

This article is co-authored by David Joy, Senior Sales Staff Engineer for Cockroach Labs, and Pranav Deshmukh, Partner Solutions Architect for AWS.
In the modern data-driven landscape, the ability to efficiently migrate and synchronize data across various platforms is crucial for enterprises. This is particularly true when dealing with high-volume transactions that need to be analyzed for patterns and insights. Anyone can use CockroachDB, with its distributed SQL capabilities, together with AWS Redshift, a leading data warehousing solution by Amazon Web Services, to analyze data and develop insights that are critical for developing cloud native data pipelines.
Integrating CockroachDB with Redshift is achieved via AWS’ cloud object storage service, Amazon S3, to unlock powerful data workflows, enhance analytical capabilities, and drive actionable insights. Let’s walk you through the process, showcasing how this integration can benefit your enterprise.
Why Integrate CockroachDB with AWS Redshift?
The integration of CockroachDB's transactional data with Redshift's scalable analytical engine enables real-time analytics, reporting, and business intelligence on current transactional data. Using CDC for this integration ensures that data transferred between CockroachDB and Redshift is up-to-date, minimizing latency and maintaining data integrity across systems. The intermediary role of Amazon S3 in this process ensures a reliable, scalable, and secure data lake solution that serves as a staging area for data before it's loaded into Redshift.
Benefits for Customers
Real-time Data Analysis: Leverage the latest transactional data for analytics and decision-making.
Scalability: Handle increasing data volumes effortlessly, with the scalable architectures of CockroachDB, S3, and Redshift.
Cost-Efficiency: Optimize costs by using S3 for intermediate data storage and taking advantage of Redshift's on-demand pricing.
Data Integrity: Ensure consistency and accuracy in your data across both transactional and analytical platforms.
Example Use Case : E-commerce Transaction Analytics
Imagine an e-commerce platform that uses CockroachDB to manage user transactions. By integrating this data with Redshift, the company can analyze purchasing trends, inventory turnover, and customer behavior in real-time, enabling more informed decision-making and a responsive business model.
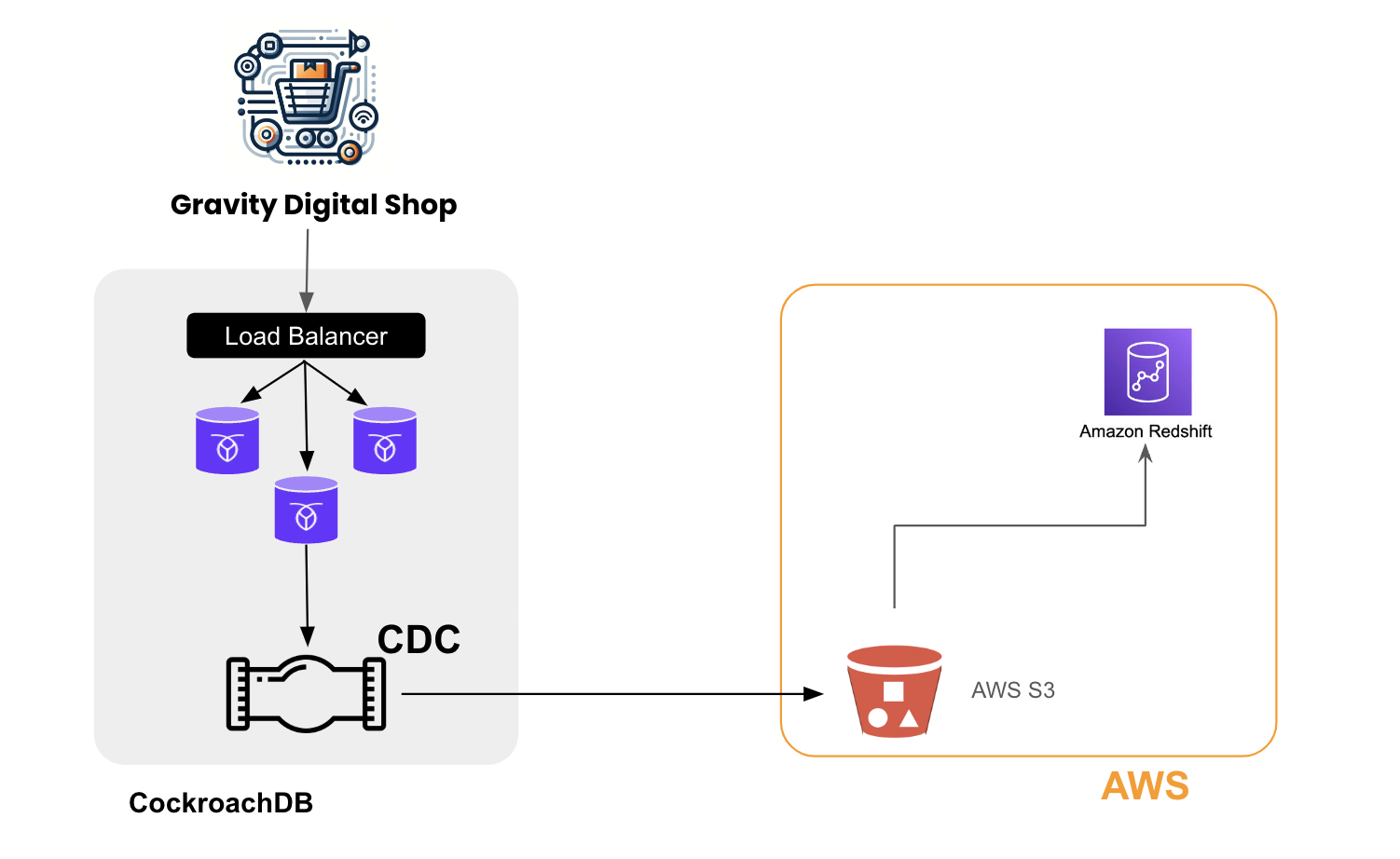
(a) High-Level Architecture
How to Integrate: A Step-by-Step Guide
1. Create a CockroachDB Cluster on AWS
In this tutorial, you’ll learn how to set up a fully managed CockroachDB cluster on AWS. You can choose between two deployment options, CockroachDB Dedicated or CockroachDB Serverless. You can follow these steps to set up either your CockroachDB Dedicated cluster or CockroachDB Serverless cluster on AWS.Once you have your database cluster configured, you can move to the next step to load data onto your CockroachDB cluster.
2. Configuring CockroachDB for Change Data Capture
First, ensure you are able to connect to your CockroachDB cluster. To connect to your specific Cockroach cloud cluster, you will use cockroach sql command with a connection string. Follow the steps in the instructions here CockroachDB Serverless or CockroachDB Dedicated.
Next, ensure your CockroachDB cluster is set up to publish changes. Enable rangefeeds. Note that rangefeeds are enabled by default on Serverless clusters.
Run the following command:
defaultdb>SET CLUSTER SETTING kv.rangefeed.enabled = true;
3. Create a Database & Table in CRDB
In the built-in SQL shell, create a database called cdc_test:
CREATE DATABASE cdc_test;
USE cdc_test; Before you can start a changefeed, you need to create at least one table for the changefeed to target. The targeted table's rows are referred to as the "watched rows".
Create a table called order_alerts to target:
CREATE TABLE order_alerts (
Id INT PRIMARY KEY,
name STRING
);
4. Setting Up AWS S3
Configure your S3 bucket to act as the intermediary storage. Set up lifecycle policies to manage data retention according to your needs. Ensure that your S3 bucket is properly secured and accessible only by authorized AWS services and users.
Every change to a watched row is emitted as a record in a configurable format (i.e., JSON for cloud storage sinks). To configure an AWS S3 bucket as the cloud storage sink:
Log in to your AWS S3 Console.
Create an S3 bucket where streaming updates from the watched tables will be collected.
You will need the name of the S3 bucket when you create your changefeed. Ensure you have a set of IAM credentials with write access on the S3 bucket that you will use during changefeed setup.
We recommend creating a separate folder for each table under each database.
e.g. our folder is s3://dj-redshift-load/cdc_test/order_alerts/
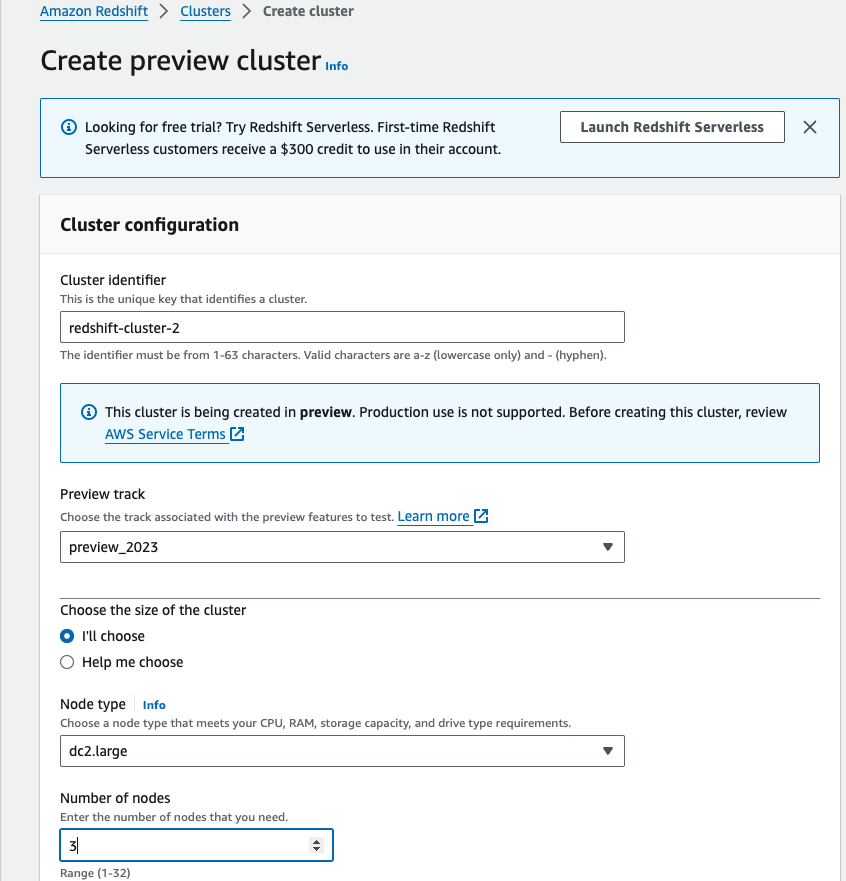
5. Setting Up AWS Redshift
AWS Redshift cluster creation steps can be found here. We will use the S3 to Redshift continuous data ingestion load feature (still in preview) to get data to flow into Redshift.
Be aware that this will only work with AWS Redshift cluster in preview. Ensure you select preview_2023 in the preview track.
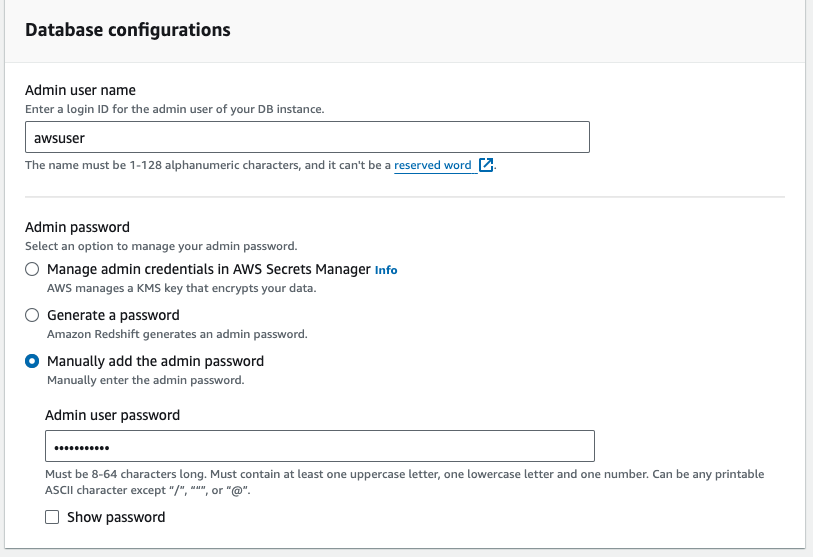
Select a manual login and create an admin and password.
First, ensure you have an AWS Redshift Cluster. Follow instructions to create a Serverless Redshift cluster or instructions here for Redshift Provisioned Cluster.
6. Create Changefeed for CockroachDB Table
Use the `CHANGEFEED` statement to stream changes into an Amazon S3 bucket. This command initiates a CDC feed for all tables, directing the output to the specified S3 bucket. For example:
CREATE CHANGEFEED INTO
's3://your-bucket-name/path?AWS_ACCESS_KEY_ID=xxx&AWS_SECRET_ACCESS_KEY=xxxx'
FOR Table;
For the order_alerts table we created earlier, run the below. Make sure you add your access key id and access key. To see other options when creating a change feed follow more information here.
CREATE CHANGEFEED INTO 's3://dj-redshift-load/cdc_test/order_alerts?AWS_ACCESS_KEY_ID= {your access key id}&AWS_SECRET_ACCESS_KEY={your secret access key}' as select * from cdc_test.order_alerts;
6. Continuous data loading between S3 and Redshift
You can use a COPY JOB to load data into AWS Redshift tables from files that are stored in AWS S3. Redshift detects when new Amazon S3 files are added to the path specified in your COPY command. This enables continuous data loading between S3 and Redshift:
copy public.order_alerts from 's3://pd-redshift-load/cdc_test/order_alerts/'
iam_role 'arn:aws:iam::196909348674:role/PD_S3_Redshift_Load_Role'
FORMAT AS JSON 'auto'
job create order_alerts_copy_job
auto on;
This will complete our setup and our continuous real time data pipeline from CockroachDB to AWS Redshift.
Note: Continuous data ingestion is currently a feature in preview and will only work with Redshift Preview cluster.
7. Insert some data into CockroachDB
Now, let’s run some basic inserts on the order_alerts table to see:
INSERT INTO order_alerts VALUES
(1, 'Order received'),
(2, 'Order processed');
8. Monitoring the Data Pipeline (Optional) - Check S3 Bucket.
A “date” folder will have been created in S3:
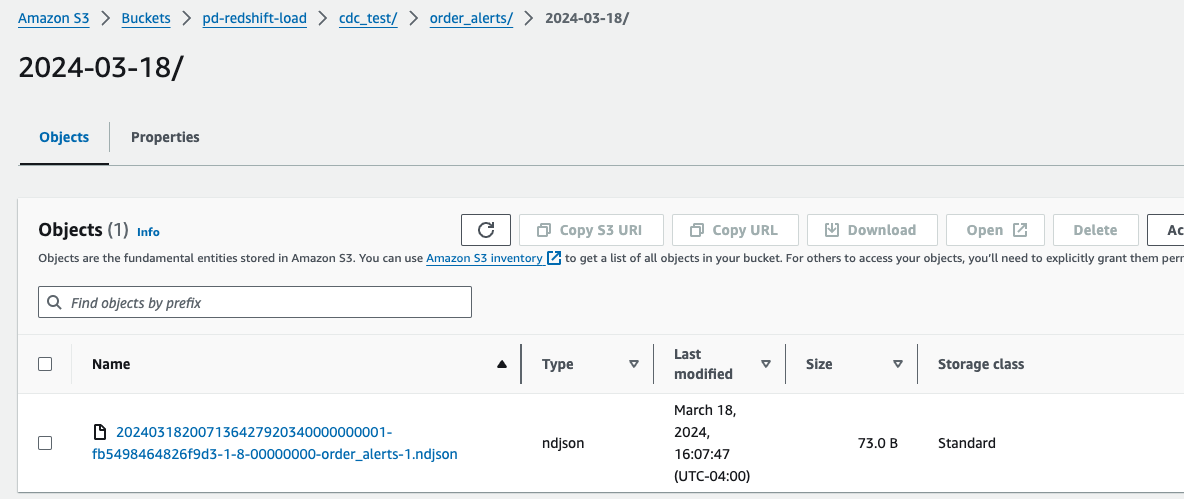
9. Monitoring the Data Pipeline - Check data in AWS Redshift
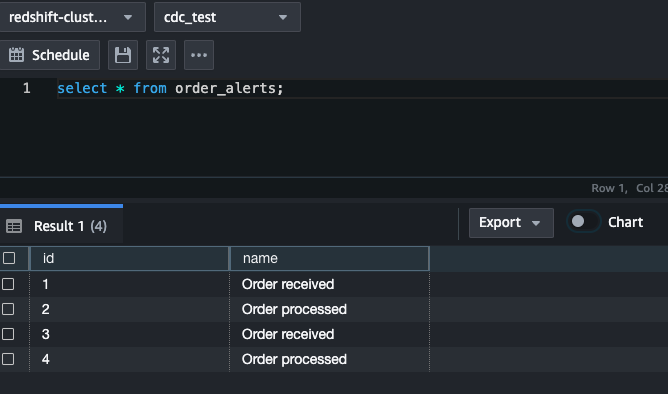
Select * from order_alerts in Redshift to confirm that the data is now showing up.
Repeat the steps a few more times. Or simulate a workload from movr.
Conclusion
In this post, you learned how to successfully automate load to Amazon Redshift with CockroachDB CDC and continuous load from S3. Remember to monitor your data pipeline regularly and adjust configurations as needed to optimize performance.
With this integration, you’ll have access to several use cases, including near real-time analytics, event-driven microservices for inventory management, and the ability to archive data for audit logging. These benefits enable businesses to deliver personalized attention and immediate service, enhancing the overall customer experience.
Disclaimer
1) This is a feature in preview and is for data loading and ingestion. This doesn’t handle updates or deletes.
2) The continuous data load from S3 feature is “in preview”. We do not know when it is going to become a permanent feature.
3) CDC Feature is only available as an enterprise feature in production in CockroachDB.


