



In today’s always-on, global applications, raw speed is no longer enough. Modern enterprises demand not only blistering transaction rates but also unwavering stability when the unexpected strikes; whether that’s a network hiccup, a failing disk, or an entire data center going dark. With organizations averaging 86 outages a year, failures are the norm today. But traditional benchmarks like TPC-C only tell you how fast a database runs in perfect conditions, or sunny days. They leave out the more important story of what happens when things go wrong.
As announced by Cockroach Labs, our new database benchmarking methodology, “Performance under Adversity” captures these complex, operational realities of modern enterprise systems: where everything fails all the time. The benchmark is a single, continuous test that weaves seven increasingly severe failure scenarios into a standard OLTP workload. By measuring throughput, latency, and failure rates through rolling upgrades, disk stalls, network partitions, node restarts, and even full zone or regional outages, our benchmark reveals how well CockroachDB, a distributed SQL database, maintains service continuity when it matters most.
In this blog post, we’ll dive into what makes CockroachDB uniquely resilient under pressure. We will examine its baseline performance, its behavior under internal operational stress, and its ability to self-heal through grey failures and large-scale outages. We explain exactly how CockroachDB stays online and keeps data safe even beyond perfect, sunny days and clear operational skies.
Measure what matters
Traditional benchmarks only test when everything’s perfect. But you need to know what happens when everything fails. CockroachDB's new benchmark, "Performance under Adversity," tests real-world scenarios: network partitions, regional outages, disk stalls, and so much more.
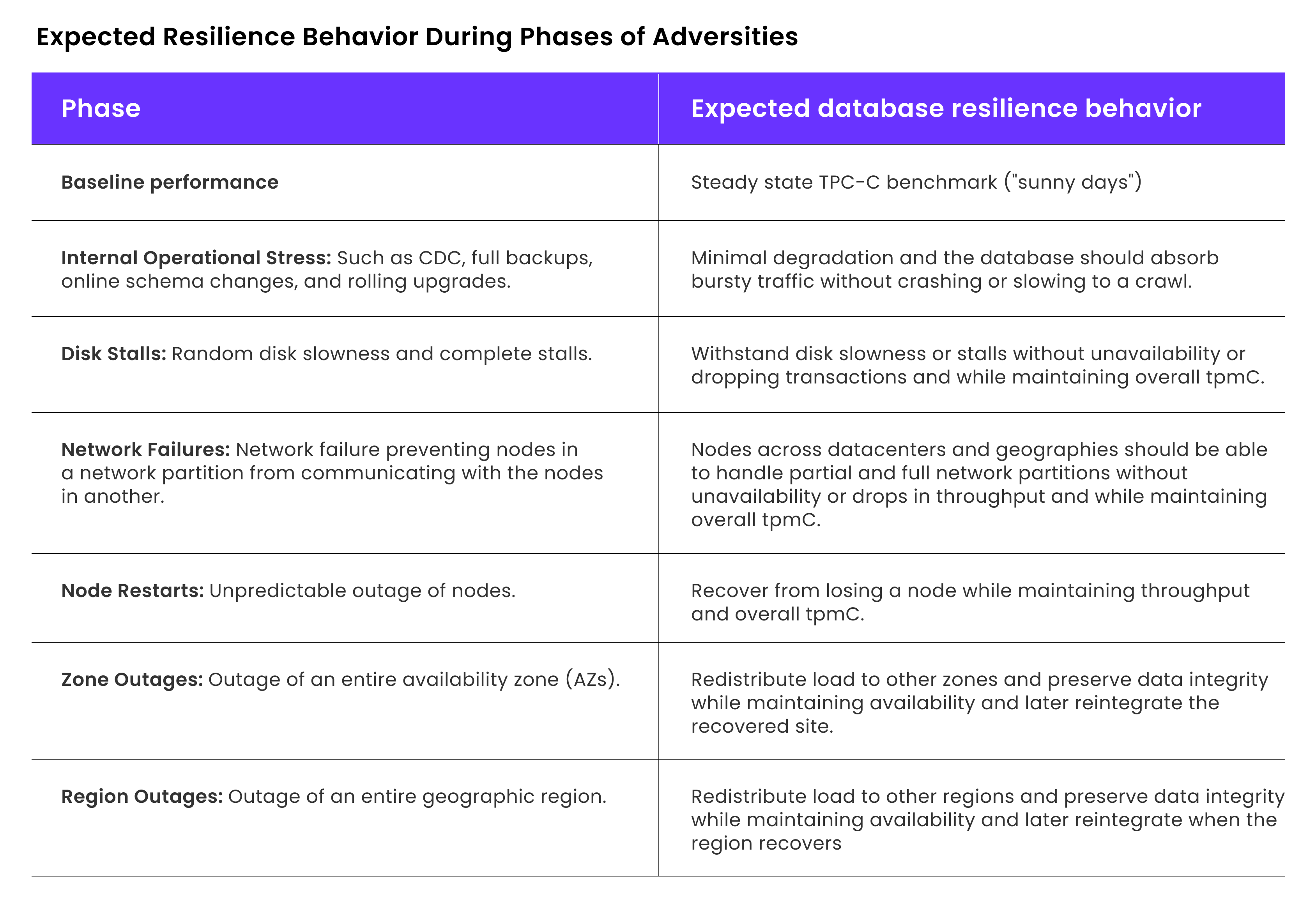
The Seven Phases of Adversity
Before exploring how CockroachDB tackles the operational realities of modern enterprise systems, let’s first outline the behaviors you should expect from a resilient database as it endures each phase of real-world adversity.
What Keeps CockroachDB Resilient and Stable Under Pressure?
To understand how CockroachDB handles the pressure, let us look at the results of the benchmark in the interactive dashboard and then analyze the result of each phase.
Baseline Performance: Normal conditions only running TPC-C workload with no internal or external stressors (a perfect, “sunny day”)
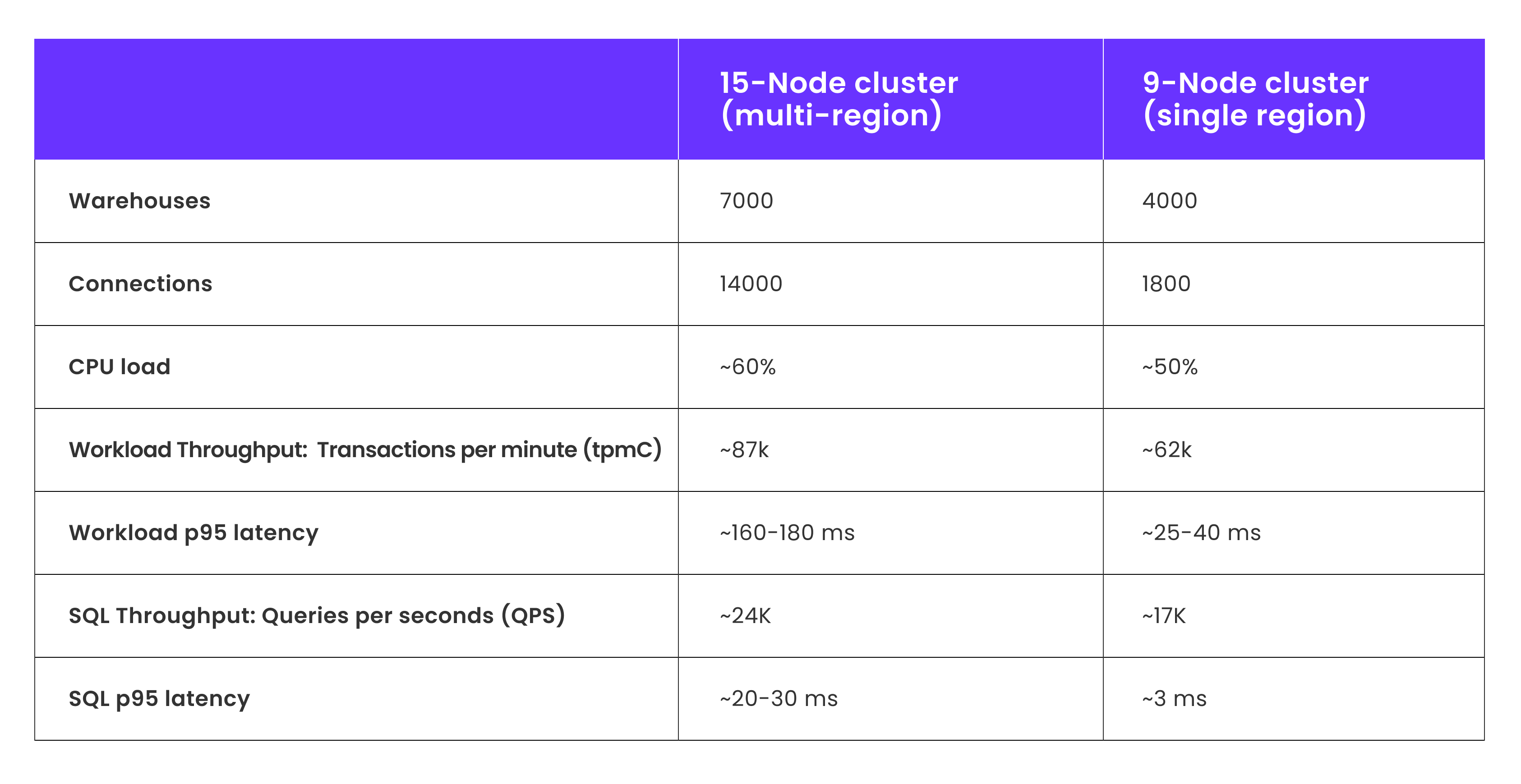
It is important to note that tpmC measures transactions per minute for TPC-C and each transaction is ~14 queries. So the corresponding SQL queries per seconds (QPS) is tpmC multiplied by a factor of 14/60. The largest transaction tested is the "New Order" transaction, which consists of up to 14 SQL statements involving 8 database tables to complete an order within a transaction. This workload is both read- and write-intensive, designed with high execution frequency and strict response-time requirements to simulate real-world online database activity.
Internal Operational Stress: In this phase, routine maintenance tasks are executed, including backups, change feeds, online schema changes, and rolling upgrades.
During backups, change-data capture (CDC), and index builds (online schema change), the database must scan or rewrite tables. These operations consume significant CPU and I/O bandwidth.
Likewise, during rolling upgrades, for each node being upgraded, CockroachDB drains SQL connections on the node, transfers data leases from the node to the other nodes and then restarts the node with the upgraded binary. Any application connected to the node will experience a SQL connection drop when the node restarts; and the application may try to reconnect, generating a burst of new connections. Upon rejoining, the restarted node receives snapshots of data that changed while it was down from other nodes. The lease transfers, connection burst, and snapshot streaming to restarted nodes generates heavy CPU and IOPS load.
Without careful throttling and scheduling, large background scans, large connection bursts, and snapshot streaming will inevitably siphon CPU, I/O, and network capacity from your primary workload. In turn driving up latency, eroding throughput, and risking overall cluster health.
As can be seen on the dashboard during this phase on CockroachDB, tpmC remained unaffected during internal operational stress with minimal latency impact, and CockroachDB maintained stability.
CockroachDB avoids the aforementioned pitfalls with its built-in admission control layer, which dynamically prioritizes client-facing traffic over background operations. Not only that, admission control throttles access to a resource (CPU or IO) before the resource becomes overloaded, rather than after. The result is rock-solid stability, consistently low latencies, and minimal throughput impact even when backups, CDC streams, index builds, and rolling upgrades run concurrently.
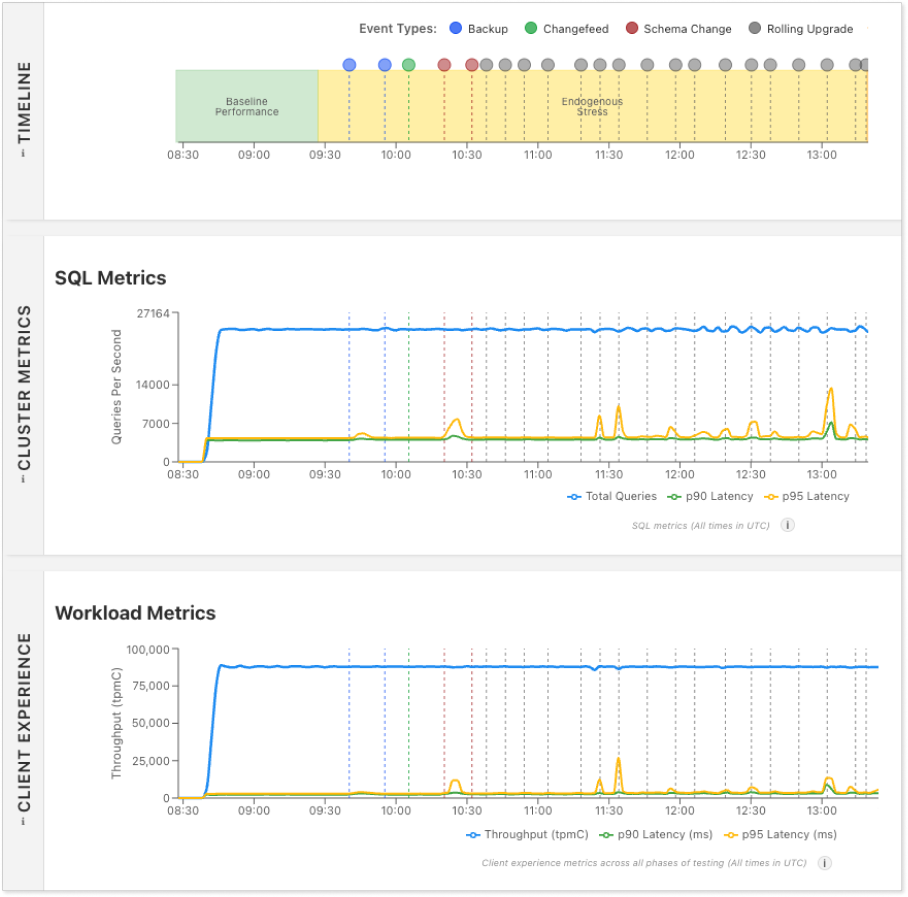
Image: 15-node CockroachDB cluster under internal operational stress
Next, let us understand how CockroachDB handles external stressors that are not controlled by the database administrator.
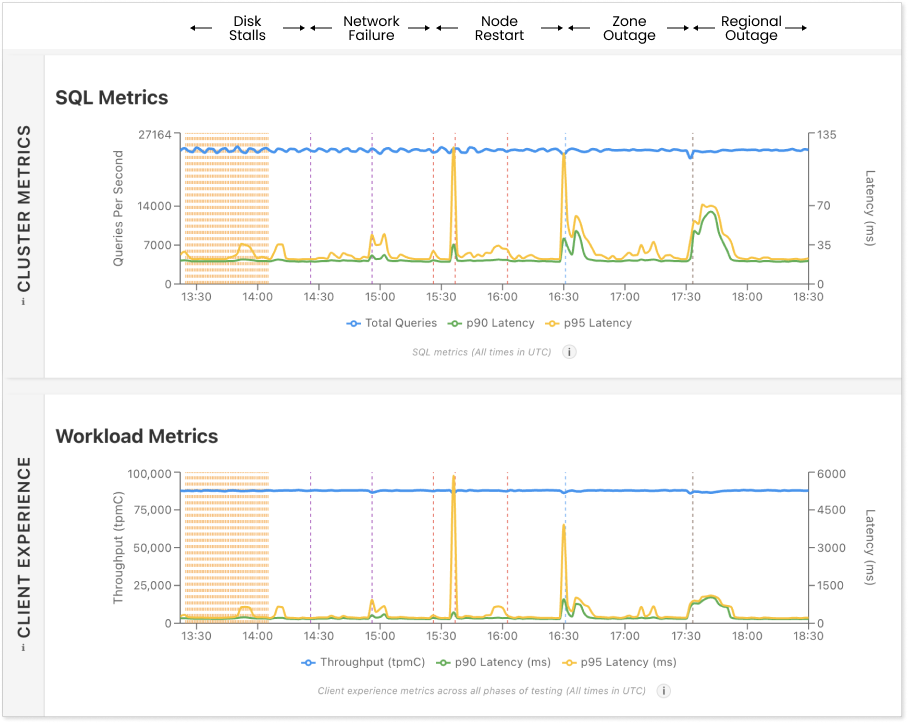
Image: 15-node CockroachDB cluster withstanding external stressors (disk stalls, network partitions, node restarts, and facility and region outage)
Disk Stalls: Transient disk stalls are a frequent reality in cloud environments whether on AWS EBS, Azure SSD, or GCP PD occurring as often as 20–30 times per hour in a single cluster. During a stall, write-ahead log (WAL) writes block until the disk recovers, often leading to transaction timeouts, latency spikes, and elusive “grey” failures.
As can be seen on the dashboard, CockroachDB handles disk stalls with minimal latency impact and stable throughput.
CockroachDB turns disk stalls into a non-event by leveraging multiple disks per node: if one disk stalls, WAL writes automatically fail over to an alternate disk within 100ms. The result is seamless resilience, with steady latency without blips and no noticeable drop in performance or throughput.
Network Failures: Network failures can result in network partitions, which isolate one or more nodes from the rest of the cluster. These issues can arise from hardware or software failures, traffic congestion, or misconfiguration and can last anywhere from seconds to minutes (or, in rare cases, even longer). When partitions occur, they can result in read-errors, write-errors, latency spikes, and potentially stale or inconsistent data. Such gray failures are notoriously hard to diagnose because they’re often transient and shifting.
As evident on the dashboard, which shows a minor latency spike for a brief duration and minimal impact on throughput, CockroachDB is partition-tolerant.
We ran these tests using CockroachDB v25.1. It survives network partitions with epoch leases, which fence out stale masters and prevent a split‐brain scenario. During a partition, only the majority side (with more than half of ranges) can renew or re‐elect leases and the minority side leases stales out. Any future operations by stale leaseholders are rejected and the surviving leader continues serving traffic seamlessly, preserving consistency and availability, and minimizing impact on throughput. Once the network recovers from partition, all the nodes start participating in quorum.
Starting with v25.2, CockroachDB survives network partitions thanks to its leader-leases architecture: every Raft leader also holds the range’s lease, ensuring a single, unequivocal authority for both reads and writes. By unifying leadership and leaseholding in a single role, it eliminates single points of failure and split-brain risks. So even when node communication is severed, the surviving leader continues serving traffic seamlessly, preserving consistency and availability; and minimizing impact on throughput.
Node Restarts: Similar to rolling upgrades, a node restart also triggers lease transfer from the restarted node to other nodes across the clusters. If the node takes longer than 5 minutes to restart, it also triggers range rebalancing. Additionally any applications connected to the node will experience SQL connection drops, and will try to reconnect generating a burst of new connections. These are random and ungraceful reboots, and the resulting lease transfers, connection burst, and snapshot streaming generate heavy storage engine CPU load, IOPS and network traffic. In turn impacting latency and throughput by taking away resources from foreground traffic. However CockrochDB’s Admission Control handles this by prioritizing foreground traffic over rebalancing activities while maintaining stability, and resulting in only minor latency increases and negligible throughput impacts.
In the benchmarking run where three nodes were restarted randomly, the dashboard shows a brief, minor latency spike and negligible impact on throughput of the CockroachDB cluster.
Zone Outages: Zone outages can occur when the data center hosting the zone experiences power or network outage. When this occurs, data replicas in the impacted zone need to move over to the remaining zones to ensure full cluster availability. This data movement is done by streaming range data among the nodes in the remaining zones, thus balancing the range distribution in the cluster.
Range rebalancing across multiple nodes generates heavy storage engine CPU load, IOPS and network traffic. Unchecked, the range rebalancing can overload these resources and starve foreground queries of resources resulting in negative impact on latency and throughput and in extreme cases destabilizing the cluster altogether. However, CockroachDB, as shown on the dashboard, only experienced a very brief, minor latency spike and virtually no change in throughput during the zone outage.
Overall availability and stability of the CockroachDB cluster throughout the zone outage is thanks to the automatic redirection of traffic from failed zones to available zones and especially how CockroachDB’s Admission Control handles foreground traffic and background range rebalancing traffic.
Regional Outages: Enterprises with presence in multiple geographies require that users in all locations have consistent experiences with latency and throughput. In addition, these enterprises must comply with data domiciling regulations. For such organizations, CockroachDB can operate in multiple regions by placing data closer to users in different geographic locations.
Similar to zone outages, regional outages trigger range rebalancing across the nodes of the remaining regions to maintain full cluster availability. As explained earlier, range rebalancing across multiple nodes can negatively impact foreground latency and throughput, and cluster stability. However this is not an issue in CockroachDB, as shown in the dashboard.
Again, similar to zone outage, CockroachDB’s admission control automatically redirects traffic to available regions and dynamically prioritizes client-facing traffic over background operations. Along with properly throttling access to resources before they become overloaded, results in stability with minimal latency and throughput impact.
One final observation to make is the consistency in CPU and disk usage throughout the entire benchmarking run.
You can check out a full demo of the interactive dashboard on our YouTube channel:
Resilience Is Essential, Not Optional
As you’ve seen, the new database benchmarking methodology, “Performance under Adversity,” pushes CockroachDB through seven increasingly severe failure scenarios and in every case CockroachDB delivers steady throughput, low latency, and zero downtime. That resilience comes from engineered features like back-pressured range rebalancing, admission control that favors client traffic, co-located leaseholders, and multi-disk WAL failover.
After all, it’s not enough to know how fast your database can go when the sun is shining and conditions are perfect. You need to know that your database will keep churning at scale, under load, and in the face of every curveball the real world can throw. With CockroachDB and our new benchmark, you get both performance and peace of mind even beyond the sunny days.
Explore the interactive dashboard to review phase-by-phase metrics, run your own tests, or spin up a free CockroachDB cluster today.
Try CockroachDB Today
Spin up your first CockroachDB Cloud cluster in minutes. Start with $400 in free credits. Or get a free 30-day trial of CockroachDB Enterprise on self-hosted environments.
Disclaimer: Results are from specific test setups. Try CockroachDB yourself to see how it fits your needs.





