

At this point, we’ve all heard of major outages, and many of us have even missed flights or missed out on a concert because the intensity of customer demand has outpaced the capacity of critical data infrastructure.
It’s me. Hi. I’m the problem, it’s me. At peak times, I might lose power.
– Mainframes covering “Anti-Hero” by Taylor Swift.
In today's interconnected and data-driven world, the resilience of IT systems is paramount, but it’s challenging to navigate migrations, ever-evolving technology, and increasingly stringent regulations.

In our recent webinar, "The Always-On Dilemma: Disaster Recovery vs. Inherent Resilience," Peter Mattis, CTO, and CPO at Cockroach Labs, and Rob Reid, Technical Evangelist at Cockroach Labs, shared expertise on the critical aspects of building resilient systems and the profound impact of downtime on modern businesses. Throughout the conversation, they shared lessons from their careers, insights from working with customers, and fielded questions from the audience.
In today’s article, we’re highlighting some key takeaways. Listen to the full conversation: “The Always-On Dilemma: Disaster Recovery vs. Inherent Resilience”
Career lessons from Google’s startup days
Rob kicked off the conversation with a round of quick introductions. As a technical evangelist at Cockroach Labs, you may have seen Rob featured in our many YouTube videos highlighting new features, sharing quick demos, and chaos testing our distributed SQL database, CockroachDB. Peter, also one of our fearless co-founders, fondly recalled the beginning of his career, when he joined a pre-IPO Google two decades ago. Even then, Peter noted how common failure was. After all, success can often tax data infrastructure and lead to outages.
Operational Resilience: Key stats and what all those 9s really mean
Downtime can have severe consequences for businesses, both financially and reputationally. The webinar highlighted that 9 out of 10 businesses experience one or more outages per quarter. For small businesses, the impact can be devastating, with 43% closing within a year of a severe outage. The costs associated with downtime are significant, with small businesses potentially losing $25,000 per hour and large businesses losing millions of dollars per hour during an outage. These figures underscore the importance of having resilient systems, but don’t fully capture the impact that an outage can have on your reputation.
This was a lesson that I actually had taught to me in my time at Google. Failures will be the norm, not the exception. You know, if you're running a data center that has 10,000 hard drives or 10,000 machines, you can presume that you'll have hard drives failing all the time.
– Peter Mattis, Co-founder, CTO & CPO, Cockroach Labs
Just to cover some of the basics, Rob ran us through a few key definitions around resilience, operational resilience, RTO and RPO during the call. An interesting callout to day-to-day business operations was when Rob and Peter translated 3 9s, 4 9s, and 5 9s, to actual downtime per year. Resilience, after all, is the ability of IT systems and infrastructure to withstand, adapt to, and recover from adverse conditions, disruptions, and failures.
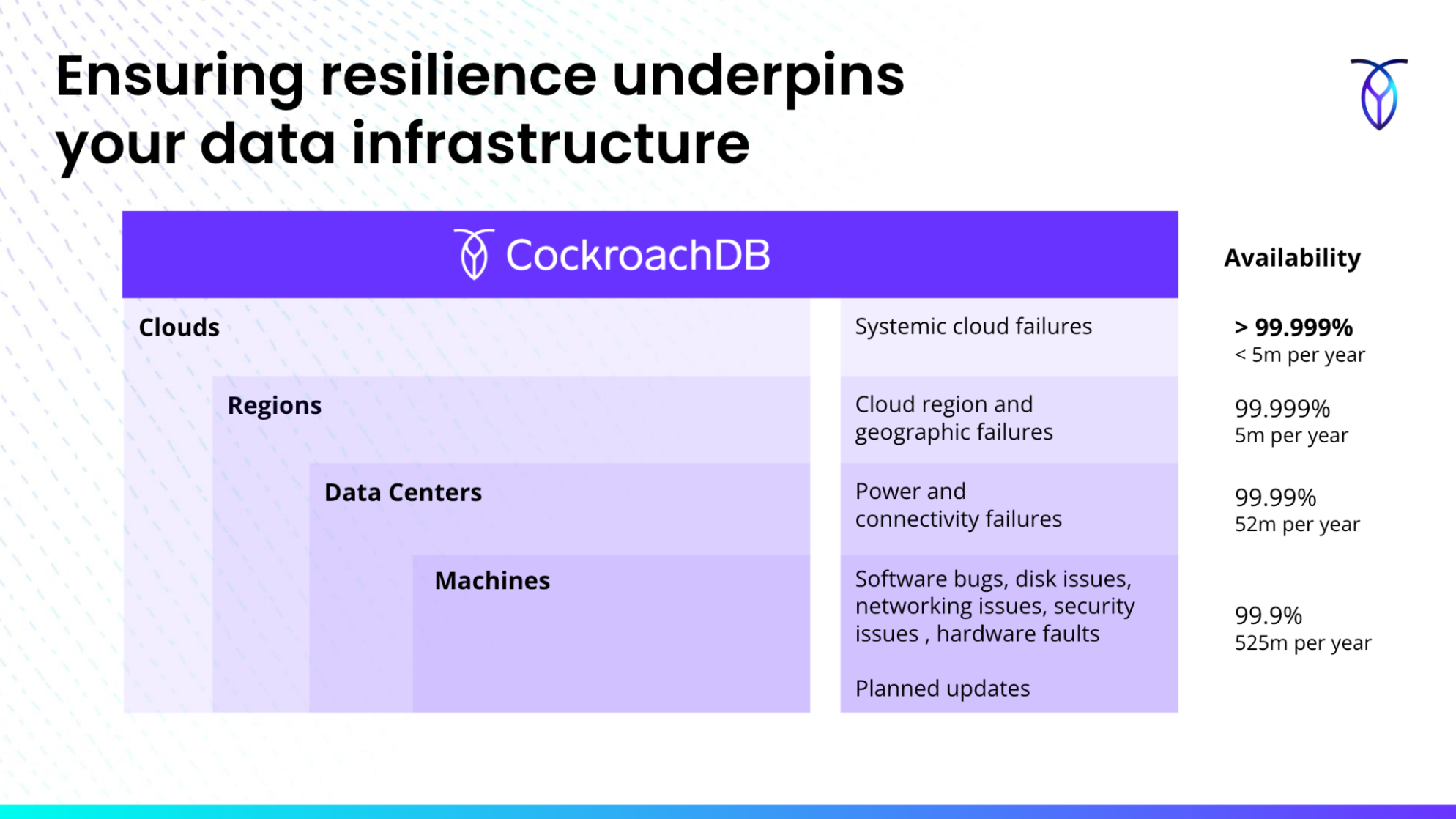
The above is a slide from the webinar showcasing the kinds of failures that each layer of resilience is susceptible to, as well as the percent of availability expected, and minutes of downtime to expect per year.
But in the context of modern business, resilience is not just a technical requirement, it is a strategic imperative. Peter and Rob shared that if a business is relying on machine-level resilience – 3 9s of downtime or 99.9% availability – they are vulnerable to human error, hardware failures, and even planned updates. On average, this equates to 525 minutes or several hours of downtime per year. This figure can drop to below 5 minutes after we add those layers of resilience with multiple regions or multi-cloud deployments. This can be particularly critical given that outages can happen to anyone, even successful businesses.
Disaster Recovery vs. Inherent Resilience
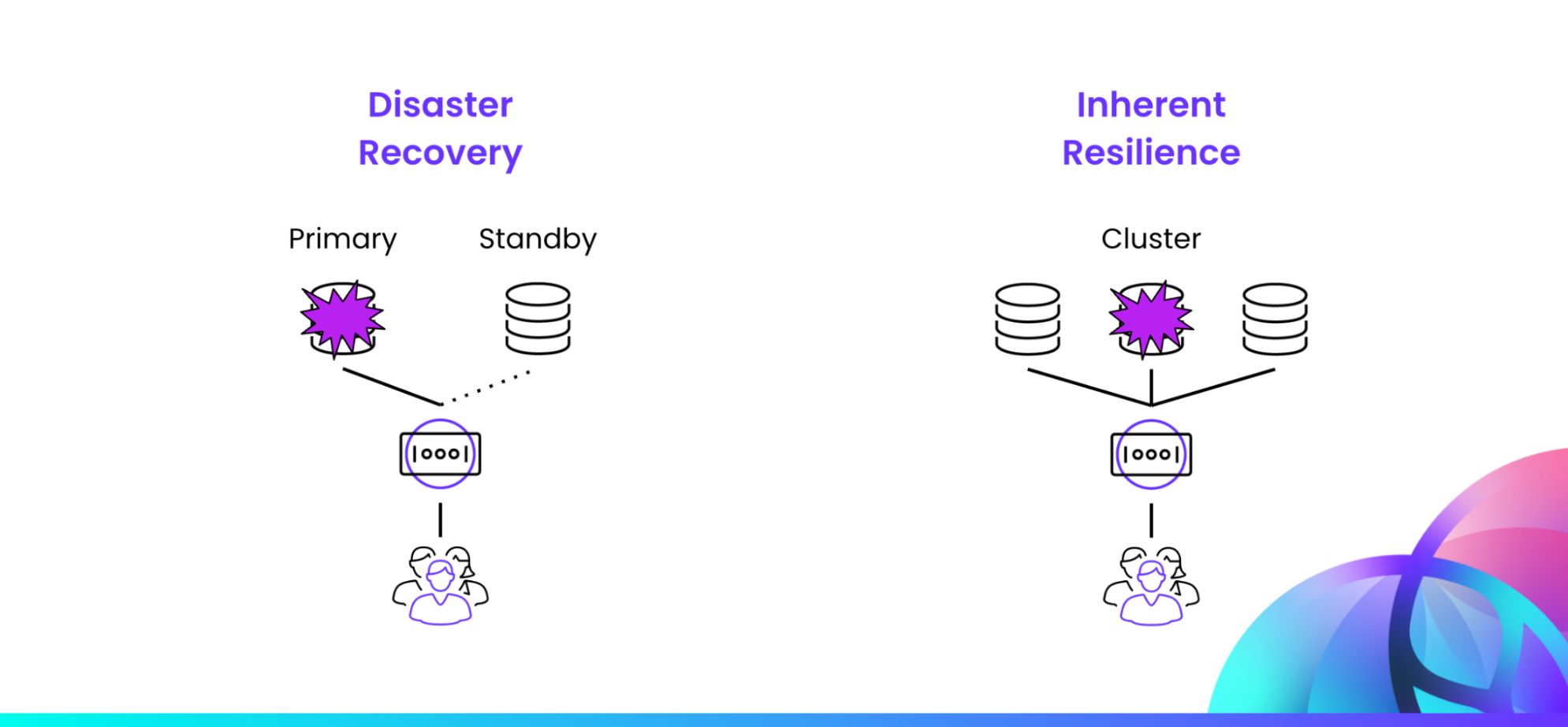
The traditional approach to handling outages has been disaster recovery, which focuses on restoring systems after a failure. However, this approach is increasingly seen as insufficient in the face of modern challenges. Peter and Rob introduced the concept of inherent resilience as the next step, beyond disaster recovery. Inherent resilience involves building systems that are designed to survive the failure of any component without human intervention. Recovery time when humans are in the loop can take minutes or hours, but inherent resilience allows recovery to happen at machine speeds – on the magnitude of seconds or milliseconds. This approach ensures zero recovery point objective (RPO) and minimal recovery time objective (RTO), providing continuous availability and operational continuity.
CockroachDB, for example, is a modern distributed SQL database that combines the reliability and consistency of traditional relational databases with the scale and flexibility of NoSQL databases. This architecture allows for automatic failover mechanisms and real-time operational continuity, ensuring that businesses can maintain critical operations even in the face of disruptions.
Success can trigger systemic failure
I've been in businesses that failed because of success. You think about Black Friday or the holiday season. That's a yearly workout for your architecture and those events are guaranteed ebbs and flows of business. It's just a case of whether your organization’s architecture can keep up with them.
– Rob Reid, Technical Evangelist, Cockroach Labs
The webinar concluded with a call to action for businesses to adopt resilient architectures. The key takeaway is that resilience is not just about surviving outages but thriving in an always-on business environment. By building inherently resilient systems, you can ensure continuity, mitigate risks, and maintain a competitive edge in the market.
Asynchronous Q & A
If you joined us live, or if you’ve watched the recording, you can see that Peter and Rob received a number of interesting questions from our live audience which you can watch in the recorded session. We did not have time to go over all of them, so Peter and Rob wanted to share their answers to some lingering questions below:
When we mention self healing, can you mention some cases that self healing might not be possible? And how do we normally test these scenarios?
An errant application deployment could delete or corrupt table data. A single region cluster can experience failure of that region (recovering only once that region is available again). A cybersecurity attack could take a cluster offline. These are all examples of where disaster recovery tooling would be brought in to address the problem. Many of the scenarios can be tested by verifying that a cluster can be restored from a backup. The cybersecurity attack scenario should also be verified that backups cannot be (easily) deleted or corrupted by an attacker.
How significant is the impact on egress costs when replicating across cloud providers?
This will depend on the cloud provider but essentially they charge more for internet-bound egress than they do for inter-region (without their cloud) egress. I wouldn’t be surprised if intercloud costs were to lower in the future, as the industry increasingly realizes the importance of multi-cloud (and the clouds adapt to that need).
The cost of running an application across multiple clouds is going to be more expensive than running an application that remains within a single cloud, so it’s not for everyone. If - to you - the risk of a cloud outage (and its resulting cost) outweighs the cost of running across clouds, then it might be a good idea for your workload; otherwise, perhaps multi AZ or multi-region will be sufficient.
In a cloud managed offering of CockroachDB, is it advisable to keep the backups onsite or is it best to keep it with the CockroachDB cloud?
We take automatic backups of your clusters at regular intervals (and our Standard and Advanced tiers allow you to configure the backup cadence and retention duration) but you may additionally like to keep your own backups that reside within your own infrastructure. We have customers who rely on our managed backups and customers who prefer to additionally keep their own.
To catch all of the other audience questions, check out the full conversation on our website.





