


What do the Uber budget blowout, a 24x token multiplier, and context teach us about building a real business case for AI Agents in production?
Let’s start in April 2026, when Uber's CTO Praveen Neppalli Naga said something every engineering and finance leader building or buying agentic AI should sit with: "I'm back to the drawing board, because the budget I thought I would need is blown away already."
Claude Code adoption jumped from 32% to 84% of Uber's 5,000-engineer org between December 2025 and March 2026. By April, the entire annual AI budget was gone. Monthly API costs per engineer were running between $500 and $2,000. Enterprise AI inference now represents 85% of total AI budgets, and agentic workflows consume 5 to 30 times more tokens per task than a standard chatbot query.
Uber is not a cautionary tale about reckless AI adoption. I've had versions of this conversation with engineering and finance leaders at companies of all sizes this year. The story is almost always the same: The pilot numbers were one thing, and the production numbers were a different animal entirely. What happened to Uber is happening quietly to every organization running agentic AI at scale, because the economics of agents are fundamentally different from every AI pricing model that came before.
This post is about understanding why that is, and what to do about it before your invoice arrives.
Agentic AI economics aren’t just about model pricing. They’re about the total cost of completing a task when an AI agent plans, retrieves context, calls tools, writes state, validates outputs, and retries failed steps.
The pattern extends well beyond one company. In June 2026, OpenAI CEO Sam Altman told CNBC that questions about whether AI spending will ever produce returns are "the most fair criticism right now of AI." He acknowledged that customers are telling him they have burned through their entire 2026 AI budget already, and that cost concerns went from never coming up to the second-most common issue he hears, in a matter of months. When the person selling you the product calls the ROI question fair, the question deserves a serious answer.
Why doesn’t your current AI budget work for agents?
Most teams start by managing the per-token cost of running a model. That assumption held for chatbots, but it breaks for agents.
The per-token cost of intelligence has dropped 98% since early 2024, yet enterprise AI bills are still rising. The reason: A simple chatbot query triggers one inference call, but an agentic workflow, where a large language model (LLM) reasons iteratively, calls external tools, verifies outputs, and self-corrects, can trigger 10 to 20 model calls for a single user-initiated task. That changes the business model: the relevant unit is no longer cost per prompt, but cost per completed task.
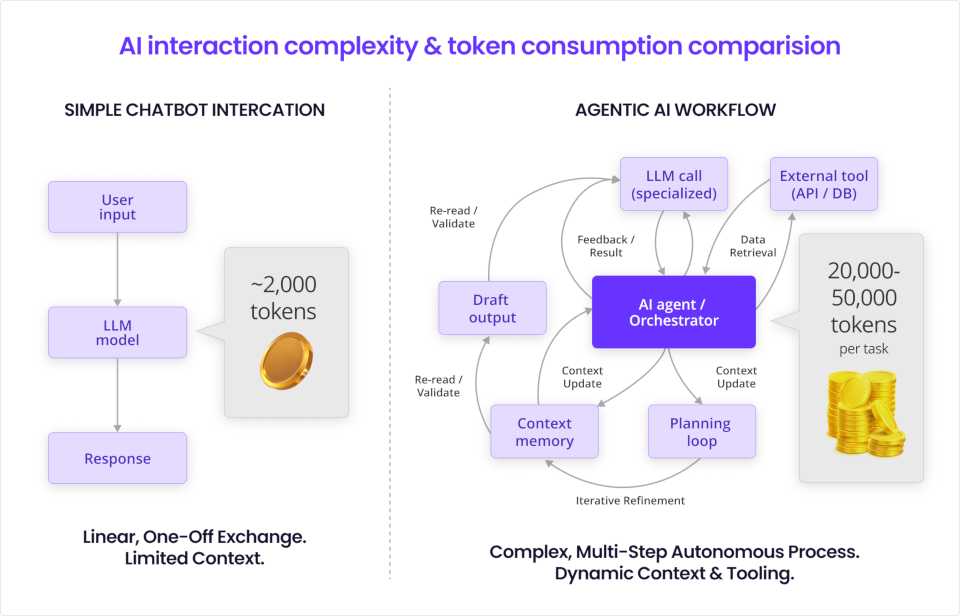
According to Gartner's March 2026 analysis, agentic models require between 5 and 30 times more tokens per task than a standard chatbot. Enterprises that scaled past the pilot phase discovered this multiplier only after their production bills arrived. The pilot economics bore no relationship to the production economics of multi-step agentic loops running thousands of times per day.
RELATED
Altman offered a concrete frame for where this is heading. Six and a half years ago, the top token spender at OpenAI used 100,000 tokens a month. Today, that number is the global per capita average, and OpenAI's current token leader consumes about 100 billion tokens a month, a one million-fold increase in per-user consumption. For enterprise buyers, this is not evidence of healthy demand growth. It is a preview of where every AI program is heading if left unmanaged.
Gartner projects inference on a one-trillion-parameter model will cost 90% less by 2030 than it does today. But cheaper tokens will not produce cheaper enterprise AI bills, because:
agentic models consume far more tokens per task
consumption growth outpaces falling unit costs
providers will not fully pass cost reductions through to buyers
Gartner senior director analyst Will Sommer captured it directly: "Chief Product Officers should not confuse the deflation of commodity tokens with the democratization of frontier reasoning."
What agentic AI costs do teams forget to budget for?
Most teams model LLM inference and call it done, but inference is just the tip of what’s happening. Here are the four layers that actually drive your agentic AI operating costs at scale.
Understanding these layers matters because unmanaged agent costs don’t just inflate cloud or API spend. They also make product margins harder to forecast, make AI ROI harder to prove, and slow the path from experimental agents to production systems that can scale economically.
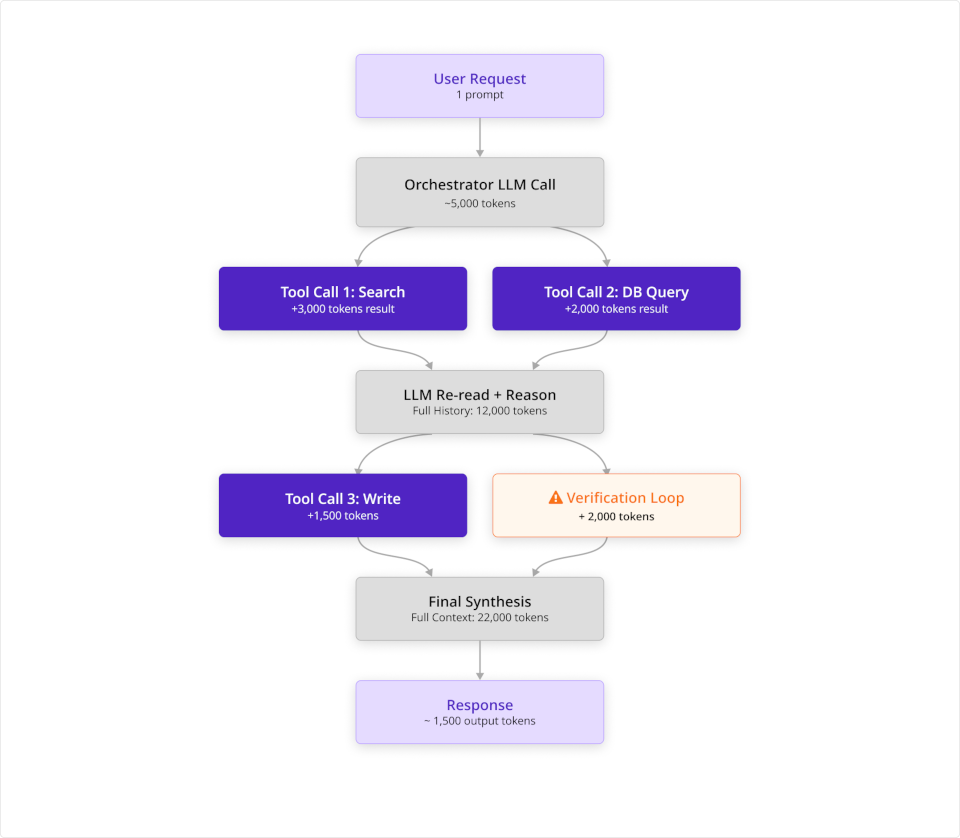
Cost 1: LLM inference and the re-sent context problem
The re-sent context problem is the single biggest invisible cost in agentic systems.
Re-sent context is the repeated transmission of system prompts, tool definitions, skills, instructions, and state history across multiple model calls in the same agentic workflow. In practice, teams often pay for the model to reprocess information it has already seen.
Research from the Stanford Digital Economy Lab (Agentic AI Cost Attribution, 2025) found that re-sent context accounts for 62% of total agent inference bills. Most of what you are paying for is the model re-reading what it already knows.
This applies whether you’re calling a proprietary API or running an open-source model on your own infrastructure. The billing mechanisms are different: proprietary APIs charge per token; self-hosted models charge for GPU compute. But redundant context costs you in either case. A social network running an open-source model for newsfeed ranking cannot absorb per-token pricing at that volume.
The cost shows up as GPU memory pressure, slower inference, and lower throughput per server. A large automotive manufacturing company is using fine-tuned Llama models in their products that face the same re-sent context problem, but it does not arrive as an API invoice. It appears as compute utilization running higher than anyone planned for, or – in a car’s case – slower reaction time.
The pricing below applies to teams using proprietary APIs. For self-hosted deployments on Llama, Mistral, or similar open-source models, the equivalent question is what your inference infrastructure costs per GPU-hour and how many requests you can serve before latency degrades.
This is the current pricing from Anthropic as of May 2026 for organizations using Claude:
These are standard API rates per million tokens as of the current generation, and at first glance they look manageable. According to Ramp's enterprise spending data, the average cost per million tokens across major providers fell from roughly $10 to $2.50 in a single year.
The problem is not unit cost, however: The problem is unit count.
After auditing token usage and routing simpler subtasks to cheaper models, one team cut monthly API costs from $40,000 to $24,000. No product changes. Just routing discipline.
The per-token price matters more in agentic settings than anywhere else. A $0.50 per million input token model and a $3.30 per million input token model look similar in a single-turn setting. Across 15 model calls per user task with accumulating context, that difference is a real unit count economics problem.
Cost 2: Context management and the cost of context rot
What is context rot? Context rot is the degradation in model output quality as context grows longer. Chroma's 2025 "Context Rot" research tested 18 frontier models and found that every single one gets worse as input length increases. Not some or most. All of them.
It’s an architectural limitation, not a bug. LLMs are based on the transformer architecture, which enables every token to attend to every other token across the entire context input for a single API call to an LLM. This results in n squared pairwise relationships for n tokens. As its context length increases, a model's ability to capture these pairwise relationships gets stretched thin, creating a natural tension between context size and attention focus.

Context rot degrades accuracy 30% or more in mid-window positions. It becomes noticeable after 20 to 30 conversation turns, well within typical agentic workflows.
The insight: A one-million-token context window does not solve this. Context rot is not Context Window Overflow, it’s the result of poor context-management decisions.
A larger LLM context window doesn’t automatically solve context rot. Context overflow happens when an input exceeds the model’s limit; context rot happens earlier, when the model still has room but the working context has become too large, noisy, or poorly organized to support reliable decisions.
A model with a 200K token window can show significant degradation at 50K tokens. The decline is continuous, not a cliff.
Anthropic's engineering team puts it well: The challenge is no longer writing the right prompt. It is deciding what goes into context at every step, and what gets left out.
The cost compounds in both directions: You pay for the tokens that degrade your results, then pay again when users retry with different phrasing.
How can you manage context costs? There are four levers available:
Compaction – When a conversation nears the context limit, summarize its contents and restart with the summary. In Claude Code, the agent preserves decisions and outstanding tasks while reducing tool outputs.
Layered tool calling – Every tool schema loaded into context costs tokens before the agent does any work. A flat design with 40 available tools sends all 40 schemas on every inference call, whether the task needs three of them or thirty. The fix is structural: Organize tools into tiers. A coordinator agent holds a small set of high-level tools and discovers which specialized sub-agents to activate based on the task; each sub-agent operates with its own focused schema set. No agent sees more than its scope requires, and tool schema overhead drops proportionally at every layer. This also creates a cleaner governance boundary, because each agent can be limited to the tools, data, and actions required for its specific role.
Just-in-time retrieval – Pull context only when the agent signals it needs it, not upfront. This keeps working context under 8K tokens and consistently improves accuracy.
Sub-agent isolation – When a single agent's context fills with task noise, split the work across sub-agents with clean, isolated context windows. The main agent coordinates at a high level; sub-agents execute and return summaries of 1,000 to 2,000 tokens.
Cost 3: Retrieval costs and the RAG stacks nobody fully budgets
What is RAG? Retrieval-Augmented Generation (RAG) is the standard term for enterprise AI systems that need to work with company-specific documents, databases, and/or knowledge bases. It retrieves relevant content from various data systems including vector databases for semantic retrieval, injects it into the model's context at query time, and generates a grounded response. While the architecture works well, the cost of RAG is systematically underestimated.
The business case for RAG depends on more than whether retrieval improves answer quality. It also depends on whether the retrieval pipeline can:
control per-query cost
keep latency within user expectations
avoid repeated inference caused by incomplete or noisy context
Most managers budget the model API line item and miss the rest of the stack. Here is what the rest typically costs as a percentage of visible inference spend: Embeddings API calls run 3 to 8%. Every retrieval-augmented feature runs embeddings on the query and on the stored documents, and is often billed on a separate line so it disappears from the AI cost conversation. Vector database hosting and queries run 5 to 12%, scale with corpus size and recall strategy, and go up sharply when someone decides to improve retrieval quality.
Current embedding costs (source: RAG Implementation Cost 2026: What You'll Actually Pay for Retrieval-Augmented Generation):
OpenAI's text-embedding-3-small costs $0.02 per million tokens at 1,536 dimensions. Cohere's Embed-4 runs about $0.12 per million tokens.
OSS: Operation/Governance overhead + Infrastructure (GPU’s, CPU’s, and Memory)
Vector database pricing reference:
Weaviate Cloud serverless runs approximately $25 per month for a starter tier; enterprise AI units are priced at $2.64 per unit. Pinecone Starter is free; Standard runs $70 per month and up.
The hidden cost that surprises teams six months in:
When you update documents, you pay for re-embedding and re-indexing, and you should budget 20% of monthly costs for this. Additionally, data cleaning and preprocessing accounts for 30 to 50% of total RAG project cost. Anyone who has tried to build a production pipeline on messy enterprise PDFs, scanned documents, and inconsistent metadata knows exactly why.
The RAG vs. long context trade-off
Million-token context windows have changed the calculus, but not the conclusion, and the trade-off flips with volume. For low-volume internal tools where response time is not a priority, the full cost of running a RAG pipeline (vector database hosting, embedding calls, and retrieval engineering) can exceed what you would pay to send a large context to the model directly. At high query volume the reverse holds: sending a full million-token context on every request costs far more per query than retrieving a few thousand relevant tokens. And for anything user-facing, speed settles it, because processing a full context window on every request is far slower than retrieving a handful of relevant passages.
The "RAG is dead" argument makes good social media. Production data disagrees. Menlo Ventures' enterprise surveys show RAG adoption jumping from 31% to 51% in a single year, and its 2025 report found RAG still the second most common production technique, behind only basic prompt design, while fine-tuning and other advanced methods stayed niche. Grand View Research projects the RAG market will grow from $1.2 billion in 2024 to $11 billion by 2030, with legal, compliance, and customer support among the leading application areas. The table below shows when each approach wins.
When to use RAG, when to use long context:
In RAG pipelines, noisy embeddings can reduce accuracy, increase inference retries, raise token consumption and cost of fixing the embeddings. Data quality upstream is a cost control lever, not just a quality concern.
Cost 4: Orchestration, tooling, and the hidden 80%
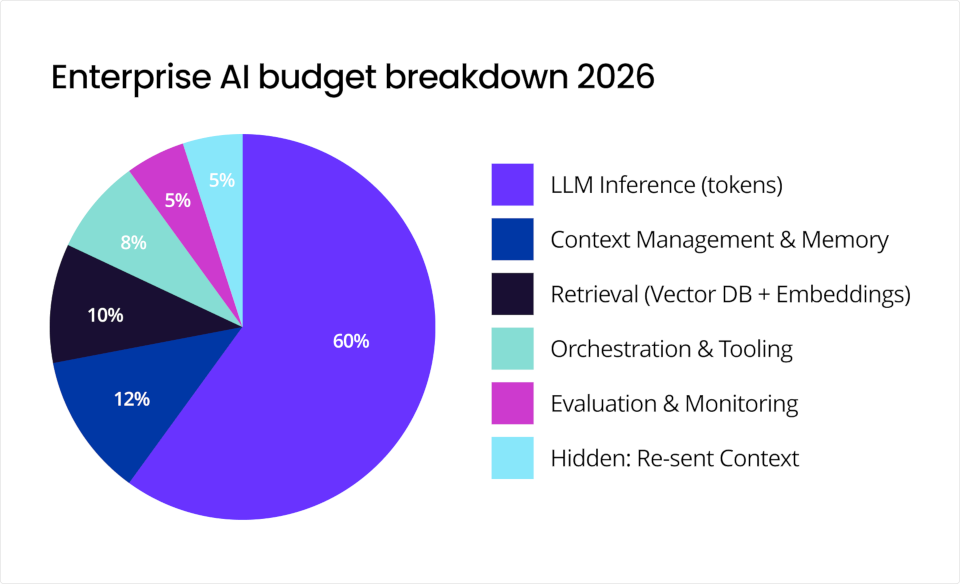
Agentic AI costs are routinely underestimated because leaders focus on model inference. In practice, inference represents only about 20% of total cost of ownership (TCO). The majority lives in what surrounds the model and shows up after deployment, not before.
Here’s what’s in that other 80%:
Orchestration layer (planning, retries, tool use, state management): This vital layer includes licensing, infrastructure, and engineering costs.
Evaluation and monitoring: Every iteration of an agentic workflow demands rigorous validation to ensure accuracy across diverse inputs. Absent specialized tooling, this burden shifts to manual human review or "LLM-as-a-judge" scoring using frontier models like GPT-4, which can cost $0.01 to $0.10 per evaluation. High-performing production agents often undergo over 100 testing cycles, potentially driving validation spend into the thousands for even modest projects.
Governance and compliance: Agentic AI increases exposure to hallucinations, unintended actions, security threats, and regulatory risk. Mitigation efforts require audit logs, human-in-the-loop controls, monitoring tools, and policy enforcement. Governance costs can significantly increase TCO, especially in regulated industries.
Runaway loops: Autonomy is the main cost amplifier of agentic AI. The primary drivers of runaway spend are uncontrolled retries. Instead of endless retries, escalate to humans once defined thresholds are reached.
What unmanaged agentic costs actually look like:
Peter Steinberger the creator of OpenClaw (now owned by OpenAI) spent 1.3 million dollars over 30 days (he used Fast Mode which does increase the cost by a significant amount)
A single user consumed 10 billion tokens over eight months on a $100 per month plan.
A healthcare company running three AI agents saw monthly inference costs jump from $12,000 to $68,000 in six weeks. The model was not the problem. A retrieval fault in one agent had started pulling documents eight times larger than the task required. No individual log flagged it. The issue only appeared through unified telemetry across all three agents, two weeks after it had already hit the invoice.
The highest-return move: Prompt caching
Of all the levers available, prompt caching delivers the highest return for the least implementation effort. Start here.
Prompt caching is the highest-return first move to reduce agentic AI costs. On Anthropic's platform, cache reads on Claude Sonnet 4.6 cost $0.30 per million tokens against a standard rate of $3.00, a 90% reduction on every token that hits the cache. Break-even lands at 2.3 reuses of the same cached prefix within the one-hour TTL window. Any workload where the same system prompt or tool definitions are sent more than twice per hour is already in the money.
This is the trap that kills cache performance:
Timestamps and session IDs in the prefix destroy cache performance. Injecting something like "Today is March 6, 2026" into a system prompt invalidates the cache every day. Use a precise timestamp and it invalidates on every request. One team enabled prompt caching on a RAG endpoint with 60,000 tokens of system prompt and reference docs. Production day one came back at a 1% discount instead of 90%. The cause: their system prompt opened with today's date. One line. Zero cache hits, all day.
In OpenClaw GitHub issue #19534 (February 2026) a user filed a bug report showing their full 170,000-token context was being fully reprocessed on every request at standard pricing because a "Current Date & Time" field in their system prompt changed on every turn. Cache reads were at zero. Costs were running 10x higher than expected.
LangChain's create_react_agent injects dynamically generated unique IDs into serialized messages. Even when the developer's prompt is identical across calls, the cache hit rate lands at 0% because the IDs change. This took significant debugging to find, because the framework does not document this as a caching concern.
Practical implementation:
# Structure prompts with static content FIRST for maximum cache hits
# Dynamic content goes at the END
messages = [
{
"role": "user",
"content": [
{
# Static system context — cache this
"type": "text",
"text": SYSTEM_PROMPT + TOOL_DEFINITIONS + COMPANY_CONTEXT,
"cache_control": {"type": "ephemeral"} # Anthropic: cache this prefix
},
{
# Dynamic per-request content — always fresh
"type": "text",
"text": f"Task: {user_task}\nSession state: {current_state}"
# NO timestamps or session IDs here unless truly needed
}
]
}
]
Do not put the following attributes in the cached prefix:
Current timestamps (unless day-level granularity is acceptable)
Session or request IDs
Dynamically discovered tool registrations (via MCP)
User-specific personalization data that changes per call
Real savings at scale: one enterprise case study showed processing 50,000 documents per month cost $8,000 with caching, versus $45,000 without, saving 82% on costs.
What does the Uber AI budget story actually teach?
The Uber story is a cautionary tale, and it stems from a measurement failure.
CTO Praveen Neppalli Naga confirmed that the full annual AI budget was exhausted by mid-April. Not because agents were ineffective, but because nobody evaluated their effectiveness before consumption went parabolic.
Similarly, Microsoft has pulled back thousands of internal Claude Code licenses, shifting developers to GitHub Copilot CLI to control costs. They’re not doing this because the tools stopped working, but because usage grew faster than the value being captured from it. Both Uber and Microsoft are now applying the same test: Keep AI where the productivity improvement is demonstrable, tighten controls everywhere else.
Even well-capitalized companies are not immune. Cursor operates at deeply negative gross margins because API costs scale faster than subscription revenue. They won on product first, then discovered the true cost structure. Most enterprise teams cannot afford that sequence.
The broader pattern is consistent: Deloitte's 2025 AI enterprise survey found that fewer than a third of organizations could clearly attribute AI spend to measurable business outcomes.
Altman was direct about this in June 2026. Speaking on CNBC about what he hears from enterprise customers: "I know some great stuff is happening, but I know there's a ton of waste… How long do I have to wait for it to really show up in revenue?" His answer was a year or two. For finance leaders trying to close books quarterly, that is not an actionable timeline. The measurement discipline has to come from inside the organization, because it is not coming from the vendor.
Gartner's 2026 AI Hype Cycle report forecasts 40% of AI agent projects will be cancelled by 2027 due to cost overruns alone, not technical failure, not market fit. Just economics.
Uber's COO said in May 2026, "It's very hard to draw a line between one of those stats and, 'Okay, now we're actually producing 25 percent more useful consumer features.'" That’s the question: Not whether employees are using AI, but whether that use is producing improvements customers can actually feel.
The organizations that stay out of that 40% were disciplined. They:
modeled cost before they deployed
built usage dashboards alongside the product
measured output rather than consumption
RELATED
The State of AI Infrastructure 2026 — Based on new global research surveying 1,125 engineering leaders, this report reveals how close organizations are to hitting their infrastructure limits. Learn why AI scale is becoming a defining risk for reliability, performance, and cost in 2026.
What AI agent costs truly matter?
An analysis of 23,000 GPU clusters across thousands of companies found average GPU utilization at just 5%. Most provisioned AI capacity is sitting idle while teams simultaneously burn through operating budgets on the capacity they do use. That gap is a measurement problem before it is a cost problem.
The right metric is value per 1,000 tokens. Pick a business denominator: tasks completed, tickets resolved, revenue touched. If that number is flat or falling while consumption grows, the economics are running in reverse.
Do not view token consumption as a proxy for adoption success. When consumption becomes the measure of adoption, the organization has built a machine that optimizes for its own bill. Meta learned this at 85,000 employees, when leaderboard-ranked staff started leaving agents running for hours with no task to improve their standing. The fix is to track what users produce, tasks completed, tickets resolved, code shipped, rather than what they consume.
Key tracking metrics:
RELATED
Built for AI: Scaling IAM, Metadata Management, and Vector Search on One Database – This guide shows how leading AI companies unify transactional data, vector embeddings, and agent state on a single distributed SQL platform, eliminating the infrastructure fragmentation that drives retry-driven costs.
What infrastructure decisions compound AI agent costs?
There is one infrastructure choice that compounds every cost decision above: where your agents read and write state.
In production AI agent architecture, the database is part of the agent’s control loop. It affects how quickly the agent can retrieve context, commit state changes, coordinate concurrent work, and recover from failures.
Agents in production aren’t just calling models. They are reading from databases to pull context at each step, writing state after each tool call, coordinating across concurrent sessions, and retrying when operations fail. A database that introduces latency on any of those paths creates a problem, by multiplying directly into token consumption.
Here is the typical agent’s retry mechanism:
When an agent's tool call to a database times out or returns stale data, the agent retries.
Each retry re-sends the full conversation context plus a new tool invocation.
A three-retry pattern on a single database read triples the token cost for that step.
Across thousands of daily agent sessions, this stops being a rounding error and starts showing up as a budget line item with no obvious cause.
Agents do exactly what they are designed to do, retry, when reading from a database that’s returning inconsistent or unexpected results like:
schema mismatches
stale reads under concurrent load
query timeouts;
Each retry re-sends the full conversation context. As Seemore Data explains in its analysis of agentic data stack costs, agents may retry when a query returns unexpected results, hits a schema mismatch, or times out, and each retry can create another compute charge. A single task that hits data-layer edge cases can generate repeated tool calls before it resolves. The agent may be behaving exactly as designed; the cost problem often comes from unreliable or inconsistent state access. Improving consistency, latency, and observability at the data layer reduces the conditions that cause retry-driven spend.
The question for agentic workloads is not which database is cheapest to run. It is which database keeps latency low and state consistent under the specific read/write mix that agents create:
high-throughput reads during retrieval
transactional writes when agents update records
parallel sessions from multiple agents working simultaneously
This is the design problem CockroachDB is built for: distributed, transactional, consistent under concurrent load. Get the database right, and the optimizations we discussed here compound further. Get the database wrong, and you will spend months chasing puzzling token overages.
Enterprise AI budgets will keep growing. The gap between organizations that treat agent costs as an engineering problem and those that treat them as a subscription line item is widening quickly. The first group spends 60 to 70% less for equivalent output. The second keeps getting surprisingly high invoices.
The durable advantage will go to teams that can scale AI agents without letting cost growth outrun business value. That requires measuring outcomes, controlling context, reducing retries, and designing infrastructure for predictable agent execution.
The token is not the unit of value. The task outcome is. Build the measurement system around outcomes and the token costs follow from there.
If your team is building or scaling AI agents in production and the numbers aren’t adding up, let’s have a conversation. The patterns above come from real deployments, some working well and some still working through the same issues as Uber. You can reach me directly on LinkedIn.
To see how CockroachDB meets the consistency and latency requirements of agentic workloads, start with our technical docs: cockroachlabs.com/docs
Try CockroachDB Today
Spin up your first CockroachDB Cloud cluster in minutes. Start with $400 in free credits. Or get a free 30-day trial of CockroachDB Enterprise on self-hosted environments.
Quentin Packard is VP of Americas Sales at Cockroach Labs, where he works with engineering and infrastructure leaders building production-grade agentic AI systems. He previously helped build Splunk’s observability business and has worked across infrastructure automation, secrets management, and real-time data governance at HashiCorp and early stage startups. His writing draws on direct conversations with enterprise teams navigating AI and data architecture in production.


