

SQL has been the lingua franca for data for decades. Its enduring popularity is a testament to its rich functionality and strong consistency guarantees. With SQL’s widespread adoption have come a number of benefits, but there were some challenges, like scale and resilience, that contributed to the rise of NoSQL databases. Sharding has been a typical response to the scale challenge, but doing so introduces additional challenges such as giving up global transactional consistency and global indexes.
Today, distributed SQL databases are redefining what’s possible for modern, global businesses. By combining the familiarity and functionality of traditional SQL databases with the resilience and scale of NoSQL databases, you can trust your database to scale with your business. Recently, Peter Mattis, co-founder, CTO, and CPO of Cockroach Labs, and technical evangelist, Rob Reid, hosted a webinar called “The Magic of Distributed SQL: Zero Downtime & Infinite Scale.”
We were trying to simultaneously look for an architecture that could provide the SQL functionality people wanted, offer application developers the rich database features they needed, and seamlessly handle resilience and horizontal scalability.
– Peter Mattis, CTO & CPO of Cockroach Labs

While traditional databases have been patching up their existing architecture to try and meet modern demands, the discussion pointed out the potential mismatches with many traditional databases, which were built before commercialized AI use-cases and before smartphones introduced always available expectations.
Below, we recap the key ideas from the session and how they tie to the future of data infrastructure.
You can watch the whole conversation on our website: “The Magic of Distributed SQL: Zero Downtime & Infinite Scale.”
Inherent resilience means sleeping through the night
As more and more users expect 24/7 availability, the transactional load on data infrastructure grows, along with the negative impact of downtime on businesses. We recently published “The State of Resilience Report 2025,” which surveyed 1,000 senior technology leaders on what operational resilience looks like today and the impact of downtime. Here’s what we found:
100% reported experiencing outage-related revenue losses in the past year
On average, organizations are experiencing 86 outages a year
95% of executives surveyed are aware of existing operational vulnerabilities
93% of the executives expressed worry about downtime’s impact
Part of the problem is that traditional business continuity strategies focus on reacting after a failure has already occurred. For example, with a traditional SQL database, you may need a database operator to switch from a primary to a standby instance. While this can work, it often results in data loss (high RPO) and long recovery times (high RTO).
Measure what matters
Traditional benchmarks only test when everything’s perfect. But you need to know what happens when everything fails. CockroachDB's new benchmark, "Performance under Adversity," tests real-world scenarios: network partitions, regional outages, disk stalls, and so much more.
From the beginning, the engineering and product teams designed CockroachDB so that outages and failures would be “non-events,” just something you can see in a log, after you’ve slept through the night (even when on-call). With CockroachDB, resilience is inherent and constantly improving:
I don't see resilience as being some end state where there's perfect resilience. I see resilience as a bar that continually gets raised and we're chasing that bar being raised.
– Peter Mattis, CTO & CPO, Cockroach Labs
There are a number of ways that a system can fail. The simplest are the black and white failures where a component stops working and presents as such. But gray failures have become more problematic as systems have scaled, since that system component might seem healthy to parts of the system, but appear to fail in another (like a disk stalling without returning an error). Consider network partitions, where all the nodes can be healthy, but one or more are unable to communicate with the rest of the network, either in one (asymmetric) or both (symmetric) directions. A more modern solution, like distributed SQL, is necessary to remain resilient even in the face of gray failures; not only keeping the application running but ensuring the consistency and integrity of its data.
Watch the full webinar recording to hear how CockroachDB handles node outages, disk failures, and more. Check out our docs to learn more about how CockroachDB heals network partitions.
RELATED
Check out Rob trying to break CockroachDB via pod failures, network partitions, packet corruption, and so much more:
Database maintenance shouldn’t require downtime
Traditionally, there have been parts of the application lifecycle that are tedious or have required downtime, such as version upgrades, security patches, and schema changes. At Cockroach Labs, we challenge the notion that maintenance downtime is necessary.
CockroachDB’s rolling upgrades (and downgrades) enable customers to upgrade major, minor, or patch versions without shutting down or suffering service disruptions. In the webinar, Peter and Rob highlighted the built-in guardrails that ensure a simple and secure workflow so you feel confident upgrading your database.
In a similar vein, the Cockroach Labs team have made schema changes “business as usual.” As Peter discusses, perhaps your business has evolved since you first designed your database schema. Maybe your products have evolved or maybe you have new use-cases. Either way, there are many reasons why your schema could need an update. Altering tables or adding indexes can be essential for business agility, and you should not have to take your system down in order to make these changes.
With CockroachDB’s online schema changes, you can make updates live, at scale, and with zero impact to end-users. In the image below, you can see the positive impact of an online schema change against a customer cluster, which reduced latency, all while transaction volume held steady:
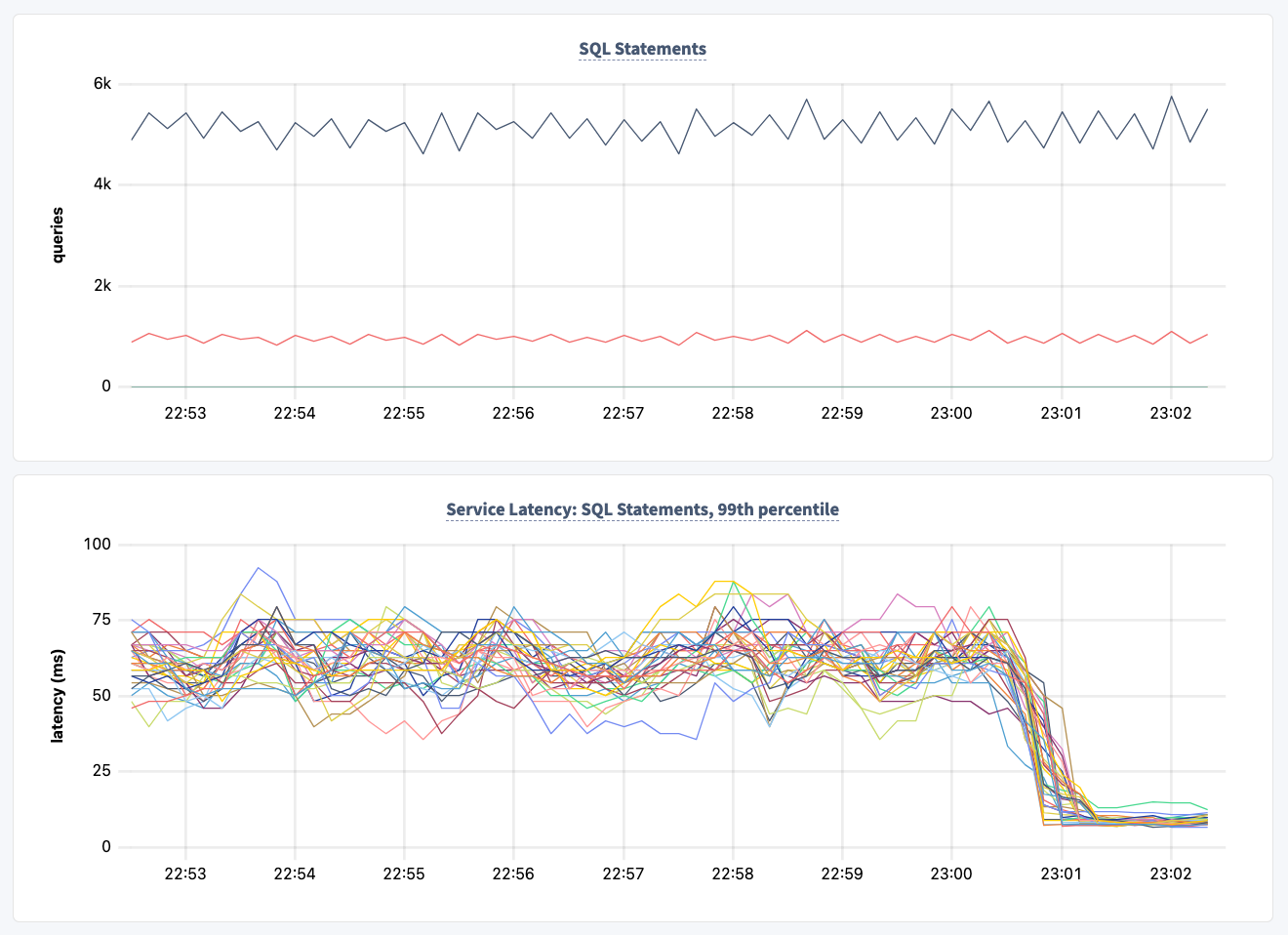
Our distributed jobs engine, MVCC (multi-version concurrency control), and admission control all combine to manage consistency, speed, and system impact.
Everything is natively distributed and subject to our admission control in CockroachDB. So if your cluster is running pretty hot and you want to run a schema change, you don't have to delay it because admission control will slowly make that schema change as part of a distributed job as opposed to absolutely crippling your cluster that's already busy.
– Rob Reid, Technical Evangelist at Cockroach Labs
Instantly scale up and back down

Transaction volume can vary wildly, particularly in industries that hinge on major events like Black Friday and Cyber Monday for eCommerce and Retail companies or the Super Bowl for betting platforms. Perhaps, as a SaaS company, you get spikes at certain times during the day. One of the most compelling advantages discussed in the webinar was CockroachDB’s ability to maximize operational efficiency by easily scaling up and down. Traditional databases often struggle with these dynamics, as scaling usually requires significant manual intervention, downtime, or overprovisioning and driving up costs even when capacity isn’t needed.
When scaling up, CockroachDB automatically absorbs the new nodes, rebalances data, and increases both read and write throughput. This happens without downtime, loss of data, or disruption to users. Once the traffic spike passes, businesses can simply decommission nodes, with CockroachDB handling the data rebalancing and maintaining cluster health behind the scenes. Resources and costs are right-sized at every point, minimizing unnecessary infrastructure spend.
FUN FACT: Peter mentions the largest cluster he’s seen in production at Cockroach Labs was a 210-node cluster with hundreds of terabytes of data…and they performed an online schema change during business hours.
Distributed SQL is for scaling businesses today
The bottom line? The audience’s most burning questions centered around resilience, multi-region flexibility, regular maintenance without downtime, and operational simplicity. These are all core advantages of distributed SQL and fundamental to CockroachDB. If you’re building for global scale, spiky workloads, or just want peace of mind against outages, you should consider a distributed SQL solution.
Ready to dive deeper? Watch “The Magic of Distributed SQL” webinar on-demand for more technical details and insights. See firsthand why CockroachDB makes operational resilience, database maintenance, and scaling business as usual.
Watch "The Magic of Distributed SQL"
Hear from Cockroach Labs co-founder Peter Mattis and Rob Reid, co-author of CockroachDB: The Definitive Guide, 2nd Edition on how distributed SQL makes resilience, scale, and regular database operations effortless.
Appendix: “The Magic of Distributed SQL” Webinar Q&A
Here, Peter and Rob have answered some audience questions, covering topics including how CockroachDB handles leaseholders, the single writer bottleneck traditional databases face, and more:
Determining the next leader in a cluster via Raft or Paxos can't be predicted in advance. Is there a way you address this algorithmically, without redundancy?
Every node in every CockroachDB cluster is both a leader and a follower for parts of the data stored in the cluster. And we do this at a fairly fine granularity, so we can move leaders and followers around in the cluster very dynamically. When you're connecting externally to the database, your application doesn't have to talk to the leader for a particular bit of data, it just talks to any node. And then there's internal routing that takes place in the cluster to go get the data.
CockroachDB nodes are architected like an ant colony. Every node in the cluster knows the data it's responsible for, as well as the data it is leaseholder over with respect to reads and writes. Each node is also aware of every other node in the cluster. The node knows if it has too much data and needs to rebalance to other nodes, and it knows if it needs to have more data to relieve the stress on other nodes. Now in the background, the nodes know if a node is unhealthy and if any kind of repairs need to occur. In addition, we use leader leases to manage leaseholders, which works in the background with elections. If a node is unhealthy and it has leases that serve data for reads and writes, other nodes in the cluster will be notified within seconds, and a new leader will be elected to take over the reads and writes for that data.
How does CockroachDB handle the traditional single writer bottleneck?
CockroachDB is architected very differently to traditional databases with a single write interface. Every node in CockroachDB is created equal and can handle reads and writes. That's how CockroachDB scales horizontally for both reads and writes. With regard to leaseholders as mentioned above, if you imagine a table that's split up into chunks by default, they're half a gigabyte in size. Those are called ranges. And ranges are replicated by default three times for a single region cluster, five times for a multi-region cluster. (You can configure this to your liking.) One of those replicas is nominated the leaseholder and that will orchestrate reads and writes for that particular range of data. Now, you can go to any replica if you use a follower read, that's another kind of performance boost that you can achieve in CockroachDB, but it's fundamentally different. There's no single point of write failure.
You mentioned WAL failover. Once you realize disk 1 is getting slow and you failover to Disk 2, what happens next? When do you start using Disk 1 again?
So when we failover to Disk 2, in that scenario we covered, we're continually trying to do these “canary writes” to Disk 1, to check if the disk is healthy or not. We have a latency threshold, and at some point running to Disk 1 will either go through or the latency will drop the threshold. We’ll copy a little bit of data back to the disk to ensure consistency and then we’ll fail back to Disk 1. All of this happens completely automatically. The operator doesn't have to do anything.
How is consistency handled during online schema changes?
Essentially, CockroachDB can run two versions of the same table and make the change against one of the tables before switching immediately to use the new version of the table. So it's instantaneous and doesn't result in any downtime. To ensure consistency, we make changes to both tables.






