native and distributed alternatives such as CockroachDB remains a key focus. Understanding the intricacies of mainframe database architecture is essential for leveraging the full potential of cloud-native and distributed database alternatives to successfully navigate the future of enterprise computing.
Learn how you can successfully migrate from mainframe to a cloud-native distributed database: Visit here to speak with an expert.
Amine El Kouhen, Ph.D., is Sr. Partner Solutions Architect at Cockroach Labs.
References
Tom Taulli, Modern Mainframe Development, O'Reilly Media, 2022.
What is a dataset? IBM Docs
Access Methods, CIO Wiki.
Introduction to CICS, IBM Docs.
CICS - CodeDocs.
IBM CICS Online Training, Proexcellency.
History of IMS: Beginnings at NASA, Informit
IDMS - Wikipedia.
IBM Db2 12 for z/OS Performance Topics, IBM Red Books.
Partitioned dataset Extended Usage Guide, IBM Red Books.
z/OS Basic Skills, IBM Docs
How it works: CICS resources, IBM Docs
O. Stevens, "The History of Datacom/DB," in IEEE Annals of the History of Computing, vol. 31, no. 4, pp. 87-91, Oct.-Dec. 2009, doi: 10.1109/MAHC.2009.108.


