

Recommendation engines have gained immense importance in today’s digital landscape. As global competition intensifies, businesses frequently leverage recommendation systems to enhance user experiences, drive engagement, and boost revenue.
In the e-commerce industry, recommendation engines enable key functions such as personalized product recommendations, cross-selling, and upselling. By understanding buyers’ preferences and purchase history, these systems can suggest products and services that align with their interests, leading to higher customer satisfaction and repeat purchases.
In the entertainment and content streaming industry, for example, recommendation engines play a crucial role in suggesting relevant movies, TV shows, music, or articles. By analyzing a user’s behavior and preferences, platforms like Netflix, Spotify, and YouTube provide personalized recommendations that enhance users’ satisfaction and encourage them to explore more content.
Fortunately, implementing a recommendation engine doesn’t have to be complicated. With CockroachDB’s vector capabilities, your company can implement comprehensive recommendation systems – to provide personalized recommendations among billions of possible options in no time.
This article will guide you through the process of designing and building an online recommendation engine powered by CockroachDB’s native vector capabilities:
It starts by explaining the fundamentals of recommendation systems and how different approaches – like content-based, collaborative, and hybrid filtering – can enhance user experiences in industries such as e-commerce and media streaming.
You’ll then learn how to generate and store image and text embeddings, implement real-time similarity search, and build scalable, low-latency recommendation queries using CockroachDB’s distributed SQL architecture.
Along the way, we’ll explore how CockroachDB’s support for vector indexing (C-SPANN), prefix partitioning, and strong consistency makes it an ideal choice for building high-performance, AI-driven applications.
Whether you're a developer, data engineer, or architect, you can adapt this hands-on walkthrough to your own unique use case.
Overview of Recommendation Systems
What is a recommendation engine? Recommendation engines are statistical models that analyze user data, such as browsing history, purchase behavior, preferences, and demographics, to provide personalized recommendations. These recommendations can be in the form of product suggestions, content recommendations, or relevant services.
The significance of recommendation engines lies in their ability to cater to individual user preferences and streamline decision-making processes. By offering tailored suggestions, companies can effectively engage users, keep them on their platforms longer, and ultimately increase conversion rates and sales.
Recommendation engines have evolved dramatically since their inception in the mid-1990s. Early systems were largely rule-based, relying on explicit user ratings and manually curated associations to suggest content. One of the first notable examples was Amazon’s item-to-item collaborative filtering, which revolutionized product recommendations by analyzing user behavior patterns at scale.
As web usage and data volumes grew, so did the sophistication of these systems – moving from heuristic approaches to machine learning models capable of capturing deeper patterns in user preferences. The emergence of deep learning marked a turning point, enabling the use of neural networks and embeddings to represent users and items in high-dimensional vector spaces.
More recently, transformer-based architectures and real-time vector search have further enhanced the personalization and responsiveness of online recommendations. Today, recommendation engines are a critical part of nearly every digital platform — from e-commerce to streaming services — playing a central role in user engagement, retention, and revenue generation.
There are several types of recommendation systems commonly in use:
Content-Based Filtering: This approach recommends items to users based on their preferences and characteristics. It analyzes the content and attributes of items that users have interacted with or rated positively and suggests similar items. For example, if a user enjoys action films in a movie recommendation system, the system would recommend other action movies.
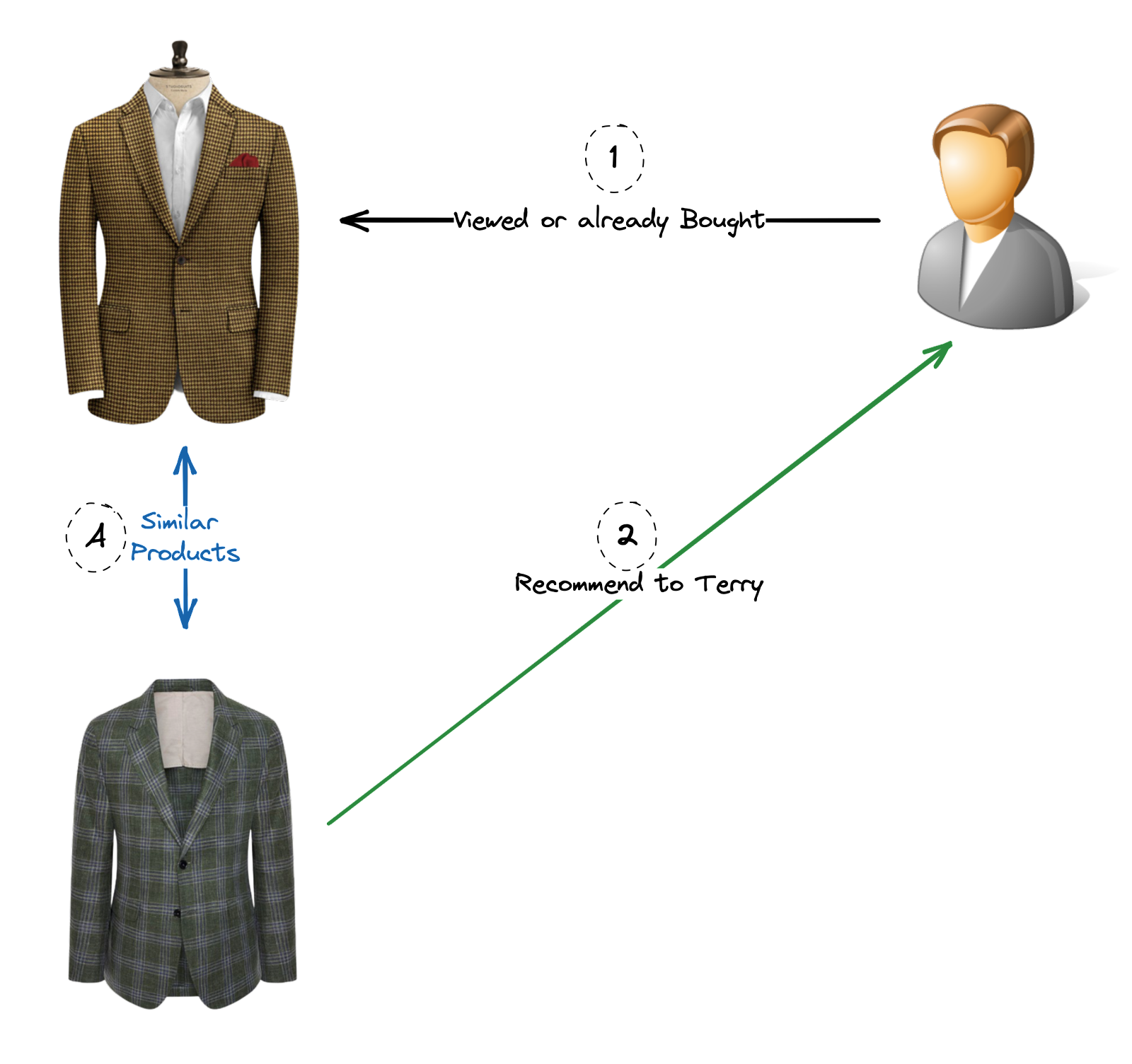
Content-Based Filtering
Collaborative Filtering: This method recommends items based on the similarities and patterns found in the behavior and preferences of multiple users. It identifies users with similar tastes and recommends items that those users have liked or rated highly. Collaborative filtering can be further divided into two subtypes:
User-Based Collaborative Filtering: It identifies users with similar preferences and recommends items that users with similar tastes have enjoyed (Scenario A & B).
Item-Based Collaborative Filtering: It identifies items that are similar based on user behavior and recommends items that are similar to those previously interacted with by the user (Scenario C).
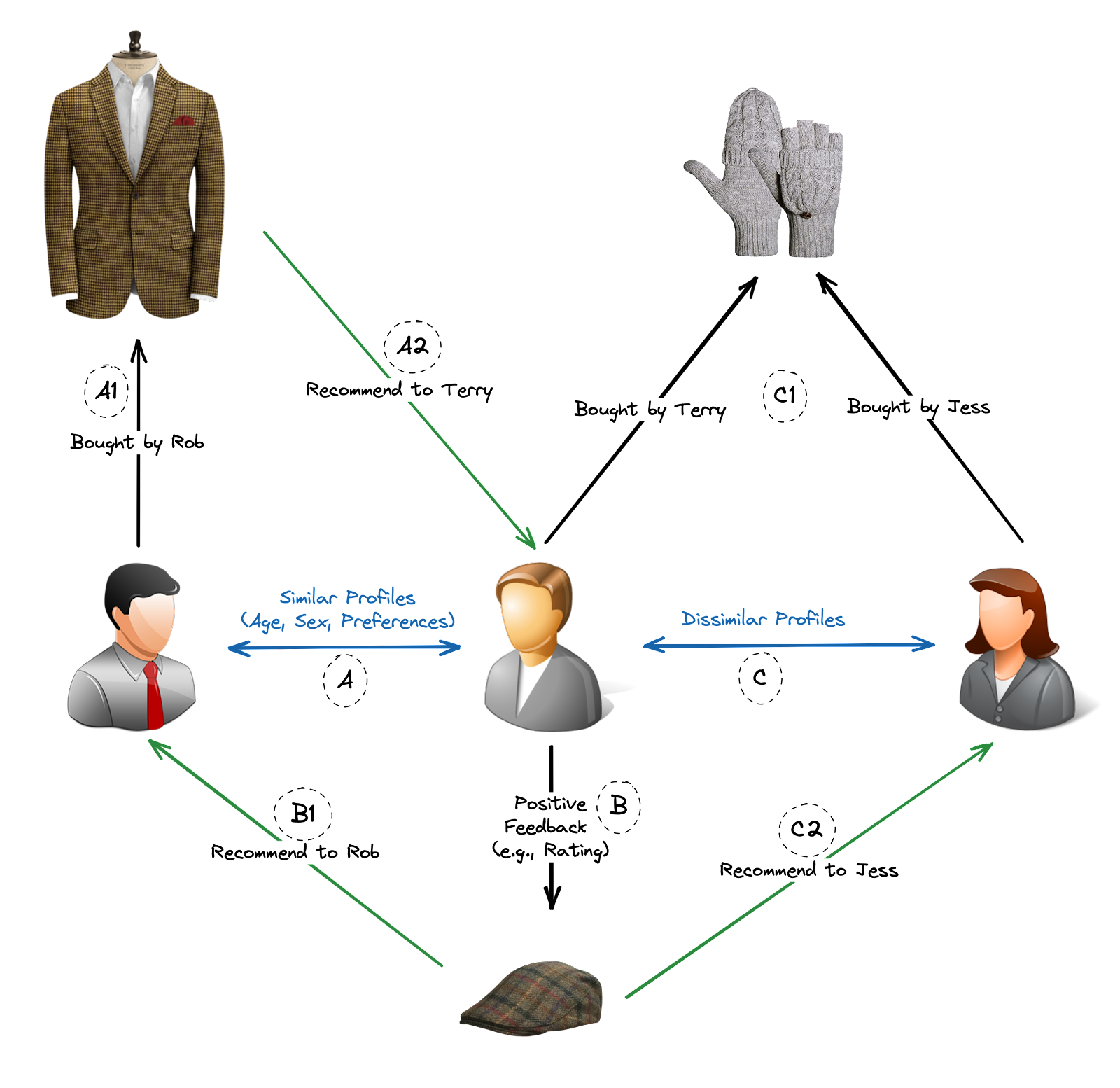
Collaborative Filtering
Context-Aware Systems: These systems consider contextual information, such as time, location, and user context, to provide more relevant recommendations. For instance, a music streaming service might recommend energetic workout playlists in the morning and relaxing music in the evening. Likewise, an e-commerce website will suggest specific items when it’s Black Friday or Christmas, different from what it could recommend in other periods of the year.
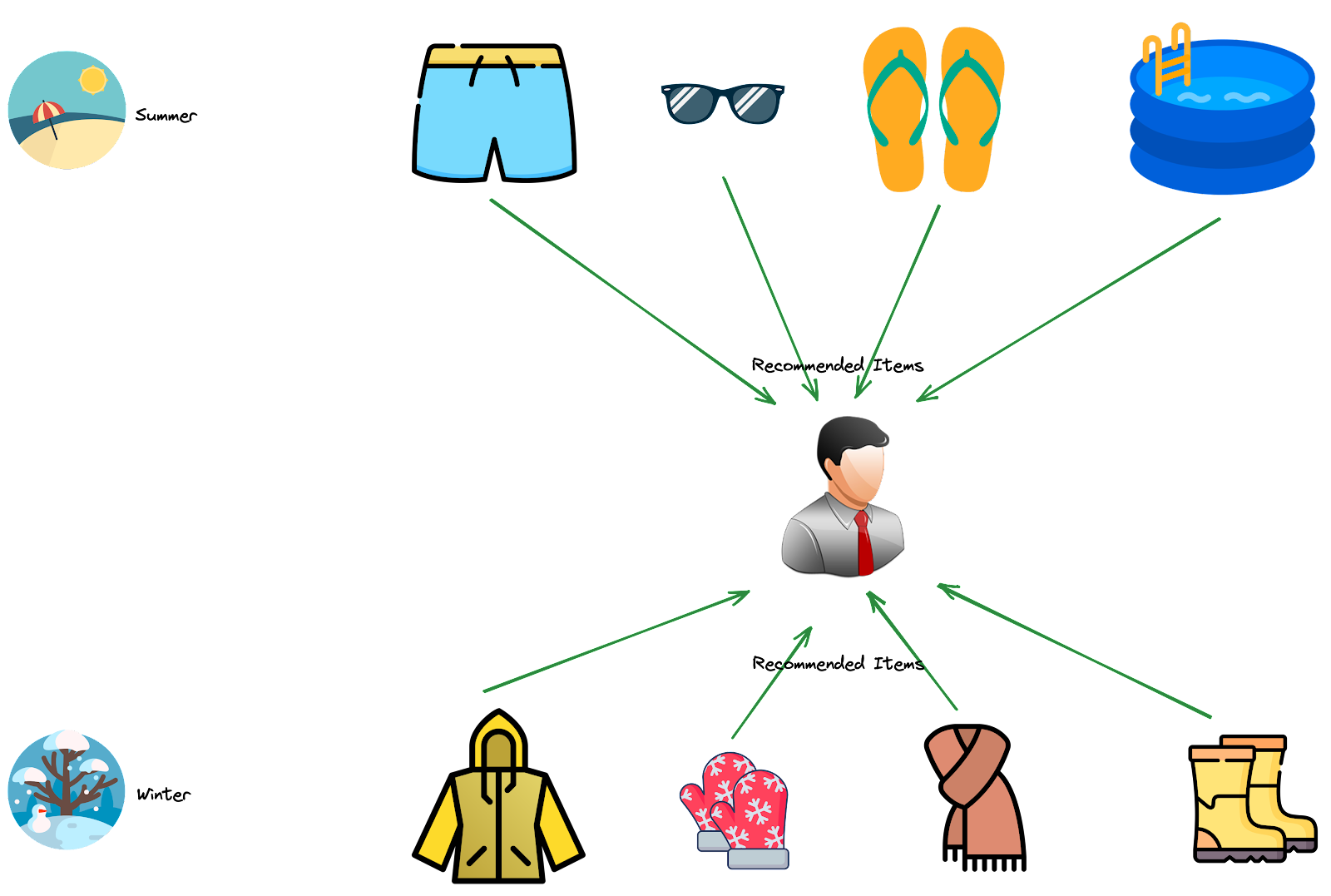
Context-Aware Filtering
Hybrid Recommendation Systems: These systems combine multiple recommendation techniques to provide more accurate and diverse recommendations. They leverage the strengths of different approaches, such as content-based filtering and collaborative filtering, to overcome their limitations and offer more effective suggestions.
Recommendation Engines with CockroachDB
Unlike offline recommendation engines that generate personalized recommendations based on historical data, an ideal recommendation engine should prioritize resource efficiency, deliver high-performance real-time updates (online), and provide accurate and relevant choices to users. For example, it can be ineffective to suggest to a customer an item they have already bought only because your recommendation system wasn’t aware of the customer’s last actions.
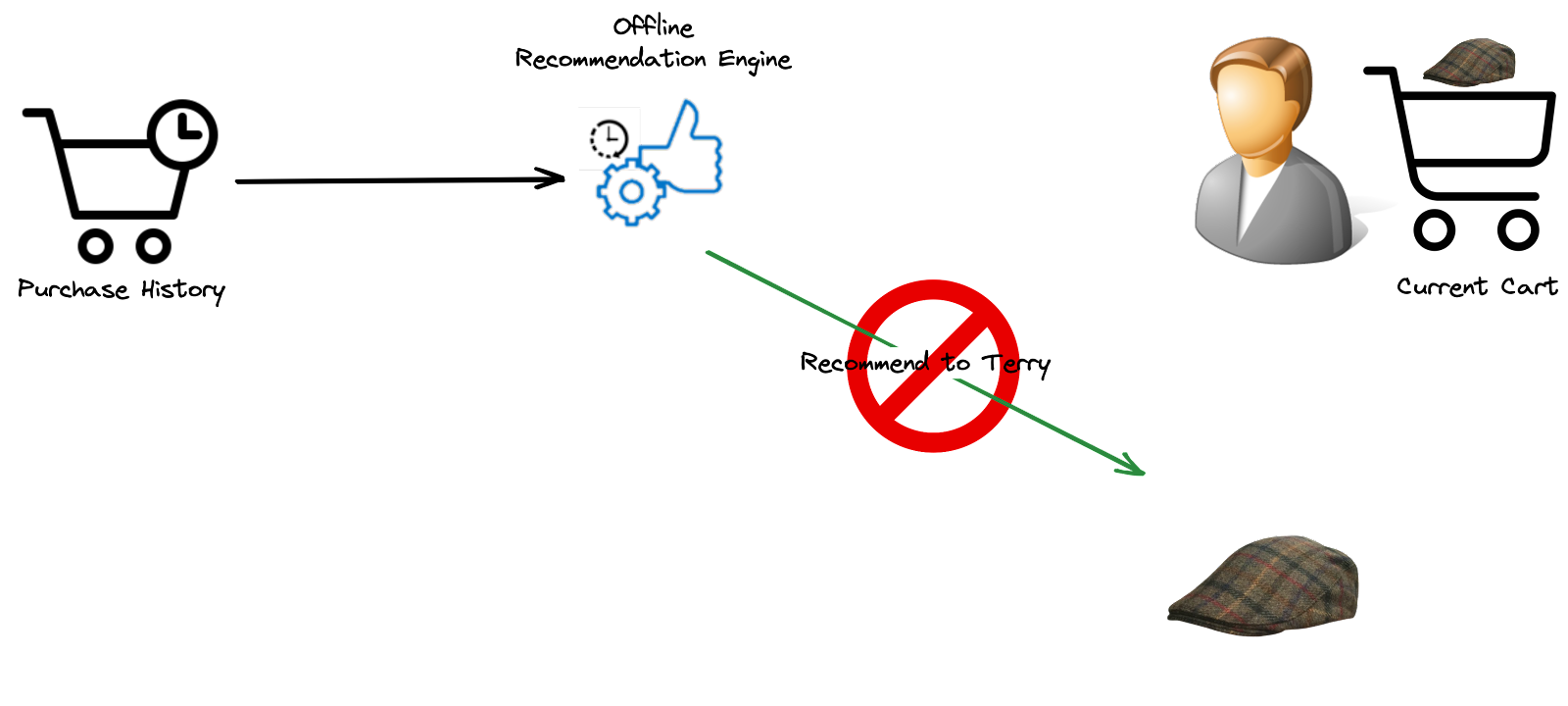
Offline Recommendation Systems
Online engines should react to customers’ actions while they are still browsing your site, and recalculate the recommendations accordingly. This would give the customers a feeling that they have a dedicated sales assistant, making their experiences more personalized.

Online Recommendation Systems
For this, you clearly need a low-latency consistent backend to implement such a system, with two important capabilities.
1. First, you need to present users’ attributes and preferences in a specific way that allows their classification into groups. Then you need a performant representation of products that provides similarity calculation and querying with very low latency.
Implementing such systems using the distributed SQL database CockroachDB is a straightforward task. Given the strong consistency and the serializable isolation level provided by default, CockroachDB always exposes the most accurate state to the recommendation engine, avoiding any stale data that can result from interactions between concurrent transactions.
2. Second, you would consider user preferences, product attributes, and any other filtering parameters as vectors. Then, thanks to the vector indexing capabilities provided by CockroachDB, your recommendation engines can make distance calculations (affinity scores) between these vectors and make recommendations based on these scores.
A vector embedding is a mathematical representation of something (like text or images) as a list of numbers, where closeness in numbers means closeness in meaning. These embeddings are mapped in multi-dimensional space to perform proximity calculations to understand the relationship between the meaning of items.
Product descriptions presented as vectors
Vector representations of data enable machine learning algorithms to process and analyze the information efficiently. These algorithms often rely on mathematical operations performed on vectors, such as dot products, vector addition, and normalization, to compute similarities, distances, and transformations.
But most importantly, Vector representations facilitate the comparison and clustering of data points in a multi-dimensional space. Similarity measures, such as cosine similarity or Euclidean distance, can be calculated between vectors to determine the similarity or dissimilarity between data points. Thus your recommendation engine can leverage vectors to:
cluster and classify customers according to their preferences and attributes (age, gender, job, location, income…) – this can help to find similarities between customers (Collaborative Filtering).
suggest similar products based on their images and textual descriptions (Content-Based Filtering).

Online Recommendation Engine using CockroachDB
In the next section, you’ll learn how to generate and store image and text embeddings, implement real-time similarity search, and build scalable, low-latency recommendation queries using CockroachDB’s distributed SQL architecture.
1 - Creating Vector Embeddings
In order to understand how vector embeddings are created, a brief introduction to modern Deep Learning models is helpful.
It is essential to convert unstructured data into numerical representations to make data understandable for Machine Learning models. In the past, this conversion was manually performed through Feature Engineering.
Deep Learning has introduced a paradigm shift in this process. Rather than relying on manual engineering, Deep Learning models – called transformers – autonomously learn intricate feature interactions in complex data. As data flows through a transformer, it generates novel representations of the input data, each with varying shapes and sizes. Each layer of the transformer focuses on different aspects of the input. This ability of Deep Learning to automatically generate feature representations from inputs forms the foundation for creating vector embeddings.
Two-tower neural network model - Source: Google Search
Vector Embeddings are created through an embedding process that maps discrete or categorical data into continuous vector representations. The process of creating embeddings depends on the specific context and data type. Here are a few common techniques:
Text Embeddings – use methods, such as Term Frequency-Inverse Document Frequency (TF-IDF), to calculate the frequency of words in a text corpus and assign weights to each word accordingly. They can use some other popular neural network-based algorithms like Word2Vec or GloVe to learn word embeddings by training neural networks on large text corpora. These algorithms capture semantic relationships between words based on their co-occurrence patterns.
Image Embeddings – use Convolutional Neural Networks (CNN) such as VGG, ResNet, or Inception, which are commonly used for image feature extraction. The activations from intermediate layers or the output of the fully connected layers can serve as image embeddings.
Sequential Data Embeddings – use Recurrent Neural Networks (RNN): RNNs, such as Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU), can learn embeddings for sequential data by capturing dependencies and temporal patterns. They can also use the Transformer model itself or its variants like BERT or GPT, which can generate contextualized embeddings for sequential data.
User Embeddings – A user’s activity on an e-commerce marketplace is not limited to only viewing items. Users may also perform actions such as making a search query, adding an item to their shopping cart, adding an item to their watch list, and so on. These actions provide valuable signals for the generation of personalized recommendations. You can use a Recurrent Neural Network (RNN) or Gated Recurrent Units (GRU) to encode the ordering information of historical events. To create User embeddings, you can leverage the Two-Tower Neural Networks approach like the one implemented by eBay: It consists of two separate neural network models, often called “towers,” that process different types of input data in parallel.
The two towers in the network typically receive different types of information related to user-item interactions. For example, one tower might process user-specific data, such as demographic information or past preferences, while the other tower processes item-specific data, such as product descriptions or attributes. Each tower independently learns representations or features from its respective input data using multiple layers of interconnected artificial neurons. The output of each tower’s final layer is then combined or fused to generate a joint representation that captures the relationship between users and items. For simplicity’s sake, I will omit this user-item relationship throughout the rest of the article and focus only on image and text embeddings.
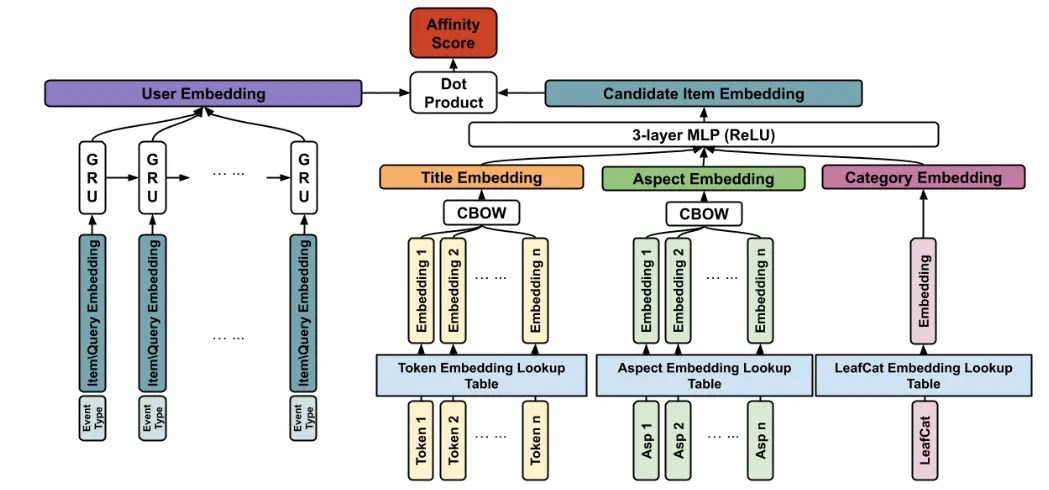
Example of the Two-tower Architecture
In our implementation, we will use a variant of BERT called all-mpnet-base-v2 to create sequential data embeddings for product descriptions. To generate product image embeddings, we use the Img2Vec model (an implementation of Resnet-18). Both models are hosted and runnable online, with no expertise or installation required. But first, we need to create the table schema before inserting data on it:
CREATE TABLE products (product_id INT PRIMARY KEY, product_description STRING, category STRING NOT NULL, description_vector VECTOR(768), image_vector VECTOR(512));Next, let’s store these products and their respective embeddings in CockroachDB. The following Python script generates and stores vector embeddings for products, using both image and text data. It uses libraries for image processing (PIL, img2vec_pytorch), text embeddings (sentence_transformers), and database connection (psycopg2).
For text embeddings, the generate_text_vectors function uses a BERT-based model (all-mpnet-base-v2) to create semantic vector embeddings from product descriptions. The generate_image_vectors function downloads product images, resizes them, and uses a ResNet-18 model to create image embeddings. The vectorize_products function calls the previous functions, and combines text and image vectors for each product into a dictionary. Then, the store_product_vectors function stores the product vectors in the products table in CockroachDB.
import os
import psycopg2
# data prep
import pandas as pd
import numpy as np
# for creating image vector embeddings
import urllib.request
from PIL import Image
from img2vec_pytorch import Img2Vec
# for creating semantic (text-based) vector embeddings
from sentence_transformers import SentenceTransformer
def generate_text_vectors(products):
text_vectors = {}
# Bert variant to create text embeddings
text_model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')
# generate text vector
for index, row in products.iterrows():
text_vector = text_model.encode(row["description"])
text_vectors[index] = text_vector.astype(np.float32)
return text_vectors
def generate_image_vectors(products):
img_vectors={}
images=[]
converted=[]
# Resnet-18 to create image embeddings
image_model = Img2Vec()
# generate image vector
for index, row in products.iterrows():
tmp_file = str(index) + ".jpg"
urllib.request.urlretrieve(row["image_url"], tmp_file)
img = Image.open(tmp_file).convert('RGB')
img = img.resize((224, 224))
images.append(img)
converted.append(index)
vec_list = image_model.get_vec(images)
img_vectors = dict(zip(converted, vec_list))
return img_vectors
def load_product_catalog():
# initialize product
dataset = {
'id': [1253, 9976, 3626, 2746, 5735, 9982, 4322, 1978, 1736],
'description': ['Herringbone Brown Classic', 'Herringbone Wool Suit Navy Blue', 'Peaky Blinders Tweed Outfit', 'Cable Knitted Scarf and Bobble Hat', 'ADIDAS Men White Pluto Sports Shoes', 'ADIDAS Unisex White Shoes', 'Nike STAR RUNNER 4', 'Adidas SL 72 Unisex Shoes', 'Adidas Adizero F50 2 M Mens Running Jogging Shoes'],
'category': ['Suits', 'Suits', 'Suits', 'Hats', 'Shoes', 'Shoes', 'Shoes', 'Shoes', 'Shoes'],
'image_url': [
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/donegal-herringbone-tweed-men_s-jacket.jpeg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/Mens-Herringbone-Tweed-Check-3-Piece-Wool-Suit-Navy-Blue.webp',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/Marc-Darcy-Enzo-Mens-Herringbone-Tweed-Check-3-Piece-Suit.jpeg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/img/Mocara_MaxwellFlat_900x.jpg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/products/men/393e9315126350d97000721f330aa964.jpg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/products/men/6d62ba4de5c73b36d44f6bff05d2457e.jpg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/products/men/7185ef5d96833937481c19a47edac96a.jpg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/products/men/8cf52572340c3592e5f0ede116a0206f.jpg',
'https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/products/men/b3d19377041615d8a7cf46b96ef67c4c.jpg'
]
}
# Create DataFrame
products = pd.DataFrame(dataset).set_index('id')
return products
def vectorize_products(catalog):
products = []
img_vectors = generate_image_vectors(catalog)
text_vectors = generate_text_vectors(catalog)
for index, row in catalog.iterrows():
_id = index
text_vector = text_vectors[_id].tolist()
img_vector = img_vectors[_id].tolist()
vector_dict = {
"description_vector": text_vector,
"image_vector": img_vector,
"product_id": _id,
"category": row.category,
"product_description": row.description
}
products.append(vector_dict)
return products
def store_product_vectors(crdb_url, products):
with psycopg2.connect(crdb_url) as conn:
# Open a cursor to perform database operations
with conn.cursor() as cursor:
for product in products:
query = f'''INSERT INTO products (product_id, product_description, category, description_vector, image_vector) VALUES ({product["product_id"]}, '{product["product_description"]}', '{product["category"]}','{product["description_vector"]}', '{product["image_vector"]}')'''
cursor.execute(query)
print(f'''Inserted product: {product["product_id"]}, {product["product_description"]}''')
def create_crdb_url():
host = os.environ.get("CRDB_HOST", "localhost")
port = os.environ.get("CRDB_PORT", 26257)
db = os.environ.get("CRDB_DATABASE", "defaultdb")
username = os.environ.get("CRDB_USERNAME", "root")
url = f'''postgresql://{username}@{host}:{port}/{db}'''
return url
# Create a CockroachDB connection string
crdb_url = create_crdb_url()
# Load a few products
catalog = load_product_catalog()
# Create vector embeddings for products
products = vectorize_products(catalog)
# Store vectors in CockroachDB
store_product_vectors(crdb_url, products)
The choice of embedding technique depends on the specific data type, task, and available resources. The Huggingface Model Hub contains many models that can create embeddings for different kinds of data.
2 - Vector Indexing
Once you have created vector embeddings for your products, you may choose to store and query them in a vector database like Pinecone, Milvus, Weaviate, or, Qdrant — each optimized for fast similarity search. While these systems often prioritize performance over strong consistency, CockroachDB offers strong consistency, high isolation, horizontal scalability, and now supports vector data types and approximate similarity queries. This makes it a good option when transactional semantics are needed alongside vector operations.
Additionally, CockroachDB’s new vector indexing system C-SPANN, incorporates ideas from Microsoft’s SPANN and SPFresh papers, as well as Google’s ScaNN project. It was designed to support fast, real-time semantic search across billions of data items — such as photos, or documents — in a highly distributed and transactional environment.
Unlike traditional solutions that rely on in-memory datasets or batched writes, C-SPANN is built to function across regions with strong consistency, low latency, and linear scalability. It supports immediate searchability of new data, avoids central coordination, and fits naturally into CockroachDB’s distributed key-value storage model.
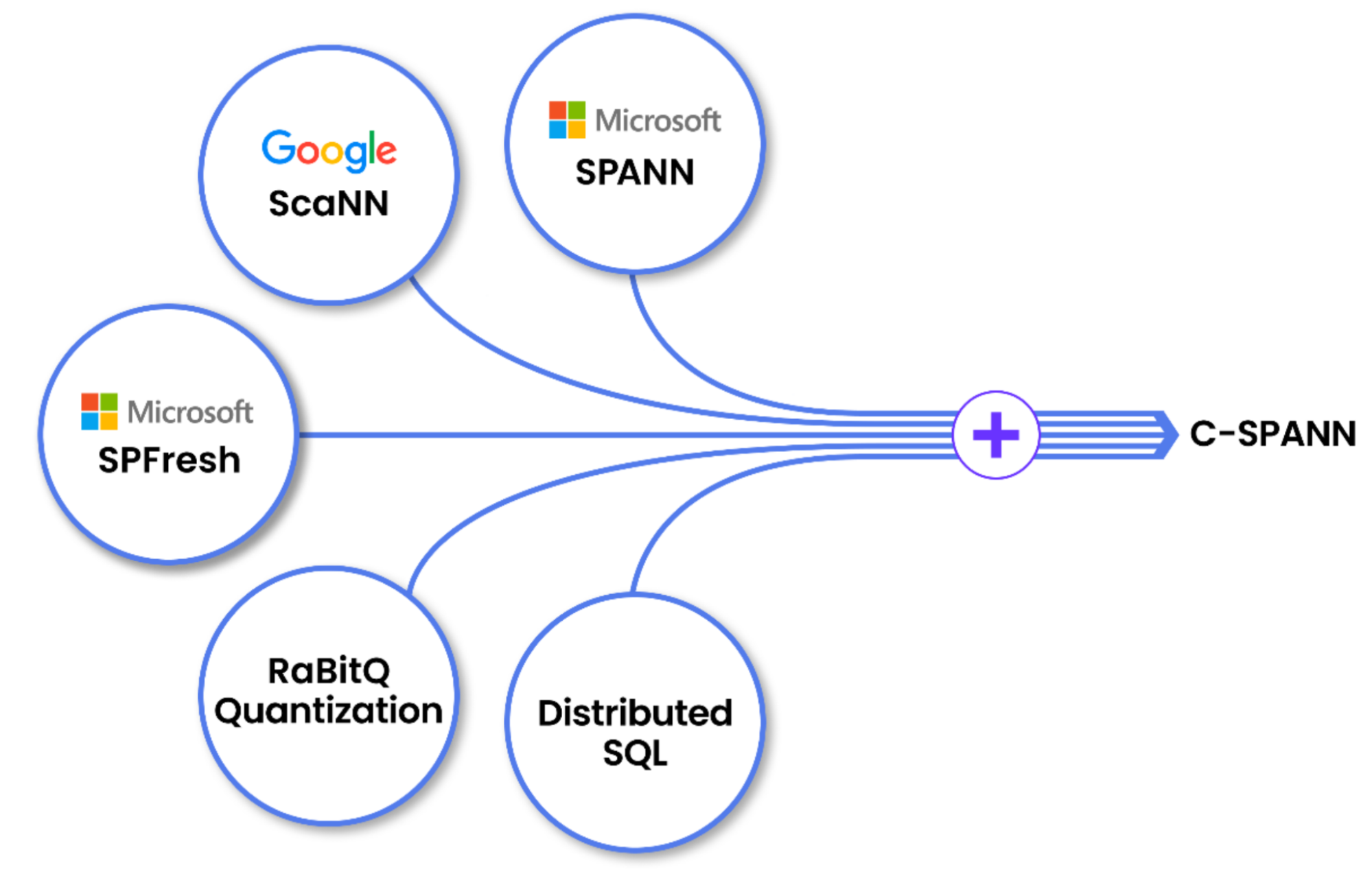
To keep storage and compute costs low, C-SPANN integrates RaBitQ, a quantization technique that reduces vector size by approximately 94%. Quantized vectors are scanned rapidly using SIMD-optimized instructions, and a reranking step ensures high accuracy by rechecking the top candidates against the original full-precision vectors. The system also supports per-user and multi-region indexing via prefix columns, enabling fine-grained isolation and data locality. This ensures scalable, secure, and low-latency search experiences regardless of the number of users or regions involved.
CockroachDB uses a distance metric to measure the similarity between two vectors (a.k.a, how “close” or “far apart” two vectors are). Currently, only the operators <-> Euclidean Distance (L2), <#> Inner Product (IP), and <=> Cosine Similarity are available in CockroachDB.
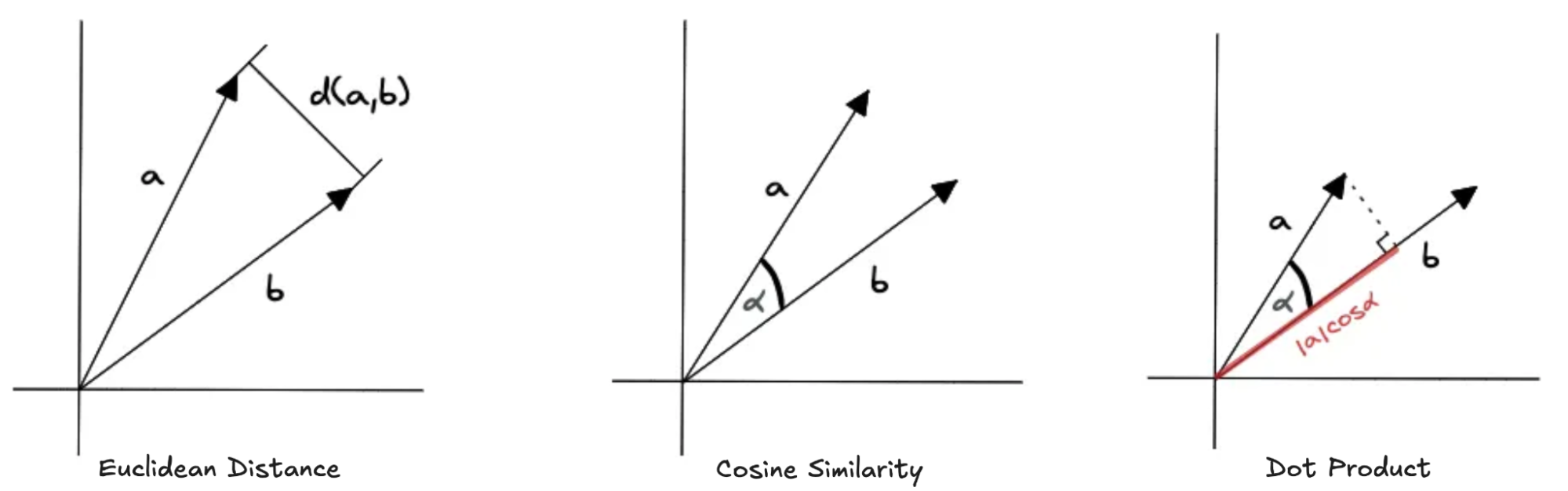
Distance Metrics
We have described how C-SPANN can efficiently cluster large volumes of vectors while keeping the index up to date through real-time, incremental updates. However, there’s an important nuance in practical applications: Vectors typically belong to distinct entities — such as users, customers, or product category — and most queries are intended to operate within the scope of a single entity. Including vectors from unrelated owners will dilute relevance in vector search.
CockroachDB addresses this elegantly by supporting prefix columns in vector indexes. This feature enables the index to be logically partitioned by ownership — or any other criteria — ensuring both isolation and query efficiency. Here's an example of creating the image vector index in CockroachDB based on the products table created previously.
CREATE VECTOR INDEX ON products (category, image_vector);If you create vector indexes for the first time in your cluster, you will need to set the feature.vector_index.enabled setting:
SET CLUSTER SETTING feature.vector_index.enabled = true;After loading product vectors into CockroachDB and creating the vector indexes, the recommendation engine can execute all kinds of similarity search queries.
3 - Vector Similarity Search
At the heart of CockroachDB vector indexing is a hierarchical K-means tree that organizes vectors into partitions based on similarity. These partitions are stored in CockroachDB’s range-based architecture, enabling automatic splitting, merging, and load balancing. To maintain index accuracy over time, C-SPANN supports background partition splits, merges, and vector reassignments, ensuring that vectors are always located in their most relevant cluster. This design eliminates the need for expensive full index rebuilds, even after millions of incremental updates.
This indexing system unlocks advanced search capabilities like finding the “top K” most similar vectors, performing low-latency searches in large vector spaces by ranging from tens of thousands to hundreds of millions of vectors distributed across several machines.
Consequently, CockroachDB exposes the usual search functionality, combining full text, numerical, and geographical pre-filters with K-Nearest Neighbors (KNN) vector search: With CockroachDB, you can query products stored as vectors while pre-filtering by location, price and description, and choose the relevant vector distance metrics to calculate how “similar” or “dissimilar” two products are.
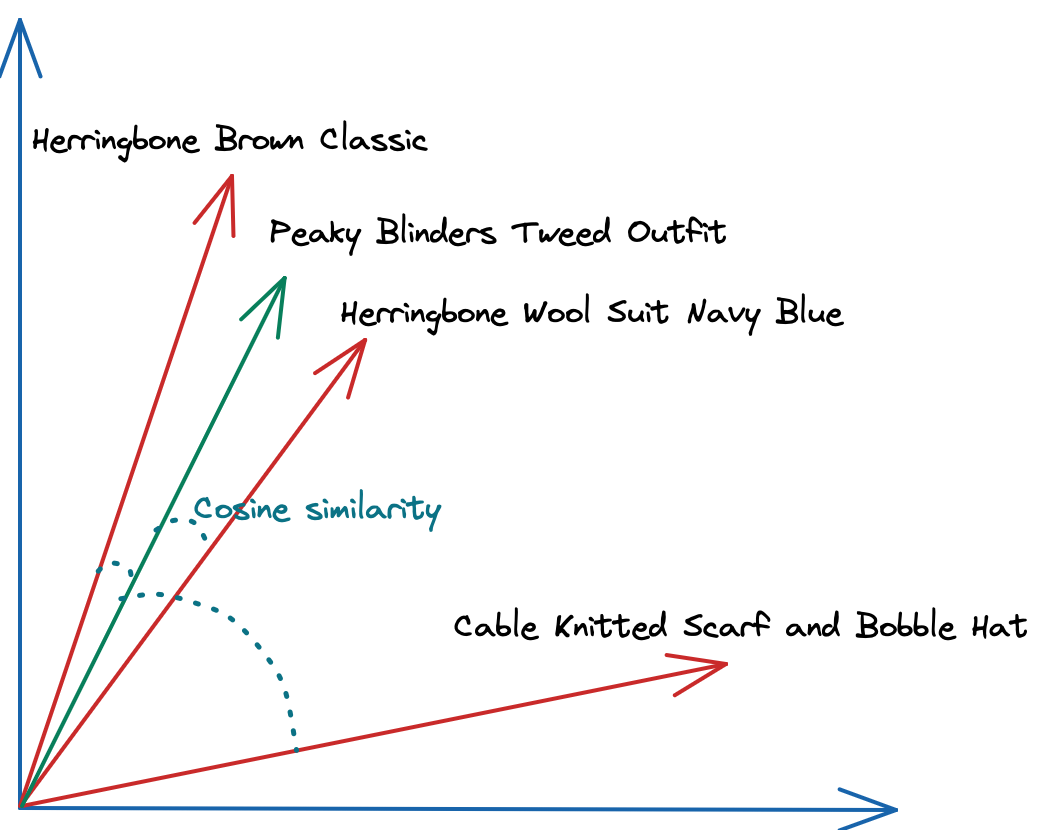
Calculating Cosine Similarity between Product Descriptions
The query below returns the 10 similar products – for which the vectors are stored in the image_vector field – to a query image vector. You can also set a pre-filter regarding its category, price range or sales location.
SELECT product_id, product_description FROM products WHERE category = $1 ORDER BY (image_vector <-> $2) LIMIT 10;For example, if you search a product with associated store locations and product images (encoded as vectors) in a single table, you can create a secondary index on the store location column to pre-filter data before performing a Vector Search.
This means that instead of scanning the entire dataset, the system first narrows down the search to relevant locations — such as “Casablanca” — and then applies vector similarity search only within that subset. Such a hybrid search approach significantly improves query performance and resource efficiency, making it easier to build intelligent, high-performance AI applications at scale using familiar SQL syntax.
Below is an example of creating a query that returns the three most similar products (by image) to this one, sorted by relevance score (Euclidean Distance set in the indexes created earlier).
def create_query_vector():
query_image_url = "https://raw.githubusercontent.com/aelkouhen/aelkouhen.github.io/main/assets/data/products/2eca615a43d0098f4bb5fc90004c3678.jpg"
# Resnet-18 to create image embeddings
image_model = Img2Vec()
# generate image vector
tmp_file = "query_image.jpg"
urllib.request.urlretrieve(query_image_url, tmp_file)
img = Image.open(tmp_file).convert('RGB')
img = img.resize((224, 224))
vector = image_model.get_vec(img)
query_vector = np.array(vector, dtype=np.float32).tolist()
return query_vector
def fetch_similar_products(crdb_url, category, query_vector, limit=5):
with psycopg2.connect(crdb_url) as conn:
# Open a cursor to perform database operations
with conn.cursor() as cursor:
query = f'''SELECT product_id, product_description
FROM products
WHERE category = '{category}'
ORDER BY image_vector <-> '{query_vector}'
LIMIT {limit}'''
cursor.execute(query)
results = cursor.fetchall()
print("The most similar product are: \n")
for row in results:
print(f"The Product ID: {row[0]}, Description: {row[1]}")
query_vector = create_query_vector()
fetch_similar_products(crdb_url, "Shoes", query_vector, limit=3)
Even if the index contains billions of products, this query will search only the subset associated with a specific product category. Insert and search performance scales with the number of vectors tagged in that category — not the total volume of vectors in the system. This isolation reduces contention across products, as queries operate on separate index partitions and rows.
Under the hood, the index maintains an independent K-means tree for each category. From the system’s standpoint, there’s little difference between managing one billion vectors in a single tree or distributing them across a million smaller trees. In both cases, vectors are assigned to partitions and stored within ranges in CockroachDB’s key-value layer. These ranges are automatically split, merged, and distributed across nodes, enabling near-linear scalability as usage grows.
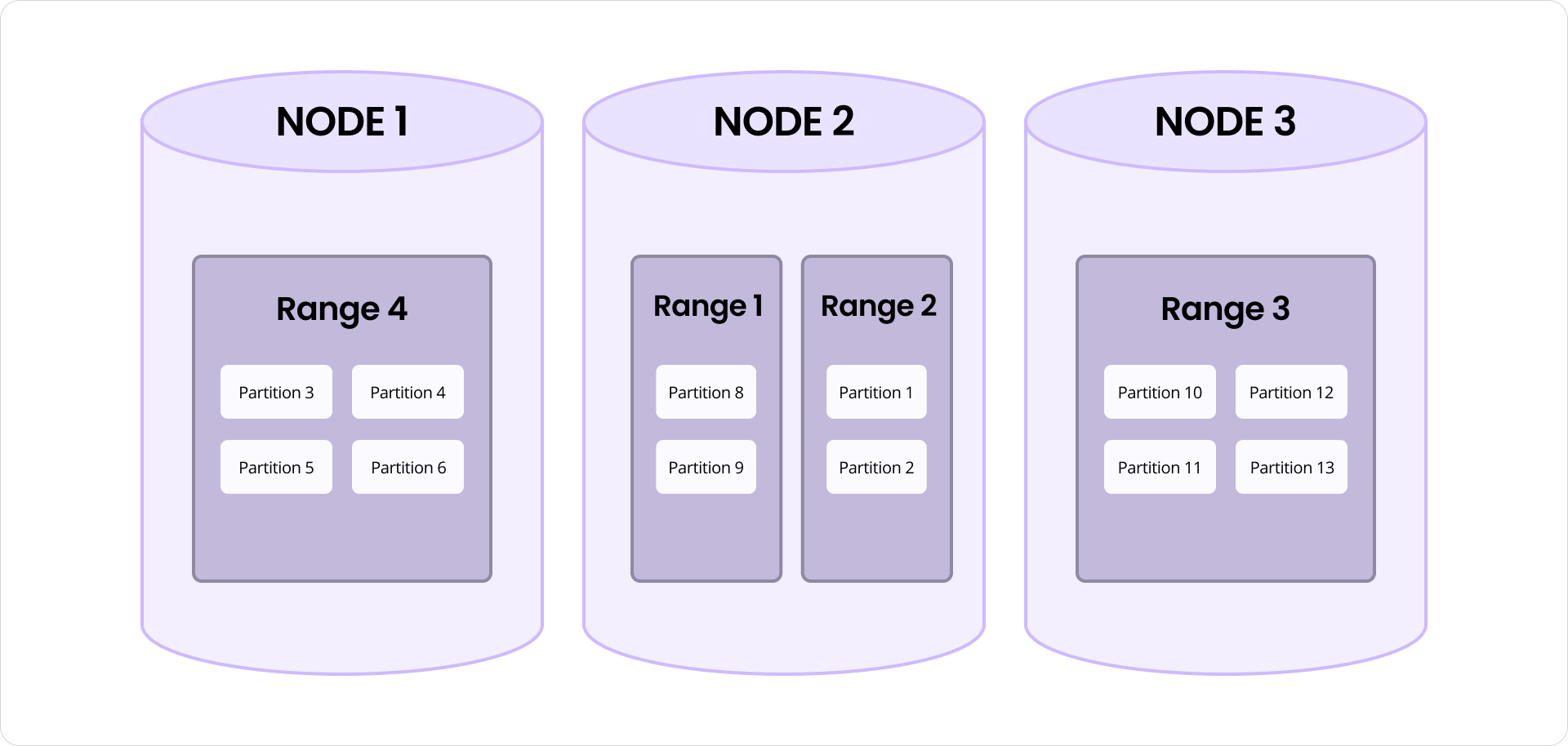
The instructions above are a brief overview to demonstrate the building blocks for an online recommendation engine using CockroachDB. You can try this out with the notebook referenced here (install Google Colab to open).
A high performance AI recommendation engine
CockroachDB supports diverse capabilities that can significantly reduce application complexity while delivering consistently high performance, even on a large scale.
With the vector capabilities, CockroachDB unlocked several impactful AI applications based on similarity and distance calculation in near real-time with high accuracy. Recommendation engines are an example of such applications.
If you want to provide interactive, content-based recommendations, you might want to take advantage of CockroachDB as a vector database and a similarity search engine. Regardless of how complex you want your recommendation engine to be: collaborative, content-based, contextual, or even hybrid, CockroachDB helps you deliver the best recommendations for a successful user experience.
Learn more about how distributed SQL is evolving to power the next generation of AI applications: Get your guide.
Amine El Kouhen, Ph.D., is Sr. Partner Solutions Architect at Cockroach Labs.




{kind=link}