
CASE STUDY
Running a tight Shipt: A distributed payment system designed for correctness
How Shipt built a highly available, distributed payment system on CockroachDB

5K cities covered
120+ retailers
9 members of payment engineering
300K Shipt shoppers
85% household covered nationwide
1-2 million transactions per day
What is Shipt?
In 2014, Shipt was founded in Birmingham, Alabama with a mission to meet consumers’ growing demand for “I-need-it-now” delivery. Fast forward to today: the organization is a leader in same-day delivery space and operates under its parent company Target.
According to Shipt’s website, the company now serves over 5,000 cities across the U.S. and works with over 120 retailers. Aiming to embody “Southern hospitality” meets “Silicon Valley tenacity”, Shipt employs hundreds of engineers to keep up with its growing momentum. It now covers 85% of households nationwide.
As a grocery e-commerce company, Shipt’s suite of payment services are central to its business model. A nine-person Payments Engineering Team is currently responsible for maintaining these payment and order services.
However, a few years ago this team was responsible for building an entirely new distributed payment system from the ground up. The team at Shipt chose to build this system, which is explicitly designed for correctness, on CockroachDB.
“When working with CockroachDB you have to develop a distributed mindset. We knew we wanted to build a multi-region application so we started to ask ourselves, what part of the application layer do we put in the complexity to make this work? But with CockroachDB, the complexity is not in the application layer, a majority of it is handled by the database. This makes it substantially easier to build multi-region services.” - David Templin, Senior Software Engineer
What are the requirements for a “correct” payments system?
Payment systems are notoriously hard to build and come with many challenges. The team at Shipt knew that they wanted to design a multi-region payment service that was designed with “correctness” from the beginning. While having correct payment data might seem like an obvious priority, accomplishing it is much more complicated than it seems, and requires concurrency control, idempotency, state repair, consistency, and more. In order to achieve these requirements, the Shipt team’s first step was to design a basic model of a payment as a state machine and monitor how a payment can transition through various statuses (like authorized, pending, refunded, etc.). From this design, they knew it was crucial to have concurrency control for a distributed system. This means that they could block concurrent requests for the same payment.
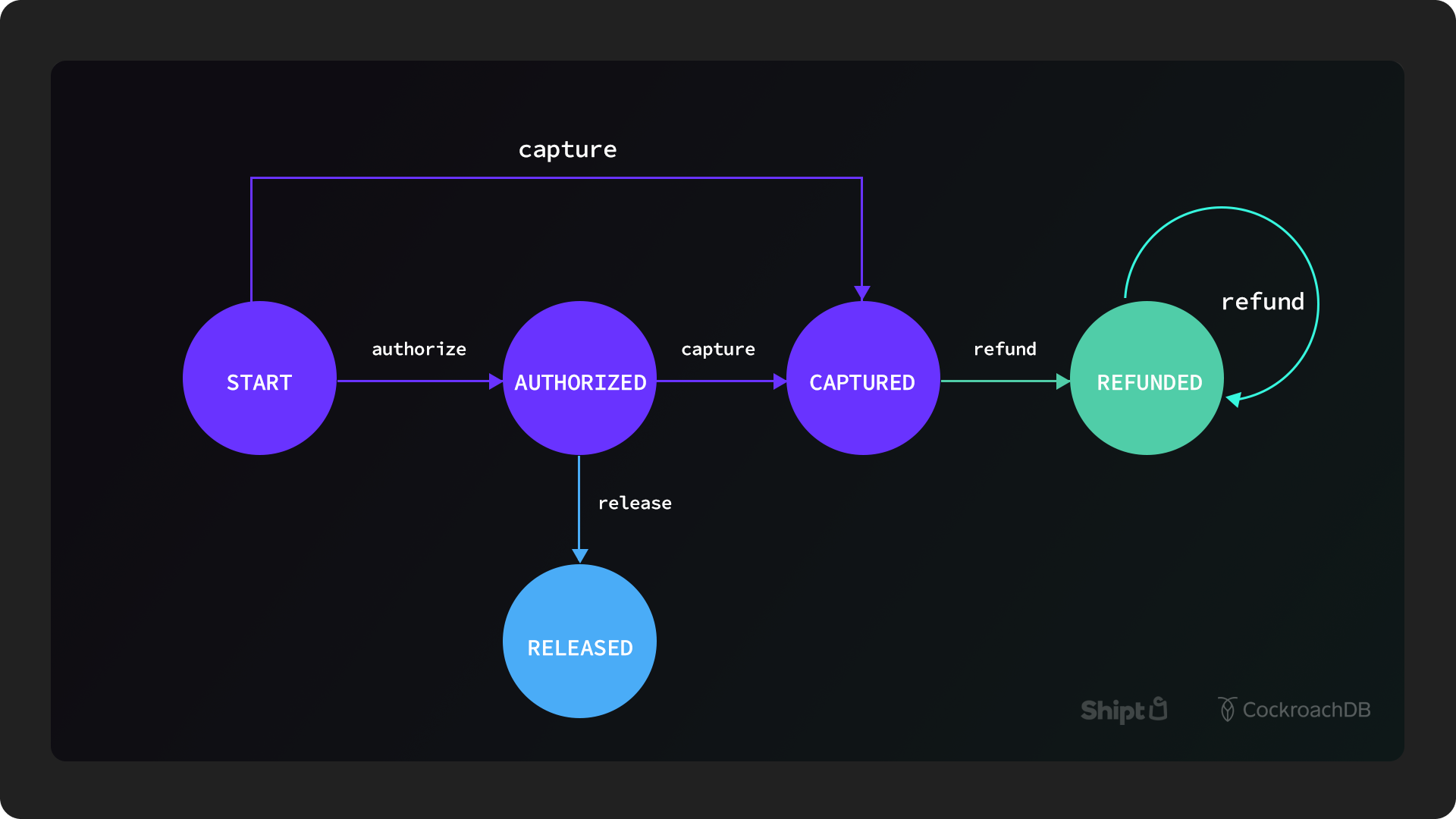
(For the full story of how this works, refer to David’s blog “Designing for Correctness in a Distributed Payment System” Part 1 and Part 2.) They could control concurrency through a traditional relational database management system (RDBMS) like Postgres using an active-passive configuration. However, they were worried about the lag and resiliency of that kind of system. They would be able to design redundancy via replication, but that would sacrifice isolation, which is crucial for payment transactions. Ultimately they wanted their systems to be truly distributed, and adding complexity by retrofitting a legacy RDBMS was not the right solution.
“Incorrect payments can happen all the time. I’ve been in those situations before and they're really painful. I have to go through and audit each one and correct them manually. I really wanted to build a system where I could avoid that. And that’s one of the reasons why we wanted a truly distributed database, not an RDBMS where you basically try to retrofit some replication to it. We wanted a solution that’s fundamentally designed differently where that kind of replication is part of the system from the beginning, and that’s why we chose CockroachDB.” - David Templin, Senior Software Engineer
Since this is a tier 0 service (i.e. essential for operations at Shipt), they needed it to be highly available. The engineers were really concerned about failover time because it could affect hundreds of payments that they would have to go back and manually correct. They knew the best approach to designing a highly available architecture is to distribute data across geographies, which means across multiple regions (at least two).
Ultimately Shipt wanted to simplify building a distributed payment system to the greatest extent possible because designing this type system is already very complicated. To recap, Shipt’s requirements included a database that could deliver:
Resilience via automated replication
High availability with 99.999% uptime
Multi-region and multi-cloud data distribution
ACID transactions to guarantee consistency
Aside from Postgres, the Shipt team considered other distributed databases such as Spanner, Yugabyte, and FaunaDB. Spanner was not the right fit since it would lock them into a single cloud provider and Shipt needed the flexibility to deploy across multiple clouds if they wanted. Yugabyte and FaunaDB were less mature products and lacked some capabilities Shipt required. Then Shipt came across CockroachDB and found it to be the perfect solution to build their truly distributed payment system.
DBaaS for efficient payment processing architecture
Shipt liked that they had the option to choose CockroachDB’s managed offering, CockroachDB Cloud, which reduces manual operations for their relatively small and busy team. And since CockroachDB is cloud-native, they had the flexibility to deploy how and where they wanted. CockroachDB functions as a single logical database meaning you can access the data from any node regardless of location. When it comes to implementing high availability, that’s something CockroachDB does automatically through replication. However, latency can be a factor if the database is not partitioned correctly.
“It’s important to understand that a database like CockroachDB is truly global (depending on your topology), meaning that you can access the data from anywhere and the data is available everywhere.” - David Templin, Senior Software Engineer
Given this notion of automatic replication, Shipt originally set up 12 nodes spread across four regions with a default replication factor of three (and a replication factor of five on new clusters). CockroachDB intelligently spreads incoming data using a consensus protocol based on RAFT (which means you should use a minimum of three regions). There’s also an option to introduce constraints on how you distribute data. Shipt chose four regions (two East and two West) so that they could achieve equal performance in both regions, and partition data to these locations so that a majority of the replications are kept in their respective region. Requests are routed through a database connection pool that uses a load balancer (included with CockroachDB). Shipt’s team can access data via any node that serves as a gateway to the entire database.
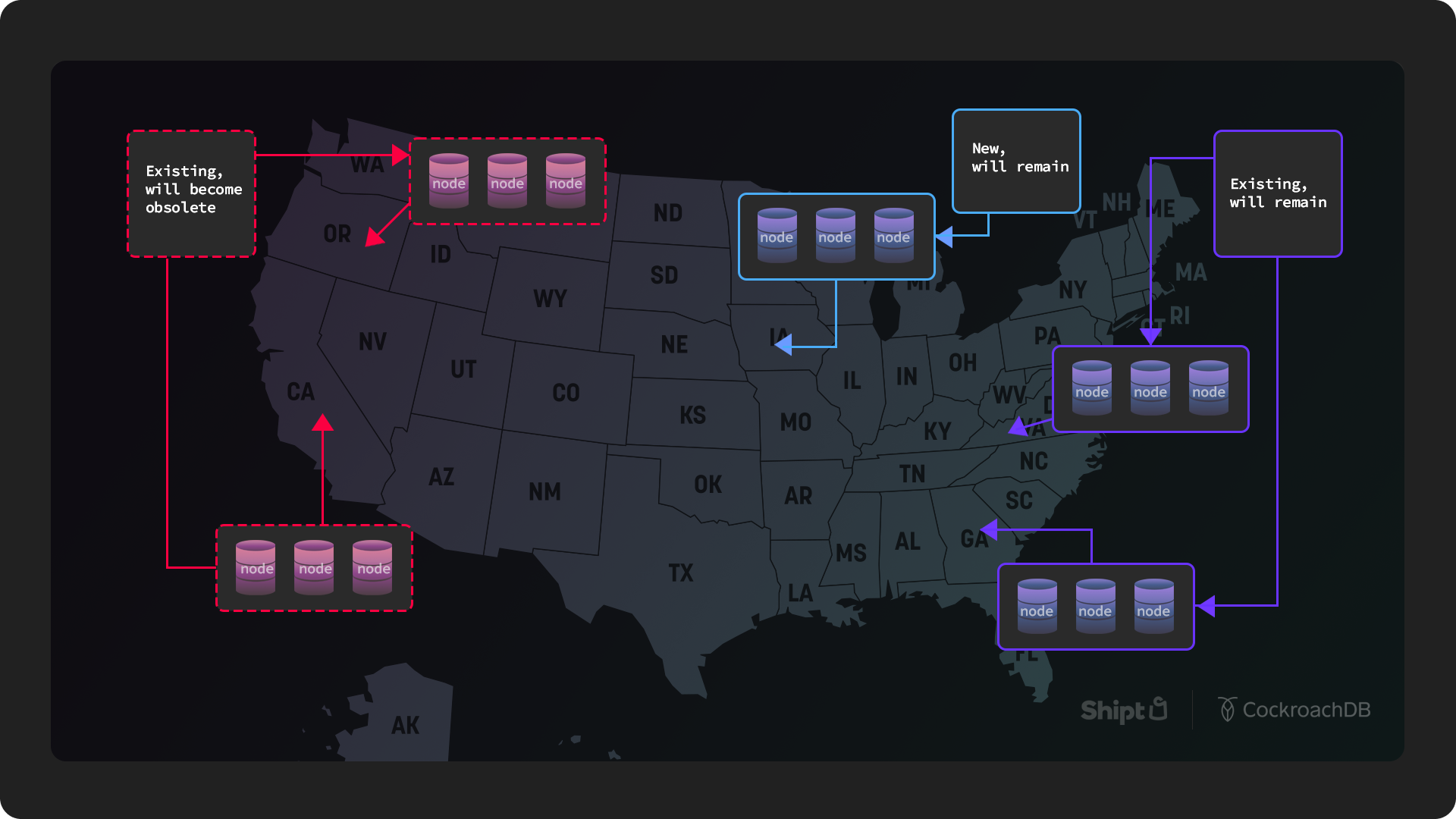
The system is set up to assume that if a payment originates in the East, it will probably complete in the East. When a new payment comes in from the East, it consults the environment and assigns it to the correct partition – in this case, the East. When you commit a transaction, you need confirmation from a majority of those replicas. So if two out of three replications are geographically close to each other, the replication is confirmed pretty quickly. If they are not close, CockroachDB can still confirm the transaction as soon as it gets a response from the nearest replica.
This strategy allows Shipt to reduce transaction latency. The one caveat is that if there’s a failover in one region, payments in that region will be slower. However, that’s a tradeoff Shipt engineers are willing to take since their system achieves 99.999% availability.
With this architecture in place, Shipt is able to process around 1-2 million payment transactions (reads) per day. While this isn’t a huge volume compared to platforms that are processing billions, Shipt wanted to make sure they choose a database that wouldn’t outgrow them. With CockroachDB, they can add more nodes whenever they need and scale the database horizontally.
Idempotency & the correct life of a payment transaction
Now that we’ve covered Shipt’s setup, we’ll talk about how their state representation model for their customer journey works as a transaction flows through their payment service. For this model to work, it’s important to know that CockroachDB allows you to achieve guaranteed atomicity, consistency, isolation, and durability (ACID) all the way down to the row level. For Shipt’s database schema, there are two tables that use the regional tables topology pattern:
payments which includes various attributes (dollar amount, identifier of the charge, etc.) about the payment
idempotency_tokens which includes metadata for a single state transition (i.e. from authorized to captured)
There’s also three tables that use the duplicate indexes topology pattern:
customers
payment_methods
accounts
The idempotency tokens table is crucial since it is used to manage the framework that Shipt built for guaranteeing correctness of the data. This table contains a lot of metadata which is not payment data, but it is related to ensuring transactions process correctly and are not executed more than once. There’s also a mechanism in place that functions as a lock or mutex, and this is included to guarantee the serializable transaction. You read the value of the lock and if it’s unlocked, you write that value is locked, and commit the transaction. There are rare situations where you may forget to unlock, or the system crashes, so there’s an expiring lease on locks (60 seconds by default). Whenever a request is made on a payment, the idempotency tokens table is queried to ask: “is there an active idempotency token in the database for this particular payment?” This can deliver a few results:
No, inactive = the request is processed
Yes, active, locked = the request is rejected
Yes, active, unlocked = the request obtains the lock, completes the operation described by the token, and proceeds to process the current request
Finally, what happens when errors occur? Shipt classifies errors into two categories: determinate errors and indeterminate errors. For example, if they get an error that says “insufficient funds”, that means the card has not been charged and the state transition failed and reverted to the previous state. They’ve implemented a system that forces an operation to complete so it cannot be in an ambiguous state. It either goes back to the original state (as an error or failure) or it goes forward to the intended state. (For in-depth details on how Shipt’s state model representation works, watch this ).
Supporting business growth with resilient, scalable payment architecture
As business continues to boom, Shipt has plans to grow its customer base through new partnerships. They also plan to expand their pay-per-order model, which saw a 25% increase in new customers last year. The payments engineering team is working on transitioning their architecture to a different set of regions while in production. They are finding this process relatively easy since they are using CockroachDB Cloud, and they don’t anticipate any downtime. Shipt’s engineering team recognizes that they are in a sense, fighting the speed of light when it comes to processing payment transactions. Fortunately they’ve implemented a reliable, scalable, and resilient infrastructure to support their initiatives and business growth well into the future.
An engineer from Shipt made an appearence on stage at our annual customer conference to tell a harrowing story about the resilience of the database. Check it out:
