


With the rise of AI across industries, it’s becoming more important to address the limitations of LLMs. One increasingly popular method is Retrieval Augmented Generation (RAG), which allows you to provide external knowledge sources as context to Large Language Models (LLMs).
In this blog post, we dive into the significance and benefits of RAG applications first. Then we explore the advantages of leveraging CockroachDB, a highly scalable and resilient distributed SQL database, as the foundation for building efficient and robust RAG applications. To illustrate the practical implementation, I’ve created a knowledge base chatbot. Readers will experience a clear walkthrough of the application's operation via an interactive demo, gaining insights into how CockroachDB vector search seamlessly integrates with LLM APIs to ensure real-time, contextualized responses. Finally, we'll summarize key takeaways and highlight why CockroachDB provides an ideal backend for modern RAG-powered applications.
What is Retrieval Augmented Generation (RAG)? How does RAG improve LLMs? 
Large Language Models (LLMs) bring tremendous knowledge and creativity, enabling groundbreaking capabilities in generating human-like text and automating numerous tasks. However, despite being trained on massive datasets, these models often exhibit limitations when dealing with specific domain knowledge or real-time personalized transactional information. As seen online, LLMs can generate inaccuracies or completely fabricated information—a phenomenon known as “hallucinations.” Hallucinations occur when an LLM generates plausible-sounding but factually incorrect or entirely fabricated statements.
Retrieval Augmented Generation (RAG) addresses this critical challenge by introducing grounded data, meaning responses are directly supported by accurate and relevant information. Instead of solely relying on the model’s pre-trained knowledge, RAG first queries a specialized database containing domain-specific knowledge to identify the most relevant and update-to-date information. This retrieved context is then fed back into the LLM, enabling the generation of precise, trustworthy answers based on verified data rather than ungrounded predictions.
Retrieval Augmented Generation (RAG) Use Cases
There is a lot of potential for RAG in a variety of industries. Here are just a few:
For example businesses utilize RAG applications to enhance knowledge base queries, allowing employees to rapidly access relevant, domain-specific insights, which boosts productivity and supports informed decision-making.
RAG facilitates real-time information retrieval within enterprise applications, enabling immediate access to critical, up-to-date information, which is essential for operations like risk assessment, financial analytics, and strategic planning.
In customer support scenarios, RAG empowers chatbots to deliver accurate, context-aware answers, substantially enhancing user satisfaction and reducing response times by grounding the LLM in a database of customer support documentation.
For content generation tasks, such as marketing copy or technical documentation, RAG leverages verified sources to ensure the content is factual, consistent, and aligns closely with organizational guidelines.
Why Build a RAG Application on CockroachDB
Unified Storage of Source Data, Metadata, and Vector Data
CockroachDB enables the storage of source data, metadata, and vector embeddings within the same database, significantly simplifying data management, lowering cost, and improving performance for RAG applications. This unified storage approach allows vectors and their corresponding source data to be updated simultaneously, providing immediate, real-time access to the latest information without the delays associated with multi-database architectures.
When vector data and source data reside in separate systems it requires additional pipelines and frequent synchronization efforts. Such systems often suffer from latency and inconsistency, leading to outdated vector indexes, which increases the risk of retrieving and serving stale information. CockroachDB addresses this fundamental limitation by streamlining the data management processes, thus delivering accurate, timely responses in RAG-enabled applications.
Scalability, Reliability, and Simplicity of Operations
CockroachDB is purpose-built to run business-critical applications at scale, providing robust scalability and unmatched resilience, which makes it ideal for powering RAG systems that handle intensive workloads and large data volumes. Trusted by numerous enterprises large and small, CockroachDB's distributed architecture ensures continuous availability by automatically self-healing from hardware failures or network issues, substantially reducing maintenance overhead and operational complexity.
Measure what matters
Traditional benchmarks only test when everything’s perfect. But you need to know what happens when everything fails. CockroachDB's new benchmark, "Performance under Adversity," tests real-world scenarios: network partitions, regional outages, disk stalls, and so much more.
CockroachDB is PostgreSQL-wire compatible, and our VECTOR implementation is compatible with the pgvector extension, making it easier for engineering teams to integrate with existing systems. But by leveraging CockroachDB for vector storage and retrieval, developers avoid the scalability limitations associated with pgvector/Postgres. With CockroachDB’s vector capabilities, you can scale your RAG applications while maintaining consistent performance under increasing load.
Additionally, CockroachDB’s consistency model ensures outdated vectors will not be queried, further enhancing the accuracy of retrieval results. CockroachDB’s Helm chart & Kubernetes Operator seamlessly handles large-scale deployments, making it an ideal backend for powering efficient and reliable vector search functionalities.
Advanced Access Control and Security
As powerful Large Language Models (LLMs) become central to enterprise applications, security and access control become paramount considerations. CockroachDB addresses these concerns comprehensively: Role-based access controls (RBAC) and Row-Level Security, empowering organizations to provide fine-grained user permissions. This ensures that users access only the data they're authorized to view, preventing unauthorized disclosures and enhancing overall data governance. Additionally, CockroachDB has native geo-data placement capabilities to enable data governance and improve performance by keeping data close to the customers that need it. Such precise control mechanisms set CockroachDB apart in securely supporting knowledge bases integrated with advanced generative AI capabilities.
How to build a knowledge base chatbot with RAG on CockroachDB
Building a knowledge based application using RAG on CockroachDB can significantly streamline how enterprises leverage their private knowledge bases, greatly improving productivity across various internal workflows. This chatbot leverages a general-purpose Large Language Model (LLM), significantly reducing the cost and complexity associated with training a domain-specific model, while still maintaining accurate, relevant, and timely responses.
Data flow
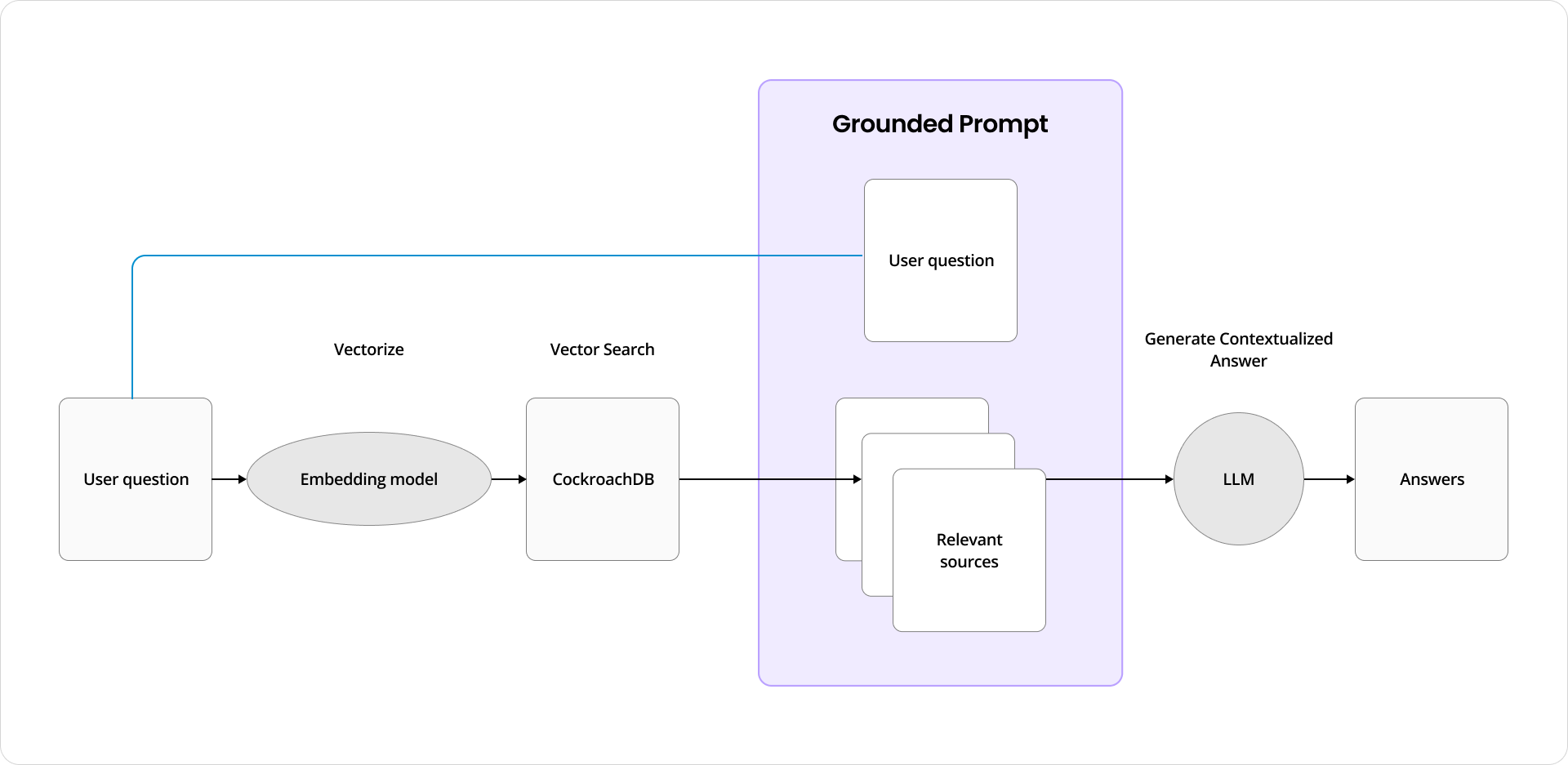
As illustrated in the above flowchart, in this knowledge base chatbot scenario, a user initiates interaction by asking a question. This query is first processed by an embedding model, which vectorizes the question, transforming it into a numerical representation. The vectorized query is then passed to CockroachDB, which houses both the vector embeddings and the source data. Using similarity search capabilities, CockroachDB quickly identifies and retrieves the most relevant content sources.
Once relevant sources are retrieved, they serve as grounded context alongside the original user query. The grounding step ensures the LLM generates context-aware and facts-based responses. This combination reduces the risk of hallucination.
Application architecture
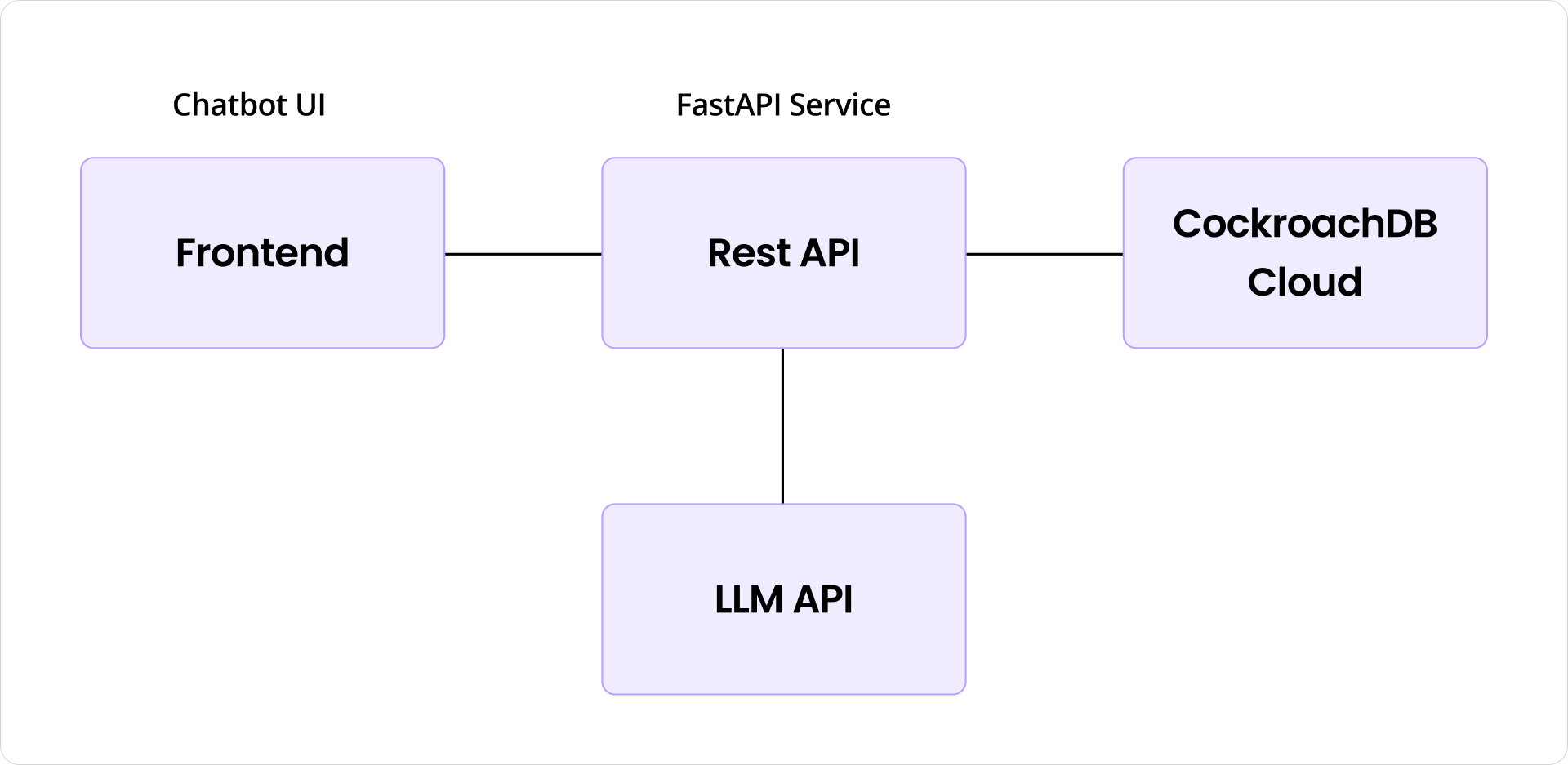
The Retrieval Augmented Generation (RAG) application architecture depicted in the diagram consists of three primary components: a frontend chatbot UI, a FastAPI-based REST API service calling Cockroach Cloud, and an LLM API. The user interacts with the chatbot through the frontend interface, submitting questions or queries. These user inputs are then sent to the REST API service, which orchestrates data processing by communicating with Cockroach Cloud to perform similarity searches and retrieve relevant, grounded information. Next the REST API leverages the LLM API to vectorize the user's query, use contextual prompts to produce accurate, contextually enriched responses. This design enables efficient data management, real-time retrieval, and seamless integration between the database and the generative capabilities of LLMs, providing users with timely, accurate, and reliable information.
Check out a full demo of the chatbot at our YouTube channel:
RAG and CockroachDB: Better Together
RAG enhances Large Language Models (LLMs) by grounding their responses in verified, domain-specific data, thus improving accuracy and reliability, which is often required in many applications, including customer support, content generation, knowledge base queries, and real-time information retrieval.
CockroachDB is an ideal foundation for RAG applications, given its ability to store source data, metadata, and vector data all in the same place. By bringing vector capabilities into a distributed SQL database, you can easily implement AI use cases, simplify database management, and gain the scalability, resilience, and familiarity of a proven distributed SQL database.
To learn more about how you can leverage CockroachDB for your AI applications, contact us! We’d love to hear from you.





